Компьютерные науки : Реферат: Алгоритмы и структуры данных. Программирование в Cи
Реферат: Алгоритмы и структуры данных. Программирование в Cи
МИНИСТЕРСТВО
ОБРАЗОВАНИЯ РОССИЙСКОЙ ФЕДЕРАЦИИ
ТУЛЬСКИЙ
ГОСУДАРСТВЕННЫЙ ПЕДАГОГИЧЕСКИЙ УНИВЕРСИТЕТ
ИМ. Л.Н.
ТОЛСТОГО
Кафедра
иностранных языков
РЕФЕРАТ
на право
получения допуска к сдаче кандидатского экзамена
по
иностранному языку
Тема: “Алгоритмы
и структуры данных. Программирование в Cи”
Гордеев Вячеслав Валериевич, аспирант
кафедры информатики и вычислительной техники
ТГПУ им. Л.Н. Толстого
Материалы реферата: Grundlagen Computernetze, Prof. Jürgen Plate, FH
München, FB 04, http://www.netzmafia.de/skripten/ad/index.html. р. 232.
Дата сдачи:
апрель 2004 г.
Тула - 2004
Введение
Данная книга написана
профессором Мюнхенского университета Юргеном Плате. Она входит в серию книг,
посвященных информационным технологиям, которые выходят в рамках проекта «Netzmafia». Книга посвящена одному из главных
разделов информатического образования - алгоритмизации и программированию и
адресована тем, кто желает познакомиться и окунуться в мир алгоритмов и разработки
программ. Она состоит из двух достаточно подробных лекций по темам «Алгоритмы и
структуры данных» и «Программирование». В книге вводится понятие алгоритма и
рассматриваются все необходимые понятия, связанные с алгоритмами. Затем
обсуждаются принципы написания алгоритмов и составления программ на языке
программирования Си.
Си – это структурный язык
программирования высокого уровня, созданный в 1972 году Керниганом и Ритчи. Он
создавался как язык для разработки операционной системы UNIX. Cи позволяет
работать с данными практически так же эффективно, как на ассемблере (машинном
языке), предоставляя при этом структурированные управляющие конструкции и
абстракции высокого уровня (структуры и массивы). Именно с этим связана его
огромная популярность и поныне. При этом компилятор C очень слабо контролирует
типы, поэтому очень легко написать внешне совершенно правильную, но логически
ошибочную программу.
Во введении Юрген Плате
кратко рассказывает о структуре книги. Она состоит из двух основных частей
основных понятий алгоритмизации и основ программирования. Обе части достаточно
тесно взаимосвязаны, так как при изучении основных понятий приходится прибегать
к примерам решения задач на конкретных языках программирования, а при изучении
программирования необходимо постоянно помнить основы алгоритмизации.
Автора побудило написать
эту книгу ситуация, которая сложилась в мире создания программного обеспечения.
Несмотря на то, что в последние годы в методике создания программного
обеспечения сделан большой прогресс - появилась дисциплина программная
инженерия (техника программного обеспечения), многие разработчики недостаточно
квалифицированны в этой области. Поэтому необходимо лучше обучать искусству
программирования. И эта книга в удобной форме излагает основные приемы
программирования, что сопровождается большим количеством примеров на языке
программирования С.
Каждый программист должен
выполнять ряд правил при написании программ:
- Основательно подумать перед тем, как
нажимать на клавиши.
- Иметь собственный стиль
программирования.
- Научиться обращаться с подводными
камнями и с небрежностью языков программирования.
- Выполнять множество упражнений для
достижения результата.
1. Данные и алгоритмы
В этой главе автор собрал
основной теоретический материал по алгоритмизации. Здесь представлен общий
обзор как программного, так и аппаратного обеспечения. Но основной упор
естественно делается на понятие алгоритма, способы записи алгоритмов, методы и
этапы составления программ.
В этом параграфе профессором
рассматриваются следующие вопросы:
- Что такое "информация"?
- Что являются "сообщением"?
- Как информация передается?
- Как информация представляется?
Наряду с энергией и
материей, информация – это базовое понятие универсального значения. В
информатике понятие информации несколько отличается от обыденного. Информация
это знания о чем-либо. Сообщения служат для отображения информации.
Объем информационного
сообщения фиксируются, определяется количеством решений в сообщении и
измеряется в битах.
После абстрактной
информации автор переходит к конкретному отображению информации, сообщений. Для
этого он приводит несколько определений:
- Сообщение - набор символов для информационной
передачи.
- Символ - элемент символьного запаса,
установленной конечной массы различных символов.
- Алфавит - упорядоченный набор символов.
- Слово - последовательность символов,
которые рассматриваются в определенной связи в качестве единой величины.
Физически сообщения могут
представляться через сигналы. При этом различаются аналоговые и цифровые
сигналы. При аналоговых или непрерывных сигналах идет непрерывное распределение
физической величины к объему информации сообщения, а при цифровых (дискретных)
сигналах имеется только конечное число возможных состояний физической величины.
Цифровая техника работает обычно с двумя значениями сигнала – 0 и 1.
Этот параграф Плате
начинает с объяснения понятия алгоритм. Автор говорит о том, что алгоритмы
должны разрабатываться не для специальных целей, а содержать шаги, которые
нужно применять при решении определенного класса проблем, а не для отдельного
примера.
Программа - это описание пути,
исходя из определенных входных данных, к определенному результату или метод
получения решения.
Отсюда выделяют следующие
свойства алгоритмов:
1.
Полнота описания. Должна быть показана полная
последовательность действий. Ссылки на неизвестную информацию должны отсутствовать.
2.
Повторяемость алгоритма. Алгоритм можно
повторять сколь угодно часто и каждое повторение должно приносить при равных
входных данных равный результат.
3.
Корректность
алгоритма. На
практике корректность нужно подтверждать. Поэтому используются тесты, при
которых уже известен для заявленных входных данных результат, и сравниваются
затем данные с результатами.
4.
Эффективность
описания и исполнения алгоритма.
После описания свойств
необходимо дать достаточно краткое определение понятия алгоритм:
Обрабатываемое предписание
называется алгоритмом, если оно имеет следующие свойства:
1.
Предписание
описывается конечными средствами.
2.
Оно однозначно
установленным способом для введенных данных выдает точный результат.
Далее Юрген Плате говорит
о том, что программа состоит из конечного числа шагов и приводит конкретные
примеры, наглядно это обосновывая. Для написания программ необходимо
использовать особенные языки. Языки программирования - это нормированные
языки, которые служат для описания инструкций обработки, структур данных, а
также ввода и вывода данных.
Необходимо
преобразовывать алгоритм всегда таким образом, чтобы выделять в нем
"подалгоритмы". Теория разработки программного обеспечения
основывается на этой идее. Сложные и комплексные структуры и виды деятельности
реализуются известными структурами и более простыми подалгоритмами. Разработка
и составление алгоритмов превратится в конструирование из готовых алгоритмов.
Простейший язык
программирования состоит из системы команд. Это - встроенные команды,
они сравнимы с командами микрокалькулятора, которые вы вызываете, нажимая
клавиши. Этими командами можно выполнять арифметические операции и хранить
результаты действий.
Если каким-то образом
нумеруют команды, то получают машинный язык. Это самый простой
программистский код. В этом коде номер команды может использоваться как ее имя.
