Информатика программирование : Учебное пособие: Основы дискретной математики
Учебное пособие: Основы дискретной математики
Федеральное агентство по
образованию
Новомосковский институт
(филиал)
Государственного
образовательного учреждения высшего профессионального образования
«Российский химико-технологический университет имени Д.И. Менделеева»
T.П. Тюрина, В.И. Емельянов
Практикум по дискретной
математике
(часть 1)
Учебно-методическое
пособие
Новомосковск 2007
Оглавление
Введение....................................................................................................... 5
Практическая работа № 1
Изучение методов сортировки данных........... 6
1.1 Теоретическая часть............................................................................... 6
1.2 Методы, используемые
при поиске и сортировке................................ 9
1.2.1 Основные понятия............................................................................... 9
1.2.2 Поиск................................................................................................. 10
1.2.3 Оценки времени
исполнения............................................................. 18
1.2.4 Сортировки....................................................................................... 19
1.3 Практическая часть.............................................................................. 40
1.3.1 Содержание отчёта
по практической работе................................... 40
1.3.2 Приложение на
Delphi, в котором представлена работа некоторых методов сортировки и поиска.................................................................................. 40
1.3.3 Пример выполнения.......................................................................... 51
1.3.4 Варианты заданий............................................................................. 53
1.4 Вопросы для
самопроверки................................................................ 62
Практическая работа № 2
Представление множеств в компьютере........ 64
2.1 Теоретическая часть............................................................................. 64
2.1.1 Множества и
операции над ними..................................................... 64
2.1.2 Представление
множеств и отношений в программах.................... 67
2.1.4 Представление
множеств в приложениях на Delphi........................ 82
2.1.5 Характеристический
вектор множества........................................... 83
2.2 Практическая часть.............................................................................. 85
2.2.1 Задание к работе............................................................................... 85
2.2.2 Примеры выполнения....................................................................... 86
2.2.3 Варианты заданий............................................................................. 90
2.3 Вопросы для
самопроверки................................................................ 92
Практическая работа № 3
Элементы теории графов............................... 94
3.1 Теоретическая часть............................................................................. 94
3.2 Практическая часть............................................................................ 111
3.2.1 Задание к работе............................................................................. 111
3.2.2 Примеры выполнения..................................................................... 111
3.2.3 Вариантв заданий............................................................................ 117
Практическая работа № 4
Элементы теории множеств и алгебры логики 122
4.1 Указание к выполнению..................................................................... 122
4.2 Задание к работе................................................................................ 122
4.3 Практическая часть............................................................................ 122
4.4 Вопросы для
самопроверки.............................................................. 133
Практическая работа № 5
Исследование логических функций............. 135
5.1 Задание к работе................................................................................ 135
5.2 Практическая часть............................................................................ 135
5.2.1 Пример выполнения........................................................................ 135
5.2.2 Варианты заданий........................................................................... 138
5.3 Вопросы для
самопроверки.............................................................. 140
Практическая работа № 6
Изучение методов минимизации логических функций 142
6.1 Краткие теоретические
сведения....................................................... 142
6.2 Практическая часть............................................................................ 144
6.2.1 Задание к работе............................................................................. 144
6.2.2 Примеры выполнения..................................................................... 144
6.3 Вопросы для
самопроверки.............................................................. 147
Практическая работа № 7
Моделирование работы узлов компьютера с помощью Еxcel................................................................................................................... 149
7.1 Теоретическая часть........................................................................... 149
7.2 Практическая часть............................................................................ 152
7.2.1 Схемы сравнения
кодов.................................................................. 153
7.2.2 Дешифраторы.................................................................................. 158
7.3 Задания к работе................................................................................ 160
7.4 Вопросы для
самопроверки.............................................................. 164
Список литературы.................................................................................. 165
Введение
В практикум
включены необходимые теоретические сведения, содержание работ, примеры
выполнения, варианты заданий, вопросы по самоконтролю знаний для 7 практических
работ. Некоторые практические работы относятся к нескольким разделам
дисциплины, поэтому для них можно, не «привязывая» к конкретному разделу, выполнять
описание в виде отдельных приложений. Все практические работы выполняются с
использованием компьютера.
Практическая
часть дисциплины адаптирована для обучения будущих специалистов по обработке
информации. Практикум содержит дополнительные сведения из теории множеств,
теории графов и алгебры логики, описание практических работ, запланированных
для выполнения студентами в процессе изучения предмета с привлечением средств
Excel, Delphi.
Содержание
пособия полностью соответствует требованиям программы дисциплины и относится к
практической части. Подготовка рукописи вызвана необходимостью создания
учебного пособия для студентов, т. к. подобные практикумы по дискретной
математике отсутствуют. Практикум содержит краткое изложение теории, которая
относится непосредственно к выполнению работ, варианты заданий, примеры
выполнения. В конце каждого раздела приведены контрольные вопросы. Студенту
предлагается выполнить индивидуальные задания.
Некоторые
практические работы являются традиционными, и составные части их представлены в
учебниках и методических разработках других вузов, основная часть является
авторской. Недостатком является отсутствие практической работы по нечётким
множествам. Пособие может быть рекомендовано студентам дневной и заочной форм
обучения.
Практическая работа № 1.
Изучение методов сортировки данных
Цель работы:
изучение наиболее известных методов сортировки данных и их использование на
примерах конкретных задач.
1.1
Теоретическая часть
Для
дискретного анализа характерно, что самые простые, казалось бы, ничем не
примечательные задачи могут быть предметом серьёзного научного исследования.
Здесь мы рассматриваем одну из таких простых задач, которая часто встречается в
приложениях, называется задачей сортировки и до сих пор остается интересной.
При рассмотрении
данного круга задач необходимо предварительно изучить тему «Множества и
отношения». Рефлексивное, транзитивное, но антисимметричное отношение R
на множестве A называется частичным порядком. Частичный порядок важен в
тех ситуациях, когда мы хотим как-то охарактеризовать старшинство. Иными
словами, решить при каких условиях можно считать, что один элемент множества
превосходит другой.
Примеры
частичных порядков.
«£» на множестве
вещественных чисел;
«Ì» на подмножествах
универсального множества;
«…делит…» на
множестве натуральных чисел.
Множества с частичным
порядком принято называть частично упорядоченными множествами (ч. у. м.).
Если R
отношение частичного порядка на множестве A, то при х 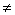 y и xRy
мы называем x предшествующим элементом или предшественником, а y
последующим. У произвольно взятого элемента y может быть много предшествующих
элементов. Однако если x предшествует y, и не существует таких
элементов z, для которых xRz и zRy, x называется непосредственным
предшественником (иначе говорят, что y покрывает x) и
обозначается x<y [3]. y и xRy
мы называем x предшествующим элементом или предшественником, а y
последующим. У произвольно взятого элемента y может быть много предшествующих
элементов. Однако если x предшествует y, и не существует таких
элементов z, для которых xRz и zRy, x называется непосредственным
предшественником (иначе говорят, что y покрывает x) и
обозначается x<y [3].
Линейным
порядком на множестве A называется отношение частичного порядка, при
котором из любой пары элементов можно выделить предшествующий и последующий.
Постановка
задачи:
пусть задано конечное множество А, состоящее из n элементов ai,
на нём задано отношение линейного порядка Р.