Программа на машинном языке является ничем иным как длинной последовательностью
таких слов кода.
Программировать на языке
машин достаточно трудно. Поэтому стали переводить коды компьютеров в сокращения
незашифрованного текста. Соответствующие переводческие программы, которые
называют ассемблерами, были разработаны для всех компьютеров.
Программа на языке
ассемблера - это последовательность команд, которые состоят из 2-4 букв и к
которым прибавляются адреса ячеек памяти. Например, команда ADD R2, R6
складывает содержимого ячейки памяти R2 и содержимого R6 и сохраняет сумму в
R6.
Однако со временем
недостатки программирования на ассемблере становились все более очевидными:
зависимость от модели компьютера, изобретение различных «трюков» в связи с
ограниченными возможностями языка, трудность исправления ошибок, неудобная
форма работы для человека. Это вело, в том числе, к развитию так называемых
"более высоких языков программирования", которые более удобны для
человека.
В следующем параграфе автор
рассказывает о программах перевода с машинного языка в более удобную для
человека форму – интерпретаторах и компиляторах. Эти программы переводили различные
последовательности букв в форму, которую может понимать компьютер. Вместе с тем
программы могли писаться на языке, который состоит из слов разговорной речи.
Кроме того, значительно упрощается поиск ошибок при программировании.
В этом разделе автор исследует,
какие свойства должны иметь языки, которые используются для описания алгоритмов
(алгоритмические языки). Речь идет о нормированных языках, которые
служат описанию алгоритмов. Здесь Юрген Плате отвечает на 2 основных вопроса:
·
Как можно
нормировать язык?
·
Что требуется для
описания алгоритмов?
В результате нормирования
естественного языка от многих вариаций сочетания остается только лишь
единственная версия и сокращения с перестановками больше не допустимы.
Однако, алгоритмический
язык не обходится одними символами, также необходимо давать имена величинам и происходящим
действиям.
"Более высокие"
языки программирования как, например, BASIC, FORTRAN, Pascal или C
разрабатывались, чтобы облегчить решение различных задач. Автор описывает
разработчиков и назначение данных языков и особо останавливается на языках Pascal
и C.
Прежде чем писать
программу, необходимо иметь алгоритм для решения задания. Алгоритм резюмирует
все шаги, которые нужно пройти на пути к решению. Он представлен таким образом,
что может образовывать основу для программы, но еще не формулирует ее на языке
программирования. Хороший программист может перенести алгоритм без труда из
разговорной речи в любой язык программирования. Для начинающего "нечеткость"
разговорной речи представляет напротив большую проблему.
В этом параграфе автор
рассказывает о самом важном этапе создания программ - целях программирования:
зачем и почему программное обеспечение должно создаваться и что должно уметь
делать. Имеются минимум 2 участника процесса создания ПО: клиент и разработчик.
·
Первый шаг - это
запись требований клиентов. Разработчик пытается уловить необходимые для
создания программного обеспечения связи и отбросить несущественное.
·
На следующем шаге
разработчик предстает в роли дизайнера. Подобно архитектору он создает структуру
программного обеспечения.
·
На 3 этапе он
играет роль программиста.
·
На 4 этапе клиент
испытывает программное обеспечение и рассчитывается.
Самая важная фаза при
составлении алгоритма - это анализ постановки проблемы и размышление о решении.
Эта часть требует больше времени, чем собственно работа с каким-либо языком
программирования.
В программировании необходимо
заменять вербально представленный алгоритм командами языка. При этом проходят
такие этапы, как кодирование, ввод данных, перевод и тестирование. Компилятор
помогает нам находить синтаксические ошибки, однако логические ошибки в
программе можно узнавать только с помощью размышлений и письменных тестов.
В этом параграфе Юрген
Плате обращает внимание, что команды программы состоят из четырех основных
структур: последовательностей, выбора, повторения и подпрограмм.
Последовательность - это набор команд, которые
запускаются в очередности их записи. Поэтому говорят также о линейной
последовательности и повторяющейся последовательности.
Выбор обозначается нелинейной
последовательностью с ветвлением. Выбор пути решения зависит от условия.
Структура повторение
получается, если последовательность команд должна повторяться неоднократно для
решения задания. Минимум одна команда должна заботиться о том, чтобы после
конечного числа прохождений не было больше выполнено условие повторения.
При написании программы
желательно разбиение ее на модули. Во всех более высоких языках
программирования эта возможность реализована в форме подпрограмм. За
применение подпрограмм говорят следующие причины: наглядность, экономичность, возможность
быстрого внесения изменений.
Затем автором
рассматриваются основные способы представления алгоритмов: вербальное описание,
графические способы представления (логическая схема программы и структограммы).
В этом параграфе
профессор рассказывает о причинах появления новой дисциплины в рамках информатики, а также
пытается определить область ее применения.
Основной причиной
появления новой дисциплины является невозможность полностью устранить ошибки
программирования. В рамках дисциплины «Разработка программного обеспечения» разрабатываются
модели и методы, с помощью которых даже самые большие программные системы могут
работать безошибочно.
Важнейшими критериями
здесь являются: надежность и корректность, удобство и гибкость (возможность
быстрых изменений в программе) работы, удобочитаемость программного кода,
эффективность создания и применения.
В этом параграфе
достаточно подробно рассматриваются теоретические основы разработки ПО и особое
внимание уделяется подготовке, анализу проблемы и постановке задач
программирования.
В этом разделе автор рассказывает о
том, что дисциплина разработки программ сформировалась наряду с проблемно-ориентированным
программированием. При этом сначала определяется структура данных для каждого
обрабатываемого объема данных. Затем устанавливают, какие виды связей между ним
существуют.
Огромное значение здесь
имеют типы данных, а также их значения и свойства. Тип переменных величин
характеризуется диапазоном принимаемых значений. В каждой программе
договариваются о имени и типе переменных.
Помимо переменных автор
упоминает и о константах, значения которых могут непосредственно вноситься в
структуру программы.
Каждая переменная
характеризуется своим именем и значением. Особое внимание Плате обращает на
различие между распределением значений и уравнением в математическом смысле.
Таким образом, математическое уравнение X = X + 1 не имеет решения, а в языке
программирования эта запись значит, что “прибавляют 1 к значению X и сохраняют
результат снова в X " или короче "Повышают X на 1".
Автор объясняет также, из
чего состоят выражения в языках программирования. Это формулы, которые всегда дают
какой-то результат и состоят из операндов (константа, переменные величины и
функции) и операторов (однозначных и двузначных).
Далее автор подробно
останавливается на стандартных типах данных, которые используются во всех
языках программирования:
·
Boolean – логический тип (принимает значения
True или False).
·
Integer – тип целых чисел.
·
Character – символьный тип.
·
Real – тип действительных чисел.
Также он рассматривает
структурные типы данных:
·
Feld (Array) - Поле (массив). Переменные
величины этого типа содержат множество элементов одинакового стандартного типа.
·
Record (Structure) – Записи (связи). Содержат
элементы различного типа и имеют каждый свое имя.
В заключении обзора
рассматривается общий тип данных – файлы. Они состоят из большого
количества данных различных типов. Вместе с данным типом определяется несколько
стандартных операций: открытие и закрытие доступа к файлу, чтение из файла и
запись данных в файл.
Профессор определяет данное в заголовке
понятие так:
Качество программного
обеспечения - это
совокупность признаков и значений программного продукта, которые необходимы для
нормального функционирования программы и удовлетворения потребностей пользователей.
Плате выделяет следующие
признаки ПО, которые определяют его качество:
1.
Функциональность
2.
Надежность
3.
Пригодность
к употреблению
4.
Эффективность
5.
Изменчивость
6.
Переносимость
Для того, чтобы создать
качественный программный продукт автор говорит о необходимости выполнения ряда
действий:
1.
Тестирование
ПО
Тест «письменного стола» – в
соответствии с поставленной задачей необходимо выбрать входные данные и
рациональный ход решения.
Тест «черного ящика» – функциональный
тест, который рассматривает алгоритм в качестве черного ящика, в который
нельзя заглянуть (проводит обычно покупатель).
Тест «белого ящика» – он
предполагает, чтобы входные данные были подобраны так, чтобы алгоритм
выполнился хотя бы один раз.
2.
Проверка
подлинности ПО - это
комплекс мероприятий, направленных на безупречное функционирование программы
при любых входных данных, которое показывается с помощью математического
аппарата.
3.
Тестовое
планирование и тестовая документация. Так как достаточно часто тестирование проходит непродуманно
и внепланово, то необходимо составлять план тестов и протоколировать ход
тестирования, чтобы исключить появление других ошибок в программе.
Таким образом, разработка
ПО включает в себя следующие этапы:
1.
Интуитивная
разработка алгоритмов.
2.
Формализация
алгоритма, математическое описание.
3.
Изображение
алгоритмов структограммой. Разделение на модули и подпрограммы.
4.
Разрабатывают
алгоритмов с помощью языка программирования высокого уровня.
5.
Кодирование.
2. Структура программы
Прежде чем приступать к
программированию, автор обосновывает выбор в качестве изучаемого языка
программирования - языка С.
Язык C был первоначально разработан
как расширение для операционной системы UNIX, но впоследствии превратился в
стандартный ЯП для разных платформ. Этому способствовало:
-
богатство
операторов,
-
относительная
машинная независимость,
-
возможная высокая
мобильность,
-
небольшой
языковой объем (только 32 ключевых слова),
-
много
синтаксических возможностей в комбинации с упрощенными стилями.
В этой главе автор
знакомит нас с основными синтаксическими единицами языка С:
n Набор символов С-программы – это буквы, цифры,
знаки, а также некоторые специфические элементы (пробел, предупреждение,
возврат, табуляция)
n Разделители – пробелы, табуляторы, конец строки,
перевод страницы, комментарии служат для разделения основных элементов языка
n Директива компилятора #include
подключает к компилятору файлы.
n Функции - из них состоит вся программа. Для
каждой программы главной является функция Main, которая начинается с "{" и оканчивается
"}".
n Стандартные библиотеки - стандартные функции
предоставляются стандартными библиотеками.
n Ключевые слова имеют предопределенное значение, которое
не может изменяться.
n Идентификаторы и имена – все объекты C
имеют идентификаторы, которые состоят из последовательности букв, цифр или
подчеркивания.
n Escape-последовательности – с помощью них записываются
непечатаемые символы через "\".
Автор знакомит нас с
первой нелинейной структурой. Структура If…Else означает ветвление с
переходом вперед. Здесь возможны два различных пути решения в зависимости от
условия. Существует два вида этой структуры:
-
односторонний
выбор - выполняет
действие только на одном из путей разветвления и соединяет оба пути в один,
т.е. if (Условное выражение) Инструкция;
-
двусторонний
выбор – выполняет
действия на каждом пути разветвления и также соединяет оба пути, т.е. if (Условное
выражение) Инструкция1; else Инструкция2;
Далее автор рассматривает
еще один вид условного оператора, выражаемого вопросительным знаком. Он имеет
следующий вид:
Условное выражение ?
Выражение1: Выражение2
Выражение с условием не
может стоять в одиночестве, как в предыдущем ветвлении, а стоит внутри
выражения.
Третья условная структура
многократный выбор switch..case. Автор
показывает, что в этой структуре имеются больше чем 2 пути выбора, которые также
соединяются. Для каждого условия обязательно существует своя инструкция. Для
всех оставшихся случаев выполняется какое-то действие. Структура switch .. case
имеет такой вид:
switch (Выражение)
{
case W1: Инструкция 1;
...;
case Wn: Инструкция n;
default: Инструкция (по
умолчанию);
}
2.3 Циклические операторы
В этом параграфе профессор
объясняет, что структуры повторения используются, если последовательность команд
должна повторяться неоднократно для решения задачи. Программирование структуры
повторения ведет к так называемому "программному циклу".
В случае со структурой
while условие стоит в начале программного цикла, поэтому цикл может не
выполниться ни разу. Общий вид команды таков:
while (Условные
выражения) Инструкции;
Следующая циклическая
структура – повторение for
представляет самую универсальную форму повторения. Команда имеет следующий вид:
for (Выражение 1;
Выражение 2; Выражение 3)Команда;
где Выражение 1
начальное значение выражения, Выражение 2 – условное выражение, которое должно
выполниться для выполнения команд, Выражение 3 – изменяет счетную величину для
продолжения повторения.
Затем автор рассматривает
структуру, обратную структуре while. Последовательность команд запускается в
любом случае, по меньшей мере, однажды. Поэтому эту структуру называют также непредотвратимым
повторением.
Do
Инструкция;
while (Условное
выражение);
Таким образом, в данной
главе автором были разобраны различные типы трех структурных единиц любого
языка программирования – линейной, разветвляющейся и циклической.
3.
Функции
В этой главе автор
рассказывает об одном из главных структурных элементов программы – функциях. Во
всех высокоуровневых языках программирования происходит разделение программ на
части с помощью подпрограмм-функций.
Функции реализуют
идеологию структурного программирования и исполняют все необходимые задания для
решения общей задачи. Для самых важных и часто используемых заданий имеются
стандартные функции, занесенные в программные библиотеки C. Для решения других
задач необходимо написать собственные функции. Все C-программы состоят из
набора небольших функций. Для определения функции в языке C необходимо указать
тип и имя, а также список параметров в круглых скобках.
В языке C любая функция
определяется глобально, т.е. не зависит от других функций. В общем виде
эту структуру можно представить так:
Тип имя функции (список
параметров)
{
Соглашения
Инструкции
return (значение функции)
}
Для каждого из параметров
функции представляется его тип. Эти формальные параметры имеют собственное имя,
которое используется в пределах работы функции и собственный тип. Например,
функция:
int quad (int x)
{
return (x * x);
}
содержит параметр с
именем x типа Integer(целый).
При вызове функции
формальные параметры заменяются актуальными параметрами, в качестве которых
могут выступать определенные значения, константы или переменные величины.
Например: y = quad (25); При этом тип актуального параметра должен обязательно соответствовать
типу формального параметра.
Особенно автор обращает
внимание на имена переменных, констант, функций в программе. В программе
существуют две позиции на значение имен:
1.
Готовность (Доступность).
Этим свойством определяются места программы, в которых можно получить доступ к
тем или иным объектам (переменным величинам или функциям). Здесь существует 4
основных программных области – программа, модуль, функция, блок. Объекты,
которые определяются в самой программе или модуле являются глобальными
объектами, а если определяются в пределах блока или функции, то являются локальными
объектами.