Требуется
перенумеровать элементы А числами от 1 до n таким образом, чтобы
из того, что i<j следовало (ai, aj)
Є P. Выполнение этой задачи называется сортировкой массива данных [3].
Способы
сравнения могут быть очень разнообразными, но в большинстве случаев они исходят
из двух базовых элементарных упорядочений: упорядочение чисел по значению и
упорядочение слов по алфавиту.
Потребность в
сортировке больших объёмов данных ощущалась очень давно, например, в комплекте
счётно-аналитических машин Холлерита была специальная сортирующая машина.
Во многих
задачах требуется иметь данные, расположенные в порядке возрастания или в
порядке убывания. Такое упорядочение в программировании называется сортировкой.
Сортировка применяется во многих задачах. Существуют различные методы
сортировки: одни из них просты, но более медленные, другие быстрые, но более
сложные. Одни сортируют каждый массив заново, другие распознают уже
упорядоченные части массива и поэтому работают быстрее.
Выдающийся
специалист по программированию Д. Кнут посвятил сортировке и поиску данных
почти весь второй том трудов «Искусство программирования для ЭВМ» [4].
Сортировка
данных – обработка информации, в результате которой элементы её (записи) располагаются
в определённой последовательности в зависимости от значения некоторых признаков
элементов, называемых ключевыми.
Наиболее
распространёнными видами сортировки данных являются упорядочение массива записей
расположение записей сортируемого массива данных в порядке монотонного
изменения значения ключевого признака. Сортировка данных позволяет сократить в
десятки раз продолжительность решения задач, связанных с обработкой больших
массивов записей. Такое ускорение происходит за счёт сокращения времени поиска
записей с определёнными значениями ключевых признаков. Упорядочение
осуществляется в процессе многократного просмотра исходного массива.
Одними из
важнейших процедур обработки структурированной информации являются сортировка и
поиск. Сортировкой также называют процесс перегруппировки заданной
последовательности (кортежа) объектов в некотором определенном порядке.
Определенный порядок (например, упорядочение в алфавитном порядке, по возрастанию
или убыванию количественных характеристик, по классам, типам и т. п.)
в последовательности объектов необходим для удобства работы с этими объектами.
В частности, одной из целей сортировки является облегчение последующего поиска
элементов в отсортированном множестве. Под поиском подразумевается процесс
нахождения в заданном множестве объекта, обладающего свойствами или качествами
задаваемого априори эталона (или шаблона).
Например,
требуется решить задачу: даны целые числа x, a1, a2,
, an (n>0). Определить, каким по счёту идёт в
последовательности a1, a2, …, an
член, равный x. Если такого члена нет, то предусмотреть соответствующее
сообщение.
В этом
примере мы сталкиваемся с задачей поиска. «Одно из наиболее часто встречающихся
в программировании действий – поиск. Он же представляет собой идеальную задачу,
на которой можно испытывать различные структуры данных…» – пишет Н. Вирт [14].
Теория поиска – важный раздел теории информации.
Очевидно, что
с отсортированными (упорядоченными) данными работать намного легче, чем с
произвольно расположенными. Упорядоченные данные позволяют эффективно их
обновлять, исключать, искать нужный элемент и т. п. Достаточно
представить, например, словари, справочники, списки кадров в неотсортированном
виде и сразу становится ясным, что поиск нужной информации является труднейшим
делом.
1.2 Методы, используемые при поиске и
сортировке
1.2.1 Основные понятия
Существуют
различные алгоритмы сортировки данных. И понятно, что не существует
универсального, наилучшего во всех отношениях алгоритма сортировки.
Эффективность алгоритма зависит от множества факторов, среди которых можно
выделить основные:
– числа
сортируемых элементов;
– степени
начальной отсортированности (диапазона и распределения значений сортируемых
элементов);
– необходимости
исключения или добавления элементов;
– доступа
к сортируемым элементам (прямого или последовательного). Принципиальным для
выбора метода сортировки является последний фактор [16].
Если данные
могут быть расположены в оперативной памяти, то к любому элементу возможен
прямой доступ. Удобной структурой данных в этом случае выступает массив
сортируемых элементов. Если данные размещены на внешнем носителе в файле
последовательного доступа, то к ним можно обращаться последовательно. В
качестве структуры подобных данных можно взять файловый тип [9].
В этой связи
выделяют сортировку двух классов объектов: массивов (внутренняя сортировка) и
файлов (внешняя сортировка).
Процедура
сортировки предполагает, что при наличии некоторой упорядочивающей функции F
расположение элементов исходного множества меняется таким образом, что
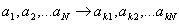
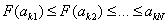 , ,
где знак
неравенства понимается в смысле того порядка, который установлен в сортируемом
множестве.
Поиск и
сортировка являются классическими задачами теории обработки данных, решают эти
задачи с помощью множества различных алгоритмов. Рассмотрим наиболее популярные
из них.
1.2.2
Поиск
Для
определенности примем, что множество, в котором осуществляется поиск, задано
как массив:
var a: array [0..N] of item;
где item
заданный структурированный тип данных, обладающий хотя бы одним полем
(ключом), по которому необходимо проводить поиск.
Результатом
поиска, как правило, служит элемент массива, равный эталону, или отсутствие
такового.
Важно знать и
про ассоциативную память. Это можно понимать как деление памяти на порции
(называемые записями), и с каждой записью ассоциируется ключ. Ключ – это
значение из некоторого вполне упорядоченного множества, а записи могут иметь
произвольную природу и различные параметры. Доступ к данным осуществляется по
значению ключа, которое обычно выбирается простым, компактным и удобным для работы.
Дерево
сортировки – бинарное дерево, каждый узел которого содержит ключ и обладает
следующим свойством: значения ключа во всех узлах левого поддерева меньше, а во
всех узлах правого поддерева больше, чем значение ключа в узле.
Таблица
расстановки.
Поиск,
вставка и удаление, как известно, – основные операции при работе с данными [16].
Мы начнем с исследования того, как эти операции реализуются над самыми
известными объектами – массивами и (связанными) списками.
Массивы
На рисунке 1.1
показан массив из семи элементов с числовыми значениями. Чтобы найти в нем
нужное нам число, мы можем использовать линейный поиск (процедура представлена
на псевдокоде, подобном языку Паскаль):
int function SequentialSearch (Array A, int Lb, int Ub, int Key);
begin
for i = Lb to Ub do
if A (i) = Key then
return i;
return –1;
end;
Максимальное
число сравнений при таком поиске – 7; оно достигается в случае, когда нужное
нам значение находится в элементе A[6]. Различают поиск в упорядоченном
и неупорядоченном массивах. В неупорядоченном массиве, если нет никакой
дополнительной информации об элементе поиска, его выполняют с помощью
последовательного просмотра всего массива и называют линейным поиском.