2.
Срок службы (Жизненный
цикл). Здесь говорится о длительности упорядочивания ячеек памяти. Различают
полное время распространения (статическая продолжительность) и время выполнения
блока, в котором определялся объект.
Эти правила дают ряд
преимуществ при написании программ:
·
Переменная
получает определенное значение в пределах функции.
·
Локальные
переменные не применяются для всей программы, поэтому можно использовать
одинаковые имена переменных в различных функциях.
·
Глобальные
переменные определяются один раз и используются всеми функциями программы.
·
Если имена
глобальных и локальных переменных совпадают, то в данной функции используются
значения локальных переменных. Таким образом, необходимо избегать написания
одинаковых имен переменных.
В этом параграфе автор
рассказывает о очень важном методе решения задач – рекурсивных алгоритмах. Алгоритм
называется рекурсивным, если вызов функции происходит в пределах самой
функции, т.е. функция ссылается сама на себя. При этом основная мысль состоит в
том, чтобы уменьшать рекурсивным образом данную проблему до тех пор, пока не
будет получен простейший случай. При этом значительно уменьшается алгоритм
решения задачи.
Чтобы достигнуть
рекурсивности, локальные переменные величины и параметры должны сохраняться не в
статической памяти, а в так называемой динамической памяти, которая реализуется
программно.
Также из большого
количества шагов состоит итерационный алгоритм. Он содержит промежуточные шаги,
которые образуют основу для промежуточных результатов в следующем повторении (итерации).
Итерации используются в основном при обработке больших массивов данных.
Различают 2 основных вида итераций:
- Алгоритмы с заранее известным
количеством шагов повторения.
- Алгоритмы с заранее неизвестным
количеством шагов повторения.
Программист должен всегда
заботиться о том, чтобы все процессы, которые протекают в определенной
программе, после конечного числа шагов завершались. К сожалению, зачастую этого
не происходит и программа «зацикливается».
Поэтому, если написана
какая-то условная или циклическая структура, необходимо следить, чтобы после
конечного числа прохождений условие не было больше выполнено. Конечность
повторения можно подытожить следующим образом: число шагов зависит от
переменных величин программы и оно больше 0, если условие выполняется хотя бы
один раз, а значение счетчика определяется в зависимости от действий.
В этом параграфе автор
рассказывает о наиболее важных стандартных функциях, которые позволяют вводить
информацию с клавиатуры и выводить ее на экран.
Ввод и вывод данных в C
происходит через файловый интерфейс. При этом с устройствами, как, например,
принтер или консоль обращаются как с файлами. В стандартной C-библиотеке для нескольких
устройств существуют стандартные файлы:
·
stdin (стандартный ввод данных,
клавиатура)
·
stdout (стандартный вывод, монитор)
·
stderr (ошибки вывода, монитор)
С функциями ввода-вывода
связан файл заголовка stdio.h стандартной библиотеки заголовков. В нем
определены для применения функций необходимые функциональные прототипы, такие
как типы и константы (макрокоманды), которые стоят в связи с реализацией и
приложением функций. Кроме всего прочего определяется константа EOF, которая служит
для внутренней идентификации конца файлов.
Также существует
специальная функция вывода информации – printf, которая имеет вид:
int printf(контрольная
строка, аргумент1, аргумент2, ... ). Функция printf копирует символы из формата
стандартного вывода либо до конца строки, либо до символа %. Чтобы определить тип
формата вывода, функция ищет следующие за % символы. Самый часто используемым
является формат %d, который выводит целые числа в десятичной системе счисления.
Стандартной функцией
ввода данных в C является функция scanf, которая имеет следующий вид:
scanf (контрольная строка, аргумент1, аргумент2,...). Она переводит
соответственно в управляющую строку "контрольную строку" данного типа
и формата. Она задает формат и назначает конвертированные значения через
определенный адрес соответствующим переменным величинам arg1, arg2....
4.
Типы данных в C
В этой параграфе автор
рассказывает об основах представления чисел в компьютере.
Значение числа Z = an
an-1 ... a0 a-1 ... a-m в
позиционной системе счисления по основанию B имеет вид:
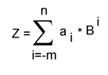
где 0 <= a <B.
Например, в десятичной
системе счисления число 1972 выглядит так:
1972 = 1 * 103 + 9 * 102
+ 7 * 101 + 2 * 100
Формой представления
чисел в компьютере является двоичная. Недостатком этой системы является
запутанная, монотонная последовательность цифр при изображении длинных двоичных
чисел. Поэтому в информатике также используют часто восьмеричную и шестнадцатеричную
системы счисления. Именно о них рассказывает автор в этой главе.
Достаточно часто
возникает необходимость преобразования чисел из одной системы в другую, в
частности, в наиболее понятную человеку десятичную систему счисления. Правило
преобразования из любой системы счисления в десятичную выглядит так:
При переводе числа из
любой системы в десятичную надо это число представить в виде суммы степеней
основания его системы счисления.
Дробные числа возможно
изображать в информатике двумя способами:
-
Изображение с фиксированной
точкой (например, 1.25). При этом точка всегда стоит на своем месте в
нужном разряде.
-
Изображение с плавающей
точкой. При данном изображении число записывается таким образом, что точка
скользит всегда к первой отличной от нуля цифре. Такая запись
выглядит следующим образом:
Z = М * BE, где M = 0.xxxxxxx....,
1/B <= М <1
Так как основа нам известна,
то число может представляться мантиссой М и экспонентой E (нормализованное
изображение). Например:
Z = 42.5456 -->
0.425456 * 102 --> M = 425456, E = 2
4.2 Основные типы данных
В этом разделе профессор
перечисляет соответствующие категории языка C.
К элементарным типам
данных, использующихся в C относятся: char (символьный), int (целый), float (вещественный
тип с одинарной точностью), double (вещественный тип с двойной точностью), void
(пустой, используется для функций и указателей).
Автор выделяет следующие виды
констант, использующихся в языке Си:
·
целочисленные
константы, которые имеют тип signed int.
·
Константы с
плавающей точкой. Они представляются в десятичном или экспоненциальном виде и
имеют тип double.
·
Символьные константы
указываются в кавычках ‘’.
·
Литерные
константы имеют тип String и
расположены в кавычках “”.
Затем Плате рассматривает
основные арифметические операторы («-», «+», «*», «/», «%»),
используемые в языке C. Здесь, в отличие от других языков программирования,
присваивание значений записывается прямо в операторах, поэтому арифметические
операции применяются во всех структурах, где есть операторы. В C также
используется также два специальных оператора:
o
Инкремент (приращение на 1) – «++»
o
Декремент (отрицательное
приращение на 1) – «--»
Они могут стоять перед
или после операнда, что задает порядок выполнения операций.
Помимо этого в C используются логические операторы:
·
! - логическое отрицание
·
&& - логическое «и»
·
|| - логическое «или»
Профессор отдельно
выделяет операторы сравнения, используемые в языке:
·
< - меньше
·
<= -
меньше равно
·
> -
больше
·
>= - больше
равно
·
== - равно
(тождественно)
·
!= - не равно
Специального логического
типа данных Boolean в C не существует, а считается, что
Ø Неравно 0 – правда (значение 1)
Ø Равно 0 – ложь (значение 0)
Составные операторы используются для более компактной
записи выражений в С. Автор показывает, что здесь возможны следующие записи:
Выражение1 op= Выражение2,
которая эквивалентна записи –
Выражение1 = (Выражение1)
op (Выражение2), где op – любой оператор.
Затем профессор выделяет
два основных вида массивов:
§
Одномерные поля. Определим поле с 5
элементами - int n [5]; Тогда эти 5 переменных величин располагаются в памяти
последовательно:
| n [0] |
n [1] |
n [2] |
n [3] |
n [4] |
Элементы массива
начинаются всегда с индекса 0 и кончаются индексом [n-1].
При этом не происходит
проверка на допустимую область памяти компилятором.
§
Многомерные поля.
Для
многомерных массивов переменные величины задаются несколько другими типами
индексов. Пример определения двумерного массива: float x [8] [30];Здесь первый
элемент - x [0] [0], и соответственно последний x [7] [29].
Юрген Плате подходит к
объяснению работы с символами и строками как с одномерными полями,
которые имеют несколько особенностей. Строки могут инициализироваться также в
классе памяти auto и должны быть замкнуты '\0 '. Например: char s[] =
{'s','t','r','i','n','g','\0'};
Массивы char могут
инициализироваться также константами String –
char s[] =
"string";
В C не имеется никаких
специальных элементов языка для манипуляции строками символов. Ряд функций
существуют в C-стандартной библиотеке (копирование, сравнение, длина строк).
В отличие от массивов,
которые работают с объектами одного типа, записи задают структуру для
описания различных типов под общим именем. Преимущества этих структур состоит в
объединении комплексных данных. Например, это персональные данные (Ф.И.О.,
адрес, социальный статус и т.д.) или студенческие данные (Ф.И.О, адрес,
дисциплина, отметка и т.д.).
Записи в языке C
описываются с помощью ключевого слова struct:
struct имя структуры
{компонент(n)} переменная структуры (n);
Для доступа к элементу
записи используются 2 собственных оператора.
При этом для прямого
доступа необходима точка как разделитель переменной структуры и имени
компонента, т.е переменная структуры . компонент
Структуры могут иметь
также элементы, которые являются signed(со знаком) или unsigned(без знака) int,
а некоторые имеют битовую длину. Поэтому обозначают эти элементы как поля бита.
При определении структуры число битов таких переменных величин указывается
определенно, согласно синтаксису:
typedef struct
{ unsigned b1
: 1;
unsigned b2 :
1;
int : 6;
int farbe : 4;
} bitpack;
Таким образом, в этой
главе автором рассмотрены практически все типы данных, используемых в С и
имеющих широкие возможности применения.
5. Файлы
Следующей структуре,
являющейся основным носителем информации в компьютере, автор посвятил отдельную
главу.
Файлы - это основная структура для
постоянного хранения и ввода-вывода данных. Файлы состоят из различных
компонентов определенного типа данных. В конец файла могут добавляться
различные данные.
Вместе с типом файла
определяются и несколько стандартных операций с файлами (Open – открытие файла,
Close – закрытие файла, Read – чтение из файла данных, Write – запись данных в
файл).
5.1
Типы доступа
В следующих параграфах
автор определяет 2 основных типа доступа для файлов в Cи:
1) Последовательные файлы использовались на заре развития компьютерной техники, так как запись на перфоленту или магнитную ленту могла вестись только последовательно. 2) Файлы с произвольным доступом. С появлением жестких дисков, которые позволяют обращаться к любым участкам памяти в любое время, появились файлы с произвольным доступом.
В последовательных файлах
позиционирование компонентов производится неявно и не подчиняется влиянию
программы. В файлах с произвольным доступом операции считывания и записи
дополняются указанием индекса компонентов. При этом индекс компонентов
отсчитывается, как правило, от 1. Вместе с тем файл с произвольным доступом
обладает сходством с типом данных "массив".
Доступ к различным
периферийным устройствам в C осуществляется с помощью указателей. При этом файл
должен открываться до начала доступа и закрываться после. Для выполнения этих
функций используется стандартный файл C-библиотеки <stdio.h>.
Что касается самого
распространенного типа файлов – текстовых, то в C они представляют собой файлы,
компоненты которых буквы, т.е. символы типа char. Все тексты мы разделяем на
строки, и здесь встает проблема: как определить конец строки, когда реализация
текстовых файлов во всех программах разная?
В Си используется, так
называемый, буферный вывод. Это значит, что выводится только тогда, если конец
строки посылается устройству вывода, или выводится совсем, если программа
завершает свои действия.
Здесь используют
следующие функции языка C:
·
int putc(int c, FILE *f) - записывает символы в текстовые файлы.
·
int getc(FILE *f) – читает символы из файла.
·
int puts(const char *s) – записывает последовательность
символов в файл.
·
char *gets(char
*s) – чтение последовательности из файла.
При бинарном вводе и
выводе данные представлены в допустимой форме, а внутреннее изображение в
памяти перенесет (побайтово) данные в файл. Например, для бинарной записи
переменных величин long нужно 4 байт памяти. Необходимое количество памяти
зависит от величины числа и соответственно от его формата.
Функция fwrite записывает
указанное количество элементов данных равной величины в файл. Здесь должны
передаваться:
· Адрес первого элемента данных. · Величина отдельного элемента данных. · Количество записываемых элементов данных · Выходной файл
Затем автор рассказывает,
как получить доступ к отдельным наборам данных файла с произвольным доступом.
Для этого в C используются следующие команды:
int fseek(FILE *f, long offset, int origin)
Эта функция ставит
указатель на определенную позицию в пределах файла. Функция позиционирует
смещение (offset), которое считается в байтах. Значение origin устанавливается
в соответствии со смещением (SEEK_SET oder 0 – смещение из начала файла,
SEEK_END oder 1 – смещение из текущей позиции, SEEK_CUR oder 2 – смещение из
конца файла)
Функция long ftell (FILE
*f) указывает текущую позицию в файле, на которой находится указатель файла. В
случае ошибки ftell принимает значение -1.
Функция void rewind (FILE
*f) перемещает указатель на начало файла и удаляет значение ошибки.
Таким образом, Юрген
Плате в отличие от других авторов книг по программированию достаточно подробно
описывает процесс работы с файлами, снабжая каждую операцию подробными
комментариями и примерами на языке С.
6.
Указатель
В этой главе автор
рассказывает об одном из важнейших понятий программирования в C – указателях.
Указатели - это такие же
переменные величины, которые нуждаются в ячейках памяти. Указатель - это переменная величина,
которая содержит адрес другого объекта. Потом можно получить доступ к этому
объекту косвенно с помощью указателя. В этих адресах памяти содержится либо
адреса других переменных величин, либо адреса функций.
Указатели в языке C
необходимо применять в следующих случаях:
· при передаче параметра
· при обработке массивов
· для обработки текста
· для доступа к специальным ячейкам
памяти
Обозначаются указатели
следующим образом: int *pc; , т.е. переменная pc является указателем тип int.
При этом используют
преимущественно два типа указателей:
1.
Оператор адреса
&, который применяется к объекту, доставляющему адрес этого объекта.
Например, pc=&c.
2.