Рассмотрим программу, реализующую линейный поиск. Очевидно, что в любом случае
существуют два условия окончания поиска: 1) элемент найден; 2) весь массив просмотрен,
и элемент не найден. Приходим к
программе:
While (a[i]<>x) and (i<n) do Inc(i);
If a[i]<>x then Write (‘Заданного элемента нет’)
Если
известно, что данные отсортированы, можно применить двоичный поиск:
int function BinarySearch (Array A, int Lb, int Ub, int Key);
begin
do forever
M = (Lb + Ub)/2;
if (Key < A[M]) then
Ub = M – 1;
else if (Key > A[M]) then
Lb = M + 1;
else
return M;
if (Lb > Ub) then
return –1;
end;
Переменные Lb
и Ub содержат, соответственно, верхнюю и нижнюю границы отрезка массива,
где находится нужный нам элемент. Мы начинаем всегда с исследования среднего
элемента отрезка. Если искомое значение меньше среднего элемента, мы переходим
к поиску в верхней половине отрезка, где все элементы меньше только что
проверенного. Другими словами, значением Ub становится равным (M
1) и на следующей итерации мы работаем с половиной массива. Таким образом, в
результате каждой проверки мы вдвое сужаем область поиска. Так, в нашем
примере, после первой итерации область поиска – всего лишь три элемента, после
второй остается всего лишь один элемент. Таким образом, если длина массива
равна 6, нам достаточно трех итераций, чтобы найти нужное число.
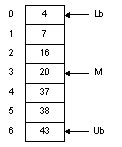
Рисунок 1.1 – Массив
Двоичный
поиск – очень мощный метод. Если, например, длина массива равна 1023, после
первого сравнения область сужается до 511 элементов, а после второй – до 255.
Легко посчитать, что для поиска в массиве из 1023 элементов достаточно 10 сравнений.
Кроме поиска
нам необходимо бывает вставлять и удалять элементы. К сожалению, массив плохо
приспособлен для выполнения этих операций. Например, чтобы вставить число 18 в
массив на рисунке 1.1, нам понадобится сдвинуть элементы A[3]… A[6]
вниз – лишь после этого мы сможем записать число 18 в элемент A[3].
Аналогичная проблема возникает при удалении элементов. Для повышения эффективности
операций вставки / удаления предложены связанные списки.
Иначе двоичный
поиск (бинарный поиск) называют поиском делением пополам. В большинстве случаев
процедура поиска применяется к упорядоченным данным (телефонный справочник,
библиотечные каталоги и пр.).
Односвязные
списки
На рисунке 1.2
те же числа, что и раньше, хранятся в виде связанного списка; слово «связанный»
часто опускают. Предполагая, что X и P являются указателями,
число 18 можно вставить в такой список следующим образом:
X->Next = P->Next;
P->Next = X;
Списки
позволяют осуществить вставку и удаление очень эффективно. Поинтересуемся,
однако, как найти место, куда мы будем вставлять новый элемент, т. е.
каким образом присвоить нужное значение указателю P. Увы, для поиска
нужной точки придется пройтись по элементам списка. Таким образом, переход к
спискам позволяет уменьшить время вставки / удаления элемента за счет
увеличения времени поиска.
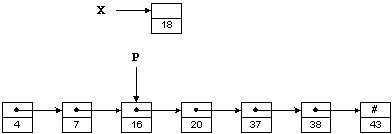
Рисунок 1. 2 – Односвязный список
Поиск в
бинарных деревьях
Мы
использовали двоичный поиск для поиска данных в массиве. Этот метод чрезвычайно
эффективен, поскольку каждая итерация вдвое уменьшает число элементов, среди
которых нам нужно продолжать поиск. Однако операции вставки и удаления
элементов не столь эффективны. Двоичные деревья позволяют сохранить
эффективность всех трех операций – если работа идет со «случайными» данными. В
этом случае время поиска оценивается как O (lg n). Наихудший
случай – когда вставляются упорядоченные данные. В этом случае оценка время
поиска – O(n).
Двоичное
дерево – это дерево, у которого каждый узел имеет не более двух наследников.
Пример бинарного дерева приведен на рисунке 1.5. Предполагая, что Key
содержит значение, хранимое в данном узле, мы можем сказать, что бинарное
дерево обладает следующим свойством: у всех узлов, расположенных слева от
данного узла, значение соответствующего поля меньше, чем Key, у всех
узлов, расположенных справа от него, – больше. Вершину дерева называют его
корнем. Узлы, у которых отсутствуют оба наследника, называются листьями. Корень
дерева на рисунке 1.3 содержит число 20, а листья – 4, 16, 37 и 43. Высота дерева
это длина наидлиннейшего из путей от корня к листьям. В нашем примере высота
дерева равна 2.
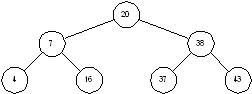
Рисунок 1.3 – Двоичное дерево
Чтобы найти в
дереве какое-то значение, мы стартуем из корня и движемся вниз. Например, для
поиска числа 16, мы замечаем, что 16 < 20, и потому идем влево.
При втором сравнении имеем 16 > 7, так что мы движемся вправо. Третья попытка
успешна – мы находим элемент с ключом, равным 16.
Каждое
сравнение вдвое уменьшает количество оставшихся элементов. В этом отношении
алгоритм похож на двоичный поиск в массиве. Однако, все это верно только в
случаях, когда наше дерево сбалансировано. На рисунке 1.4 показано другое
дерево, содержащее те же элементы. Несмотря на то, что это дерево тоже
бинарное, поиск в нем похож, скорее, на поиск в односвязном списке, время
поиска увеличивается пропорционально числу запоминаемых элементов.
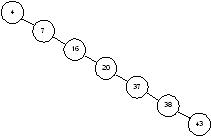
Рисунок 1.4 – Несбалансированное
бинарное дерево
Вставка и
удаление
Чтобы лучше
понять, как дерево становится несбалансированным, посмотрим на процесс вставки
пристальнее. Чтобы вставить 18 в дерево на рисунке 1.3 мы ищем это число. Поиск
приводит нас в узел 16, где благополучно завершается. Поскольку 18 > 16, мы попросту
добавляет узел 18 в качестве правого потомка узла 16 (рисунок 1.5).
Теперь мы
видим, как возникает несбалансированность дерева. Если данные поступают в
возрастающем порядке, каждый новый узел добавляется справа от последнего
вставленного. Это приводит к одному длинному списку. Обратите внимание: чем
более «случайны» поступающие данные, тем более сбалансированным получается дерево.
Удаления
производятся примерно так же – необходимо только позаботиться о сохранении
структуры дерева. Например, если из дерева на рисунке 1.5 удаляется узел 20,
его сначала нужно заменить на узел 37. Это даст дерево, изображенное на рисунок
1.6. Рассуждения здесь примерно следующие. Нам нужно найти потомка узла 20,
справа от которого расположены узлы с большими значениями. Таким образом, нам
нужно выбрать узел с наименьшим значением, расположенный справа от узла 20.
Чтобы найти его, нам и нужно сначала спуститься на шаг вправо (попадаем в узел
38), а затем на шаг влево (узел 37); эти двухшаговые спуски продолжаются, пока
мы не придем в концевой узел, лист дерева.
|
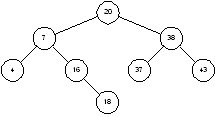
Рисунок 1.5 – Бинарное дерево после добавления узла 18
|
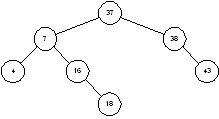
Рисунок 1.6 – Бинарное дерево после удаления узла 20
|
Разделенные
списки
Разделенные
списки – это связные списки, которые позволяют вам прыгнуть (skip) к
нужному элементу. Это позволяет преодолеть ограничения последовательного
поиска, являющегося основным источником неэффективного поиска в списках. В то
же время вставка и удаление остаются сравнительно эффективными. Оценка среднего
времени поиска в таких списках есть O (lg n). Для наихудшего случая
оценкой является O(n), но худший случай крайне маловероятен.
Идея, лежащая
в основе разделенных списков, очень напоминает метод, используемый при поиске
имен в адресной книжке. Чтобы найти имя, вы помечаете буквой страницу, откуда
начинаются имена, начинающиеся с этой буквы. На рисунке 1.6, например, самый
верхний список представляет обычный односвязный список. Добавив один «уровень»
ссылок, мы ускорим поиск. Сначала мы пойдем по ссылкам уровня 1, затем, когда
дойдем до нужного отрезка списка, пойдем по ссылкам нулевого уровня.
Эта простая
идея может быть расширена – мы можем добавить нужное число уровней. Внизу на
рисунке 1.6 мы видим второй уровень, который позволяет двигаться еще быстрее
первого. При поиске элемента мы двигаемся по этому уровню, пока не дойдем до
нужного отрезка списка. Затем мы еще уменьшаем интервал неопределенности,
двигаясь по ссылкам 1‑го уровня. Лишь после этого мы проходим по ссылкам
0‑го уровня.
Вставляя
узел, нам понадобится определить количество исходящих от него ссылок. Эта проблема
легче всего решается с использованием случайного механизма: при добавлении
нового узла мы «бросаем монету», чтобы определить, нужно ли добавлять еще слой.
Например, мы можем добавлять очередные слои до тех пор, пока выпадает «решка».
Если реализован только один уровень, мы имеем дело фактически с обычным списком
и время поиска есть O(n). Однако если имеется достаточное число
уровней, разделенный список можно считать деревом с корнем на высшем уровне, а
для дерева время поиска есть O (lg n).
Поскольку
реализация разделенных списков включает в себя случайный процесс, для времени
поиска в них устанавливаются вероятностные границы. При обычных условиях эти
границы довольно узки. Например, когда мы ищем элемент в списке из 1000 узлов,
вероятность того, что время поиска окажется в 5 раз больше среднего, можно оценить
как 1/ 1,000,000,000,000,000,000 (рисунок 1.7).
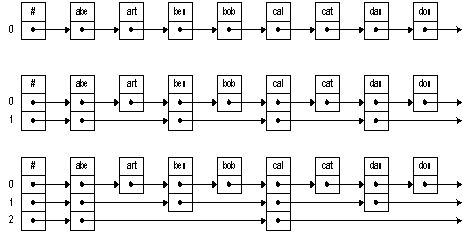
Рисунок 1.7 – Устройство разделенного списка
1.2.3
Оценки времени исполнения
Для оценки эффективности
алгоритмов можно использовать разные подходы. Самый бесхитростный – просто
запустить каждый алгоритм на нескольких задачах и сравнить время исполнения.
Другой способ – оценить время исполнения. Например, мы можем утверждать, что
время поиска есть O(n) (читается так: о большое от n).
Это означает, что при больших n время поиска не сильно больше, чем количество
элементов. Когда используют обозначение O(), имеют в виду не точное
время исполнения, а только его предел сверху, причем с точностью до постоянного
множителя. Когда говорят, например, что алгоритму требуется время порядка O(n2),
имеют в виду, что время исполнения задачи растет не быстрее, чем квадрат
количества элементов. Чтобы почувствовать, что это такое, посмотрите таблицу 1.1,
где приведены числа, иллюстрирующие скорость роста для нескольких разных
функций. Скорость роста O(log2n) характеризует алгоритмы
типа двоичного поиска.
Таблица 1.1 – Скорость роста нескольких функций O()
|
n
|
log2 n
|
n log2 n
|
n1.25
|
n2
|
| 1 |
0 |
0 |
1 |
1 |
| 16 |
4 |
64 |
32 |
256 |
| 256 |
8 |
2,048 |
1,024 |
65,536 |
| 4,096 |
12 |
49,152 |
32,768 |
16,777,216 |
| 65,536 |
16 |
1,048,565 |
1,048,476 |
4,294,967,296 |
| 1,048,476 |
20 |
20,969,520 |
33,554,432 |
1,099,301,922,576 |
| 16,775,616 |
24 |
402,614,784 |
1,073,613,825 |
281,421,292,179,456 |
Если считать,
что числа в таблице 1.1 соответствуют микросекундам, то для задачи с 1048476
элементами алгоритму со временем работы O(log2 n) потребуется 20 микросекунд,
алгоритму со временем работы O(n1.25) – порядка 33
секунд, алгоритму со временем работы O(n2) – более 12
дней. В нижеследующем тексте для каждого алгоритма приведены соответствующие O‑оценки.
Более точные формулировки и доказательства можно найти в [12], [15].
Как мы
видели, если массив отсортирован, то искать его элементы необходимо с помощью
двоичного поиска. Однако не забудем, что массив должен быть отсортированным! В
следующем разделе мы исследует разные способы сортировки массива. Оказывается,
эта задача встречается достаточно часто и требует заметных вычислительных
ресурсов, поэтому сортирующие алгоритмы исследованы вдоль и поперек, известны
алгоритмы, эффективность которых достигла теоретического предела.
Связанные списки
позволяют эффективно вставлять и удалять элементы, но поиск в них
последователен и потому отнимает много времени. Имеются алгоритмы, позволяющие
эффективно выполнять все три операции.
1.2.4
Сортировки
Сортировка
вставками
Один из
простейших способов отсортировать массив – сортировка вставками. В обычной
жизни мы сталкиваемся с этим методом при игре в карты. Чтобы отсортировать
имеющиеся у вас карты, вы вынимаете карту, сдвигаете оставшиеся карты, а затем
вставляете карту на нужное место. Процесс повторяется до тех пор, пока хоть
одна карта находится не на месте. Как среднее, так и худшее время для этого
алгоритма – O(n2). Дальнейшую информацию можно получить
в книге Кнута [4].
На рисунке 1.8
(a) мы вынимаем элемент 3. Затем элементы, расположенные выше, сдвигаем
вниз – до тех пор, пока не найдем место, куда нужно вставить 3. Это процесс
продолжается на рисунке 1.8 (b) для числа 1. Наконец, на рисунке 1.8 (c)
мы завершаем сортировку, поместив 2 на нужное место.
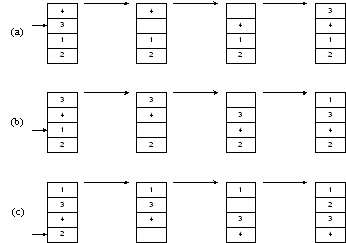
Рисунок 1.8 – Сортировка вставками
Если длина
нашего массива равна n, нам нужно пройтись по n – 1 элементам.
Каждый раз нам может понадобиться сдвинуть n – 1 других элементов. Вот
почему этот метод требует довольно-таки много времени.
Сортировка
вставками относится к числу методов сортировки по месту. Другими словами, ей не
требуется вспомогательная память, мы сортируем элементы массива, используя
только память, занимаемую самим массивом. Кроме того, она является устойчивой
если среди сортируемых ключей имеются одинаковые, после сортировки они остаются
в исходном порядке.