Смысловой
оператор *, который применяет указатель к объекту, находящемуся в этой ячейке.
Например, c=*pc; *pc=5;
Особенно важным является
то, что * и & имеют более высокий приоритет, чем арифметические операторы.
При этом если используются несколько операторов указателя последовательно, то
выражение обрабатывается справа налево.
Аргументы указателя
обладают возможностью обращаться к объектам функции из другой функции и
изменять их.
Автор также показывает,
что с указателями можно проводить определенные арифметические операции и
операции сравнения. Разрешены, конечно, только такие операции, которые ведут к
осмысленным результатам. К указателям могут целочисленные значения прибавляться
и вычитаться из них. К указателям могут также применять декремент.
Можно указатели
посредством операторов >,> =, <, <=, != и == сравнивать друг с
другом. Всевозможные арифметические и логические операции, не описанные выше, не
разрешены с указателями.
Как отмечает автор в
следующих параграфах, между указателями и полями существует ярко выраженная связь.
Каждая операция, которая может применяться к элементам массива, может
выражаться также и указателями. Программа, содержащая указатели выполняется
гораздо быстрее. Однако понять смысл использования указателей гораздо тяжелее.
Присваивание pa = *a [0]
показывает, что pa указывает на 0-ой элемент массива a, т.е. pa содержит адрес
a [0]. Вместо этого можно записать следующее: pa = a;
К отдельным элементам
массива можно обращаться 3 различными способами:
·
a [i] -
i-ый элемент массива
·
* (pa+i) - указатель
pa + i * (длина элементов массива a)
·
* (a+i) начало
массива + i * (длина элементов a)
Таким образом, каждое
значение индекса массива может определяться также как значение смещения
указателя и наоборот. Выражение pa + i не значит, что к pa значение i прибавляется,
а i устанавливает смещение объекта от pa.
Многомерные массивы можно
задавать через указатели следующим образом:
Matrix[1][2]=*(Matrix[1]+2)
Matrix[1][2]=*(*(Matrix+1)+2)
Matrix[1][2]=*(*Matrix+1*M+2)
Так называемые
структурные указатели имеют несколько другое обозначение:
Указатель на структурную
переменную -> название элемента
Например, punkt.px
соответствует (*punkt)-> px
Так как структура
указателей и массивов очень похожа, то далее автор объясняет как составить
массив указателей.
Массив указателей - это
массив, состоящий из элементов-указателей. Вектор указателей определяется следующим
образом:
Тип исходных данных *Имя
вектора[]
Эту запись необходимо
отличать от указателя на вектор:
(*Имя вектора) []
Компоненты вектора могут
быть также адресами массивов. При этом такой массив указателей похож на
многомерный массив.
Например, char *Z[3], где
происходит определение массива с 3 элементами, которые являются соответственно
указателями типа char. При этом Z является указателем на массив с 3 указателями
char.
Помимо указателей на типы
данных в C можно определять указатели и на функцию, которые можно использовать
затем как переменные величины. Это может пригодиться для передачи значения
функции в другую функцию.
Указатель на функцию в C
записывается следующим образом:
Тип возврата (*Имя
функции) (Аргументы функции)
Здесь необходимо обратить
особое внимание на то, что имя функции стоит в скобках. Если мы запишем без
скобок *Имя функции (), то функция будет возвращать значение указателя.
Функциональные указатели
можно использовать в следующих случаях:
· Как переменную-указатель, которая на
функцию указывает.
· Распределять значения функциональных указателей.
· Определять массивы функциональных
указателей.
· Передавать указатель на функцию как
параметр.
· Получать указатель на функцию как возвращенное
значение.
Таким образом, профессор обращает
также особенное внимание на широкое использование указателей при
программировании в С. Это, в общем-то, оправданно довольно высоким
быстродействием программ с указателями, но может привести к дополнительным
ошибкам программирования из-за трудностей восприятия указателей.
7.
Динамические структуры данных
7.1 Динамическое управление памятью
До сих пор речь шла
только об объектах данных, для которых компилятор C предоставляет память и ее
количество и величина должны быть определены к началу перевода программы в
машинные коды. Такие объекты называют статическими.
Работать с ними не всегда
удобно, так как в процессе выполнения программы возникает необходимость
увеличить размеры памяти, выделенной для этой структуры. Для борьбы с этим
необходимо определять такие объекты с максимальной величиной.
Наиболее приемлемым
решением здесь будет применение динамически распределяемой памяти, т.е.
определять объекты во время действия, т.е. динамично. Это решение позволяет
оперативно освобождать большое количество памяти и избегать ее переполнения или
напрасного расходования при статическом распределении.
Динамические объекты определяются несколько
по-другому. К ним обращаются не по имени, а только по их адресу. Эта адресация
возникает при распределении памяти и назначается обычно с помощью
переменных-указателей. Динамическое распределение памяти происходит посредством
стандартных функций языка Cи:
·
void *malloc
(size_t size) – занимает определенную связную область памяти и поставляет из
нее начальный адрес.
·
void *calloc
(size_t nobj, size_t size) – возвращает начальный адрес большой области;
содержание этой области инициализируется значением 0.
·
void * realloc
(void *ptr, size_t size) - изменение величины размещения блока памяти.
·
void free(void *)
используется для освобождения области памяти, которая больше не используется.
·
size_t sizeof
(something) – определяет длину аргумента.
При использовании
указателей, которые служат в качестве значений, возвращаемых функцией, нужно
следить, чтобы они не указывали на локальные объекты, которые исчезают после
работы функции.
Динамические структуры
данных, как поясняет Юрген Плате в следующих параграфах, изменяют свою
структуру и занятое ими пространство памяти во время выполнения программы. Они
формируются из отдельных элементов, так называемых 'узлов', между которыми
существуют определенные взаимосвязи. Речь в основном при этом идет о
структурах, которые обозначаются как 'списки' или 'деревья'.
Отношение отдельных узлов
выстраиваются следующим образом: указатель одного узла указывает на место
памяти «соседа». Самыми важными из этих структур данных являются:
·
Линейные
списки - простые
цепочные списки, двойные цепочные списки, специальные формы, буфер(FIFO),
стек(LIFO).
·
Деревья - Бинарные деревья – 2 соседа,
многодорожные деревья - больше чем 2 соседа.
·
Общие графы
Линейные списки
используют элементы, в которых указаны связанные сведения в форме строки
символов. Элементы списков можно представить наглядно следующим образом:
| Информация элементов
списка (строки символов, например, имя) |
Указатель на следующий
элемент |
При построении цепочного
списка отдельные элементы списка выстраиваются в определенном порядке друг за
другом:

где символ электрической
массы в конце списка указывает на NULL-указатель, который показывает конец
списка, а root - указатель, показывающий происхождение списка (как правило,
глобальная переменная)
Еще одна важная
динамическая структура, о которой рассказывает автор в этой главе
древовидная. Древовидные структуры играют очень важную роль в организации
данных. Их используют в следующих случаях:
· при построении родословного дерева; · как организационная структура предприятия · при распределении текста по главам, разделам, абзацам и т.д.