Сортировка
с помощью включения
Кто играл в
карты, процедуру сортировки включениями осуществлял многократно. Как правило,
после раздачи карт игрок, держа карты веером в руке, переставляет карты с места
на место, стремясь их расположить по мастям и рангам, например, сначала все
тузы, затем короли, дамы и т. д. Элементы (карты) мысленно делятся на
уже «готовую последовательность» и неправильно расположенную последовательность.
Теперь на каждом шаге, начиная с i = 2, из неправильно расположенной
последовательности извлекается очередной элемент и перекладывается в готовую
последовательность на нужное место.
for i:=2 to N do
begin
x:=a[i];
<включение х на соответствующее место готовой последовательности
a[1],…, a[i]>
End
Поиск
подходящего места можно осуществить одним из методов поиска в массиве,
описанным выше. Затем х либо вставляется на свободное место, либо сдвигает
вправо на один индекс всю левую сторону. Схематично представим алгоритм для
конкретного примера:
Исходные
элементы 23 34 12 13 9
i=2 23 34 12 13 9
i=3 12 23 34 13 9
i=4 12 13 23 34 9
i=5 9 12 13 23 34
В алгоритме
поиск подходящего места осуществляется как бы просеиванием x: при
движении по последовательности и сравнении с очередным a[j]. Затем х
либо вставляется на свободное место, либо а[j] сдвигается вправо и
процесс как бы «уходит» влево.
Сортировка
с помощью прямого включения
Элементы массива,
начиная со второго, последовательно берутся по одному и включаются на нужное
место в уже упорядоченную часть массива, расположенную слева от текущего
элемента а[i]. В отличие от стандартной ситуации включения элемента в заданную
позицию массива, позиция включаемого элемента при этом неизвестна. Определим
её, сравнивая в цикле поочерёдно a[i] с a [i‑1],
а [i‑2],… до тех пор, пока не будет найден первый из
элементов меньший или равный а[i], либо не будет достигнут левый
конец массива. Поскольку операции сравнения и перемещения чередуются друг с
другом, то этот способ часто называют просеиванием или погружением. Очевидно,
что программа, реализующая описанный алгоритм, должна содержать цикл в цикле.
program sortirovka_l;
(*сортировка включением по линейному поиску*)
const N=5;
type item= integer;
var a: array [0..n] of item; i, j: integer; x: item;
begin (*задание искомого массива*)
for i:=1 to N do begin write ('введите элемент a [', i, ']=');
readln (a[i])
end;
for i:=1 to N do begin write (a[i], ' ');
end;
writeln;
(*алгоритм сортировки включением*)
for i:=2 to n do
begin
x:=a[i]; j:=i; a[0]:=x; (*барьер*)
while x<a [j-l] do
begin
a[j]:=a [j‑1]; j:=j‑1;
end;
a[j]:=x;
{for k:=1 to n do write (a[k], ' ') end;
writeln;} end;
(*вывод отсортированного массива*)
for i:=1 to N do
begin
write (a[i], ' '); end;
readln; end.
В
рассмотренном примере программы для анализа процедуры пошаговой сортировки можно
рекомендовать использовать трассировку каждого прохода по массиву с целью
визуализации его текущего состояния. В тексте программы в блоке непосредственного
алгоритма сортировки в фигурных скобках находится строка, которая при удалении
скобок выполнит требуемое (параметр k необходимо описать в
разделе переменных – var k:integer).
Вернемся к
анализу метода прямого включения. Поскольку готовая последовательность уже
упорядочена, то алгоритм улучшается при использовании алгоритма поиска делением
пополам. Такой способ сортировки называют методом двоичного включения.
program
sortirovka_2;
(*сортировка
двоичным включением*)
const
N=5;
type
item= integer;
var
a: array [0..n] of item; i, j, m, L, R: integer; x: item;
begin
(*задание элементов массива*)
for
i: – l to N do begin write ('введите элемент a [', i, ']= ');
readln
(a[i]);
end;
for
i:=1 to N do begin write (a[i], ' ');
end;
writeln;
(*алгоритм
сортировки двоичным включением*)
for
i:=2 to n do
begin
x:=a[i];
L:=l; R:^i;
while
L<R do
begin
m:=(L+R)
div 2; if a [m] <=x then L:=m+1 else R:=m;
end;
for
j:=i downto R+l do a[j]:=a [j‑1];
a[R]:=x; end;
(* вывод
отсортированного массива*)
for
i: – l to N do
begin
write (a[i], ' ');
end;
readln;
end.
Сортировка
Шелла
Метод,
предложенный Дональдом Л. Шеллом, является неустойчивой сортировкой по месту.
Эффективность метода Шелла объясняется тем, что сдвигаемые элементы быстро
попадают на нужные места. Среднее время для сортировки Шелла равняется O(n1.25),
для худшего случая оценкой является O(n1.5). Дальнейшие
ссылки см. в книге Кнута [4].
На рисунке 1.8
приведен пример сортировки вставками. Мы сначала вынимали 1, затем сдвигали 3 и
5 на одну позицию вниз, после чего вставляли 1. Таким образом, нам требовались
два сдвига. В следующий раз нам требовалось два сдвига, чтобы вставить на
нужное место 2. На весь процесс нам требовалось 2+2+1=5 сдвигов.
На рисунке 1.9
иллюстрируется сортировка Шелла. Мы начинаем, производя сортировку вставками с
шагом 2. Сначала мы рассматриваем числа 3 и 1: извлекаем 2, сдвигаем 3 на 1
позицию с шагом 2, вставляем 2. Затем повторяем то же для чисел 5 и 2: извлекаем
2, сдвигаем вниз 5, вставляем 2 и т. д. Закончив сортировку с шагом
2, производим ее с шагом 1, т. е. выполняем обычную сортировку вставками.
Всего при этом нам понадобится 1 + 1+ 1 = 3 сдвига. Таким образом, использовав
вначале шаг, больший 1, мы добились меньшего числа сдвигов.
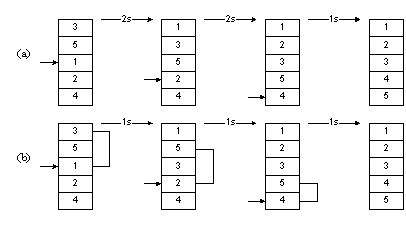
Рисунок 1.9 – Сортировка Шелла
Можно
использовать самые разные схемы выбора шагов. Как правило, сначала мы сортируем
массив с большим шагом, затем уменьшаем шаг и повторяем сортировку. В самом
конце сортируем с шагом 1. Хотя этот метод легко объяснить, его формальный
анализ довольно труден. В частности, теоретикам не удалось найти оптимальную
схему выбора шагов. Кнут провел множество экспериментов и следующую формулу
выбора шагов (h) для массива длины N.
Вот несколько
первых значений h:
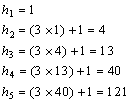 . .
Чтобы
отсортировать массив длиной 100, прежде всего, найдем номер s, для
которого hs ³ 100. Согласно приведенным цифрам, s = 5.
Нужное нам значение находится двумя строчками выше. Таким образом,
последовательность шагов при сортировке будет такой: 13–4–1. Ну, конечно, нам
не нужно хранить эту последовательность: очередное значение h находится
из предыдущего.
Сортировка
с помощью дерева
Улучшенный
метод сортировки выбором с помощью дерева. Метод сортировки прямым выбором
основан на поисках наименьшего элемента среди неготовой последовательности.
Усилить метод можно запоминанием информации при сравнении пар элементов. Этого
добиваются определением в каждой паре меньшего элемента за n/2 сравнений.
Далее n/4 сравнений позволит выбрать меньший из пары уже выбранных
меньших и т. д. Получается двоичное дерево сравнений после n‑1
сравнений, у которого в корневой вершине находится наименьший элемент, а любая
вершина содержит меньший элемент из двух приходящих к ней вершин. Одним из
алгоритмов, использующих структуру дерева, является сортировка с помощью
пирамиды (Дж. Вильямс) [3]. Пирамида определяется как последовательность
ключей hL…hR, такая, что
hi<=h2i и hi<=h2i+l, для i=L,…,
R/2.
Другими
словами, пирамиду можно определить как двоичное дерево заданной высоты h,
обладающее тремя свойствами:
• каждая
конечная вершина имеет высоту h или h‑1;
• каждая
конечная вершина высоты h находится слева от любой конечной вершины
высоты h‑1;
• значение
любой вершины больше значения любой следующей за ней вершины.
Рассмотрим
пример пирамиды, составленной по массиву 27 9 14 8 5 11 7 2 3.
У пирамиды n=9
вершин, их значения можно разместить в массиве а, но таким образом, что
следующие за вершиной из a[i] помещаются в a[2i] и a [2i+l].
Заметим, что а[6]=11, а[7]=7, а они следуют за элементом а[3]=14
(рисунок 1.10).

Рисунок 1.10
Пирамида
Очевидно, что
если 2i > n, тогда за вершиной a[i] не следуют
другие вершины, и она является конечной вершиной пирамиды.
Процесс
построения пирамиды для заданного массива можно разбить на четыре этапа:
1) меняя
местами а[1] и а[n], получаем 3 9 14 8 5 11 7 2 27;
2) уменьшаем n
на 1, т. е. n=n‑1, что эквивалентно удалению вершины 27 из
дерева;
3)
преобразуем дерево в другую пирамиду перестановкой
нового корня
с большей из двух новых, непосредственно следующих за ним вершин, до тех пор,
пока он не станет больше, чем обе вершины, непосредственно за ним следующие;
4) повторяем
шаги 1, 2, 3 до тех пор, пока не получим n=1.
Для алгоритма
сортировки нужна процедура преобразования произвольного массива в пирамиду (шаг
3). В ней необходимо предусмотреть последовательный просмотр массива справа
налево с проверкой одновременно двух условий: больше ли а[n], чем a[2i]
и a [2i+l].
Полный текст
программы приведен ниже.
program
sortirovka_5;
(*улучшенная
сортировка выбором – сортировка с помощью дерева*)
const
N=8;
type
item= integer;
var
a: array [1..n] of item; k, L, R: integer; x: item;
procedure
sift (L, R:integer);
var
i, j: integer; x, y: item;
begin
i:=L; j:=2*L; x:=a[L]; if (j<R) and (a[j]<a [j+1]) then j:=j+1;
while
(j<=R) and (x<a[j]) do begin y:=a[i]; a[i]:=a[j];
a[j]:=y;
a[i]:=a[j]; i:=j; j:=2*j;
if
(j<R) and (a[j]<a [j+1]) then j:=j+1;
end;
end;
begin
(*задание
искомого массива*)
for
k:=1 to N do begin
write ('Bведите элемент a [', k,
']=');
readln
(a[k]);
end;
for
k:=1 to N do begin
write (a[k], ' ');
end;
writeln;
(*алгоритм
сортировки с помощью дерева*)
(*построение пирамиды*)
L:=(n
div 2) +1; R:=n; while L>1 do begin L:=L‑1; SIFT (L, R);
end;
(*сортировка*)
while
R>1 do begin x:=a[l]; a[l]:=a[R]; a[R]:=x; R:=R‑1; SIET (1, R);
end;
(*вывод отсортированного массива*) for k:=1 to
N do begin write (a[k], ' ');
end;
readln;
end.
Сортировка
с помощью обменов
1‑ый
вариант.
Соседние элементы массива сравниваются и при необходимости меняются местами до
тех пор, пока массив не будет полностью упорядочен. Повторные проходы массива
сдвигают каждый раз наименьший элемент оставшейся части массива к левому его
концу. Метод широко известен под названием «пузырьковая сортировка» потому, что
большие элементы массива, подобно пузырькам, «всплывают» на соответствующую
позицию. Основной фрагмент программы содержит два вложенных цикла, причём
внутренний цикл удобнее выбрать с шагом, равным -1 [8]:
for
i: =2 to n do
for
j:=n downto i do
if
a [j‑1]>a[j] then
begin
{обмен}x:=a [j‑1]; a [j‑1]:=a[j];
a[j]:=xend;
2‑ой
вариант.
Пузырьковая сортировка является не самой эффективной, особенно для
последовательностей, у которых «всплывающие» элементы находятся в крайней
правой стороне. В улучшенной (быстрой) пузырьковой сортировке предлагается
производить перестановки на большие расстояния, причем двигаться с двух сторон.
Идея алгоритма заключается в сравнении элементов, из которых один берется слева
(i = 1), другой – справа (j = n). Если a[i] <=
a[j], то устанавливают j = j – 1 и проводят следующее
сравнение. Далее уменьшают j до тех пор, пока a[i] > a[j].
В противном случае меняем их местами и устанавливаем i = i + 1.
Увеличение i продолжаем до тех пор, пока не получим a[i]
> a[j]. После следующего обмена опять уменьшаем j.
Чередуя уменьшение j и увеличение i, продолжаем этот процесс с
обоих концов до тех пор, пока не станет i = j. После этого этапа возникает
ситуация, когда первый элемент занимает ему предназначенное место, слева от
него младшие элементы, а справа – старшие [8].
Далее
подобную процедуру можно применить к левой и правой частям массива и т. д.
Очевидно, что характер алгоритма рекурсивный. Для запоминания ведущих левого и
правого элементов в программе необходимо использовать стек.
Характерной
чертой алгоритмов сортировки с помощью обмена является обмен местами двух
элементов массива после их сравнения друг с другом. В так называемой
«пузырьковой сортировке» проводят несколько проходов по массиву, в каждом из
которых повторяется одна и та же процедура: сравнение двух последовательно
стоящих элементов и их обмен местами в порядке меньшинства (старшинства).
Подобная процедура сдвигает наименьшие элементы к левому концу массива.
program
sortirovka_6;
(*сортировка
прямым обменом – пузырьковая сортировка*)
const
N=5;
type
item= integer;
var
a: array [1..n] of item; i, j: integer; x: item;
begin
(*задание искомого массива*)
for
i:=1 to N do begin
write ('введи элемент a [', i,
']= ');
readln
(a[i]);
end;
for
i:=1 to N do begin
write (a[i], ' ');
end;
writeln;
(*алгоритм
пузырьковой сортировки*)
for
i:=2 to n do for j:=n downto i do begin
if
a [j‑1]>a[j] then begin x:=a [j‑1]; a [j‑1]:=a[j]; a[j]:=x;
end;
end;
(*вывод
отсортированного массива*)
for
i:=1 to N do begin
write (a[i], ' ');
end;
readln;
end.