Дерево определяется
следующим образом:
· Древовидные структуры имеют разветвления, которые могут исходить из начального элемента структуры и из самих разветвлений до тех пор, пока конечных точек не достигнут. · Элементы дерева называют узлами, причем начальный элемент называется корневым узлом, а конечные точки – листами. · Линии соединения двух узлов называется ребрами. Последовательность ребер от корня до любого узла называется путем. · Узлы, которые одинаково удалены от корня образуют уровень дерева. Общее число уровней указывает глубину дерева. · Максимальное количество наследников, которые имеет узел, определяют степень дерева. Дерево степени 2 - это бинарное дерево, наиболее важный случай.
Древовидная структура имеет
рекурсивную природу, так как наследники узла соответственно могут пониматься
как корни деревьев. Бинарное дерево можно изобразить следующим образом:
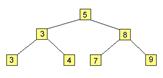
Таким образом,
динамические структуры данных, как показывает автор, являются наиболее
эффективным способом распределения оперативной памяти и соответственно
необходимо их использовать в программе, применяя указатели.
8.
Избранные алгоритмы
В этой главе Юрген Плате
рассматривает наиболее распространенные и типичные виды алгоритмов,
реализованные на Си.
К простым операторам
строк, которые задаются с помощью <ctype.h>, автор относит следующие
операторы:
| islower(c) |
Строчная буква |
| isupper(c) |
Прописная буква |
| isalpha(c) |
Строчная или прописная
буква |
| isdigit(c) |
Десятичное число |
| isalnum(c) |
Строчная или прописная
буква или десятичное число |
Наряду с простыми
операторами имеется ряд комплексных команд для строковых символов. Прототипы
находятся в стандартной библиотеке <STRING.H>.
·
strcat (char *a,
char *b) – Последовательность символов b прибавляется к a.
·
strncat ( char *a
, char *b , int n ) – прибавляются к а n символов b.
·
strcpy ( char *a
, char *b ) – строка b копируется после a
·
strncpy ( char *a
, char *b , int n ) – n символов строки b копируется после a
·
int n = strlen (
char *a ) – возвращает длину строки
В этом параграфе автором
собраны достаточно простые алгоритмы, связанные с использованием даты и
времени.
В первую очередь автор
рассказывает о юлианском датоисчислении. При этом не имелось бы никакой
проблемы 2000 года. Вместо этого дата сохранялась в компьютерах как строка
символов (TTMMJJ) и это привело к тому, чтобы после 99 шел год 00. Причина
такого датоисчисления была связана с необходимостью экономии памяти.
Алгоритм расчета даты по
Юлианскому стилю можно представить следующим образом:
Y = год, М = месяц, D =
день
Если M> 2, то Y и М
остаются неизменными. Если М = 1 или М = 2, то
Y = Y - 1
М = М + 13
Для нахождения текущей
даты имеем:
JD = INT (365
.25 * (Y + 4 716)) + INT (3 0.6001 * (М + 1)) + D + B - 1524.5
Здесь профессор приводит
некоторые алгоритмы, которые работают с числовыми данными.
Достаточно часто в
алгоритмах необходимо определить является ли число простым. Чтобы это
устанавить, необходимо делить число X на числами, которые больше 2 и меньше X.
Если число ни на какое из них не делится, оно должно быть простым.
Затем автор рассказывает
о нахождении нулей функций. Для этого применяют методы аппроксимации. Если
задан интервал (a;b), на котором определена функция, то необходимо каждый раз
делить интервал пополам и проверять где находится нуль. Повторяется действие до
тех пор, пока интервал не станет достаточно мал.
Еще один типичный пример
рассмотрен в этом параграфе автором – решение систем линейных уравнений методом
Гаусса.
Пусть задана система
уравнений вида Ax = b. Считается, что если k-е уравнение будет решено, то:
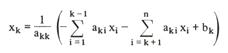
При решении методом
Гаусса исходные уравнения преобразуют таким образом, что матрица коэффициентов
содержит нули ниже главных диагоналей. Для этого используются операции сложения
и вычитания уравнений, а также умножения их на число. При этом система
принимает вид:
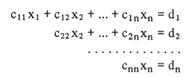
В этом параграфе автор
затрагивает статистический метод обработки информации и построение программ на
основе этого метода. Статистика обрабатывает эмпирические числа и на основании
этой обработки делаются прогнозы и принимаются решения.
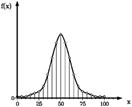
Методом математической
статистики анализируют массовые явления. При этом обнаруживаются определенные
закономерности, которые нельзя формулировать для единичных явлений. Лучшим
представлением статистических данных является графическое изображение. В
качестве примера изображено распределение частоты гауссового нормального
распределения.
Наряду с функцией частоты
основную совокупность данных можно охарактеризовать с помощью среднего
значения и дисперсии. Арифметическое среднее значение определяется
так:
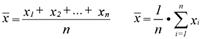
а дисперсия следующим
образом:
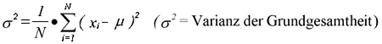
При работе с измерительными
величинами часто необходимо установить связь между отдельными точками. Здесь
помогают такие операции как интерполяция и регрессия.
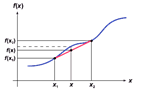
При линейной интерполяции
выполняют аппроксимацию функциональных значений f (x) на промежутке (x1,x2)
из известных значений f (x1) и f (x2).

Поиск
и сортировка
В этом параграфе автор
рассказывает о наиболее распространенных в программировании операций с данными
поиске и сортировке.
Сортировка значительно
облегчает работы с данными в программировании. Следствием таких операций
является более эффективный поиск в программе.
Различают несколько
основных методов поиска, зависящих от типа данных:
1.
Табличный
поиск осуществляется
по индексу данных в таблице.
2.
Линейный поиск предполагает просмотр всех элементов
по порядку до нахождения нужного.
3.
Бинарный поиск осуществляется после проведения
сортировки, суть которого состоит в проверке среднего элемента
последовательности и определения по ключу в какую сторону двигаться для
нахождения нужного элемента.
Сортировка является одной
из самых важных операций с данными. Профессор приводит такое определение
сортировки:
Сортировка - процесс упорядочения заданного
множества объектов в определенном порядке. Выделяют следующие виды алгоритмов
сортировки:
-
Пузырьковая
сортировка. В первом
проходе массив обрабатывается с конца до начала и сравнивается при каждом шаге
текущий компонент со следующим. Если нижний компонент меньше чем верхний, то
они меняются местами. Это происходит до тех пор, пока последовательность не
будет возрастающей или убывающей.
-
Сортировка
выбором. В этом
случае берут первый элемент последовательности и ищут самый маленький элемент,
с которым его и меняют местами. Затем начинают со второго и его меняют на самый
маленький в оставшейся последовательности и т.д.
-
Сортировка
вставкой. При этом
предполагается, что часть последовательности уже отсортирована. Элементы не
сортированной части по порядку перемещают в сортированную до тех пор пока
элемент не станет больше или равным впереди идущего элемента.
-
Сортировка
методом Шелла. Сначала
массив разделяется на несколько групп, между членами которых имеется равное
расстояние. Пусть, например, используется расстояние 3, тогда компоненты 1, 4,
7 принадлежат одной группе, так же как и 2, 5, 8..., 3, 6, 9... и т.д. эти
группы упорядочиваются в отдельности, затем расстояние уменьшается и действия
повторяется до расстояния 1.