Представленную
программу можно легко улучшить, если учесть, что если после очередного прохода
перестановок не было, то последовательность элементов уже упорядочена, т. е.
продолжать проходы не имеет смысла. Если чередовать направление последовательных
просмотров, алгоритм улучшается. Такой алгоритм называют «шейкерной» сортировкой.
program
sortirovka_7;
(*сортировка
прямым обменом – шейкерная сортировка*)
const
N=5;
type
item= integer;
var
a: array [1..n] of item; i, j, k, L, R: integer; x: item;
begin
(*задание искомого массива*)
for
i: =1 to N do begin write ('введи элемент а [', i, '] =
');
readln
(a[i]);
end;
for
i:=1 to N do begin write (a[i], ' ');
end;
writeln;
(*алгоритм
шейкерной сортировки*)
L:
=2; R:=n; k:=n;
repeat
for
j:=R downto L do begin
if
a [j-l]>a[j] then begin x:=a [j‑1]; a [j‑1]:=a[j];
a[j]:=x;
k:=-j
end;
end;
L:=k+1;
for
j:=L to R do begin
if
a [j-l]>a[j] then begin x:=a [j-l]
a [j-l]:=a[j];
a[j]:=x; k:=j
end;
end;
R:=k‑1;
until L>R;
(*вывод
отсортированного массива*)
for i:=l to N
do
begin
write (a[i], ' ');
end;
readln;
end.
Быстрая
сортировка
Хотя идея
Шелла значительно улучшает сортировку вставками, резервы еще остаются. Один из
наиболее известных алгоритмов сортировки – быстрая сортировка, предложенная Ч. Хоаром.
Метод и в самом деле очень быстр, недаром по-английски его так и величают QuickSort
[6].
Этому методу
требуется O (n log2n) в среднем и O(n2)
в худшем случае. К счастью, если принять адекватные предосторожности, наихудший
случай крайне маловероятен. Быстрый поиск не является устойчивым. Кроме того,
ему требуется стек, т. е. он не является и методом сортировки на месте.
Алгоритм
разбивает сортируемый массив на разделы, затем рекурсивно сортирует каждый
раздел. В функции Partition один из элементов массива выбирается в
качестве центрального. Ключи, меньшие центрального, следует расположить слева
от него, те, которые больше – справа.
int
function Partition (Array A, int Lb, int Ub);
begin
select
a pivot from A[Lb]… A[Ub];
reorder
A[Lb]… A[Ub] such that:
all
values to the left of the pivot are £ pivot
all
values to the right of the pivot are ³ pivot
return
pivot position;
end;
procedure
QuickSort (Array A, int Lb, int Ub);
begin
if
Lb < Ub then
M
= Partition (A, Lb, Ub);
QuickSort
(A, Lb, M – 1);
QuickSort
(A, M + 1, Ub);
end;
На рисунке 1.11
(а) в качестве центрального выбран элемент 3. Индексы начинают изменяться с
концов массива. Индекс i начинается слева и используется для выбора
элементов, которые больше центрального, индекс j начинается справа и
используется для выбора элементов, которые меньше центрального. Эти элементы
меняются местами – см. рисунок 1.11 (b). Процедура QuickSort рекурсивно
сортирует два подмассива, в результате получается массив, представленный на
рисунке 1.11 (c).
В процессе
сортировки может потребоваться передвинуть центральный элемент. Если нам
повезет, выбранный элемент окажется медианой значений массива, т. е.
разделит его пополам. Предположим на минутку, что это и в самом деле так.
Поскольку на каждом шаге мы делим массив пополам, а функция Partition, в конце
концов, просмотрит все n элементов, время работы алгоритма есть O (n
log2n).
В качестве
центрального функция Partition может попросту брать первый элемент (A[Lb]).
Все остальные элементы массива мы сравниваем с центральным и передвигаем либо
влево от него, либо вправо. Есть, однако, один случай, который безжалостно
разрушает эту прекрасную простоту. Предположим, что наш массив с самого начала
отсортирован. Функция Partition всегда будет получать в качестве
центрального минимальный элемент и потому разделит массив наихудшим способом: в
левом разделе окажется один элемент, соответственно, в правом останется Ub
Lb элементов.
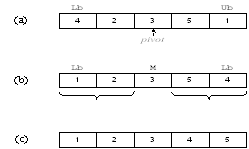
Рисунок 1.11 – Пример работы алгоритма Quicksort
Таким
образом, каждый рекурсивный вызов процедуры quicksort всего лишь
уменьшит длину сортируемого массива на 1. В результате для выполнения
сортировки понадобится n рекурсивных вызовов, что приводит к времени
работы алгоритма порядка O(n2). Один из способов
побороть эту проблему – случайно выбирать центральный элемент. Это сделает
наихудший случай чрезвычайно маловероятным.
Сортировка
с помощью прямого выбора
При
сортировке этим методом выбирается наименьший элемент массива и меняется
местами с первым. Затем выбирается наименьший среди оставшихся n – 1
элементов и меняется местами со вторым и т. д. до тех пор, пока не
останется один самый больший элемент. Основной фрагмент программы может
выглядеть так [11]:
for i:=l to n‑1
do
begin
k:
=i;
x:=a[i];
for
j:=i+1 to n do
if
a[j]<x then begin k:=j; x:=a[k] end;a[k]:=a[i]; a[i]: =xend;
k – величина, хранящая
индекс элемента, участвующего в операции обмена.
Сортировка
файлов
Главная
особенность методов сортировки последовательных файлов в том, что при их
обработке в каждый момент непосредственно доступна одна компонента (на которую
указывает указатель). Чаще процесс сортировки протекает не в оперативной
памяти, как в случае с массивами, а с элементами на внешних носителях («винчестере»,
дискете и т. п.).
Понять
особенности сортировки последовательных файлов на внешних носителях позволит
следующий пример [9].
Предположим,
что нам необходимо упорядочить содержимое файла с последовательным доступом по
какому-либо ключу. Для простоты изучения и анализа сортировки условимся, что
файл формируем мы сами, используя, как и в предыдущем разделе, некоторый массив
данных. Его же будем использовать и для просмотра содержимого файла после
сортировки. В предлагаемом ниже алгоритме необходимо сформировать вспомогательный
файл, который позволит осуществить следующую процедуру сортировки. Сначала
выбираем из исходного файла первый элемент в качестве ведущего, затем извлекаем
второй и сравниваем с ведущим. Если он оказался меньше, чем ведущий, то
помещаем его во вспомогательный файл, в противном случае во вспомогательный
файл помещается ведущий элемент, а его замещает второй элемент исходного файла.
Первый проход заканчивается, когда аналогичная процедура коснется всех последовательных
элементов исходного файла. Ведущий элемент заносится во вспомогательный файл
последним. Теперь необходимо поменять местами исходный и вспомогательный файлы.