-
Быстрая
сортировка. Выбирают
любой компонент массива - к примеру, средний - и массив делится на 2 группы: одна
с компонентами, которые больше чем выбранный, а другая с меньшими. Эти обе группы
делятся вновь по заданному алгоритму. Таким образом, получается рекурсивная
функция, которая достаточно быстро сортирует данные.
Автор в этой главе
упоминает о множествах – достаточно важной структуре программирования. Другие
языки программирования (например, Паскаль) имеют тип данных множества. В языке C
такого не имеется.
Однако множества возможно
представить с помощью битовых массивов. Элементы массива нумеруются, и каждый
элемент множества представляет собой 1 бит. Если соответствующий бит установлен
(1), то элемент содержится в множестве, если бит равен 0, соответствующий
элемент не содержится в множестве. Пересечение и объединение можно использовать
с помощью логических операторов UND и ODER. Так как переменные величины типа int
или char только относительно маленькие множества могут представлять, то
получить к ним доступ можно с помощью указателя на битовый массив.
8.2
Экскурс: процессы или сигналы
В этом параграфе
профессор несколько уходит от программирования и пытается объяснить, как
выполняются программы в операционной системе на примере ОС Linux.
Linux - это многозадачная
операционная система, которая может выполнять несколько заданий одновременно.
При этом каждая из этих программ ведет себя таким образом, как если бы она была
единственной, запускаемой в данный момент на компьютере.
Если под Linux
запускается программа, она получает однозначный идентификационный номер ID,
который лежит в диапазоне между 1 и 32 767. Посредством этого номера ОС может
идентифицировать находящиеся в памяти программы и получить доступ к ним. Для
работы с ID используются две функции, которые определены в файле заголовка
unistd.h:
1. pid_t getpid(void) – возвращает PID 2. pid_t getppid(void) – возвращает родителей PID-процесса.
Следующий важный элемент для
операционных систем - сигналы, которые предоставляют возможность запускать
новые процессы или заменять процесс другим процессом. Сигналы - это
сообщения, которые посылаются операционной системой в текущую программу для
каких-либо действий. Некоторые сигналы вызываются в результате ошибки в
программе, другие вызываются по требованию пользователя.
В таблице автор приводит
список чаще всего подаваемых Unix сигналов.
| Имя |
Значение |
Функция |
| SIGHUP |
1 |
Выход
из системы |
| SIGINT |
2 |
Прерывание
пользователя (клавиши Ctrl+C) |
| SIGQUIT |
3 |
Запрос
пользователя на окончание (клавиша CTRL + \) |
| SIGFPE |
8 |
Ошибка
с плавающей запятой |
| SIGKILL |
9 |
Принудительное
завершение процесса |
9. Стиль программирования. Ловушки
Существует такое понятие в
программировании как стиль программирования. Для различных языков программирования он разный. Автор
пытается дать рекомендации для программирования в C. Из многочисленных советов
автора можно выделить следующие, самые общие:
- Используйте *define для символьных констант.
- Используйте исключительно прописные
буквы для констант и смешанную форму записи или символ подчеркивания для
переменных и имен функций.
- Используйте функции, чтобы Ваши
программы были короткими, ясными и соблюдался принцип модульности. Каждый шаг
необходимо комментировать.
- Язык C предусматривает только
минимальную проверку ошибок в программе. Это значительно ускоряет работу
программы и допускает некоторые вольности в программировании. Но, тем не менее,
программисту необходимо проверять некоторые значения в программе с помощью
различных структур.
- При написании выражений, особенно
условий, используйте скобки, чтобы указать последовательность и приоритет
оценки.
- Выравнивайте команды таким образом,
что легко определялась структура программы, состоящая из отдельных блоков.
- Используйте массивы с указателями из
строк символов вместо двумерных массивов, если строки символов имеют различную
длину.
- По возможности используйте
динамические структуры данных
9.2
Ловушки в C
В заключении профессор
предостерегает нас от наиболее часто встречающихся ошибок программирования в C:
§ Чтобы избежать ошибок memory fault(недостаток памяти) необходимо в программе проверять границы получаемых строковых величин. § Одна из частых ошибок – постановка точки с запятой в конце команды. Компилятор C замечает это только в следующей строке и указывает затем на эту ошибку. § При написании условной структуры часто не ясно, к какому IF принадлежит ELSE. Например, if (i > j) if (k < 100) tuwas(); else tuwasanderes(); При этом получается, что ELSE принадлежит первому IF. На самом деле она принадлежит всегда ближайшему IF. § Если объявляется переменная double d=3/4, то в результате получается 0, так как 3 и 4 - целые числа. Для того, чтобы получить результат необходимо записать 3.0 и 4.0 § NULL определяется только #define NULL. Указатели не могут быть никакими целыми значениями. Указатель должен быть инициализирован допустимым адресом памяти.
Заключение
Тема, освещенная автором
в этой книге, является одной из самых актуальных тем курса информатики.
Алгоритмизация, рассмотренная в первой главе книги, является основой построения
науки «информатика», а программирование, изложенное в последующих главах,
является основным способом реализации алгоритмических структур с помощью
машинных кодов.
Язык C тоже был выбран
автором не случайно. Плате поставил целью этой книги научить искусству
программирования и указать на ошибки в составлении программ. Язык C как нельзя
лучше подходит для этих целей, так как его используют профессиональные
программисты всего мира и он достаточно демократичен в плане написания
различных структур. Правда, в связи с этим постоянно возникают некоторые
трудности в написании кода, которые необходимо вовремя устранить. Автор
помогает в этом достаточно подробно разобраться.
Первую главу автор
начинает с понятия информации как основной структуры науки информатика, без
которой невозможно составление алгоритмов. Также рассматриваются общие вопросы
устройства компьютера, основных механизмов его функционирования для понимания
сущности протекаемых программных процессов на машинном уровне. Далее профессор достаточно
подробно и понятно вводит понятие алгоритма: рассказывает, как и где
используются алгоритмы, дает определение, подробно описывает свойства.
На следующем этапе автор
подходит к понятию языка и системы программирования, дается достаточно
подробный обзор языков программирования и виды систем программирования.
Во второй части этой
главы основное внимание Плате уделил формам представления алгоритмов и записи
основных алгоритмических структур в них. Кратко разбираются графические формы
представления алгоритмов – блок-схемы и структограммы. Далее сразу автор
пытается использовать структуры языка C, что достаточно сложно для начинающих и
непонятно до объяснений синтаксиса языка. Поэтому, в первую очередь, необходимо
использовать промежуточные языки (например, алгоритмический язык).
Во второй части работы
рассматривается процесс программирования на языке программирования С. Для этого
сначала вводится синтаксис основных команд С. Затем объясняется их назначение и
особенности работы. Завершается этот процесс достаточно многочисленными и
разнообразными примерами программ.
Стоит обратить внимание
на то, что автор периодически отвлекается от процесса программирования и
рассматривает общие информатические вопросы каким-то образом связанные с темой (системы
счисления, процессы в операционной системе). Это дает возможность утверждать,
что данный труд является не только обучающим пособием по программированию, но и
по информатике в целом.
Несомненно, данная книга
представляет большой интерес как для начинающих, так и для опытных
программистов, а также для людей занимающихся информатическими проблемами.
Многие советы и рекомендации по организации процесса создания ПО, данные
автором, я буду использовать в своем диссертационном исследовании.
|