После nil проходов в исходном файле данные будут размещены в упорядоченном
виде.
program
sortirovka_faila_1;
{сортировка
последовательного файла}
const
n=8; type item= integer;
var
a: array [1..n] of item;
i,
k: integer; x, y: item;
fl,
f2: text; {file of item};
begin
{задание искомого массива}
for
i:=1 to N do begin write ('введи элемент а ['i, '] = ');
readln
(a[i]);
end;
writeln;
assign (fl, 'datl.dat'); rewrite(fl);
assign
(f2, 'dat2.dat'); rewrite(f2);
{формирование последовательного файла}
for
i:=1 to N do begin writeln (fl, a[i]);
end;
{алгоритм
сортировки с использованием вспомогательного файла}
for
k:=1 to (n div 2) do
begin {извлечение
из исходного файла и запись во вспомогательный}
reset(fl);
readln (fl, x);
for
i:=2 to n do begin readln (fl, y);
if
x>y then writeln (f2, y) else begin writeln (f2, x); x:=y;
end;
end;
writeln
(f2, x);
{извлечение
из вспомогательного файла и запись в исходный}
rewrite(fl);
reset(f2); readln (f2, x);
for
i:=2 to n do begin readln (f2, y);
if
x>y then writeln (fl, y) else begin writeln (fl, x); x:=y;
end;
end;
writeln
(fl, x); rewrite(f2); end;
(вывод результата)
reset(fl);
for
i:=1 to N do readln (fl, a[i]);
for
i:=1 to N do begin write (a[i], ' ');
end;
close(fl);
close(f2); readln;
end.
По сути можно
в программе обойтись без массива а [1..n]. В качестве упражнения
попытайтесь создать программу, в которой не используются массивы.
Многие методы
сортировки последовательных файлов основаны на процедуре слияния, означающей
объединение двух (или более) последовательностей в одну, упорядоченную с
помощью повторяющегося выбора элементов (доступных в данный момент). В
дальнейшем (чтобы не осуществлять многократного обращения к внешней памяти),
будем рассматривать вместо файла массив данных, обращение к которому можно
осуществлять строго последовательно. В этом смысле массив представляется как
последовательность элементов, имеющая два конца, с которых можно считывать данные.
При слиянии можно брать элементы с двух концов массива, что эквивалентно
считыванию элементов из двух входных файлов.
Идея слияния
заключается в том, что исходная последовательность разбивается на две половины,
которые сливаются вновь в одну упорядоченными парами, образованными двумя элементами,
последовательно извлекаемыми из этих двух подпоследовательностей. Вновь повторяем
деление и слияние, но упорядочивая пары, затем четверки и т. д. Для
реализации подобного алгоритма необходимы два массива, которые поочередно (как
и в предыдущем примере) меняются ролями в качестве исходного и вспомогательного.
Если объединить
эти два массива в один, разумеется, двойного размера, то программа упрощается.
Пусть индексы i и j фиксируют два входных элемента с концов
исходного массива, k и L – два выходных, соответствующих
концам вспомогательного массива. Направлением пересылки (сменой ролей массивов)
удобно управлять с помощью булевской переменной, которая меняет свое значение
после каждого прохода, когда элементы a1…, an
движутся на место ani….a2n и
наоборот. Необходимо еще учесть изменяющийся на каждом проходе размер объединяемых
упорядоченных групп элементов. Перед каждым последующим проходом размер
удваивается. Если считать, что количество элементов в исходной последовательности
не является степенью двойки (для процедуры разделения это существенно), то необходимо
придумать стратегию разбиения на группы, размеры которых q и r могут не совпадать с
ведущим размером очередного прохода. В окончательном виде алгоритм сортировки
слиянием представлен ниже.
program
sortirovka__faila_2;
{сортировка
последовательного файла слиянием}
const N=8;
type
item= integer;
var
a: array [1..2*n] of item;
i,
j, k, L, t, h, m, p, q, r: integer; f: boolean;
begin
{задание искомого массива}
for
i:=1 to N do begin
write ('введи элемент а [', i, '] = ');
readln
(a[i]);
end;
writeln;
{сортировка слиянием}
f:=true;
p:=1;
repeat
h:=1; m:=n; if f
then begin
i:=1;
j:=n; k:=n+1; L:=2*n
end
else
begin k:=1; L:=n; i:=n+1; j:=2*n
end;
repeat
if
m>=p then q:=p else q:=m; m:=m-q;
if
m>=p then r:=p else r:=m; m:=m-r;
while
(q< >0) and (r<>0) do
begin
if
a[i}<a[j] then
begin
a[k]:=a[i]; k:=k+h; i:=i+1; q:=q‑1
end
else
begin
a[k]:=a[j]; k:=k+h; j:=j‑1; r:=r‑1
end;
end;
while
r>0 do
begin
a[k]:=a[j]; k:=k+h; j:=j‑1; r:=r‑1;
end;
while
q>0 do begin
a[k]:=a[i];
k: – k+h; i:=i+1; q:=q‑1;
end;
h:=-h;
t:=k; k:=L; L:=t;
until
m=0;
f:=not(f);
p:=2*p;
until
p>=n;
if
not(f) then for i:=1 to n do a[i]:=a [i+n];
{вывод результата}
for
i:=1 to N do begin
write (a[i], ' ');
end;
readln;
end.
Рассмотренные
два предыдущих примера иллюстрируют большие проблемы сортировки внешних файлов,
если в них часты изменения элементов, например, удаления, добавления,
корректировки существующих.
В подобных
ситуациях эффективными становятся алгоритмы, в которых обрабатываемые элементы
представляются в виде структур данных, удобных для поиска и сортировки. В
качестве структур данных можно отметить, в частности, линейные списки, очереди,
стеки, деревья и т. п. О них было рассказано в предыдущем разделе.
1.3 Практическая часть
1.3.1 Содержание
отчёта по практической работе
1
Задание
по варианту.
2
Теоретическая
часть (краткое описание используемого метода и необходимые пояснения для
понимания функционирования приложения на Delphi).
3
Блок-схема
для процедуры, реализующей основной алгоритм.
4
Код
программы.
5
Результаты
расчёта.
Примечание: а) подбор исходных
данных выполнить самостоятельно; б) если в варианте не указан метод, то выбрать
наиболее подходящий для решения поставленной задачи (предварительно согласовать
с преподавателем).
1.3.2
Приложение на Delphi, в котором представлена работа некоторых методов
сортировки и поиска
Графический
интерфейс представлен на рисунке 1.14.
Рисунок 1.14 – Форма
uses
wseme1;
procedure
TForm1. Button16Click (Sender: TObject);
begin
close;
end;
procedure
TForm1. Button1Click (Sender: TObject);
var i:integer;
begin
//
генерируем множество, состоящее из случайных чисел
Randomize;
for
i:=0 to StringGrid1. RowCount do
StringGrid1.
Cells [0, i]:=IntToStr (Random(10000)+1);
end;
procedure
TForm1. FormCreate (Sender: TObject);
begin
Button1.
Click();
end;
procedure
TForm1. Edit1Exit (Sender: TObject);
begin
//
проверяем заполнено ли поле
if
edit1. Text='' then begin
MessageDlg
('Введите число не больше 15', mtError,
[mbOk, mbCancel], 0);
exit;
end else
StringGrid1.
RowCount:=strtoint (edit1. Text);
StringGrid2.
RowCount:=strtoint (edit1. Text);
end;
procedure
TForm1. Button3Click (Sender: TObject);
var
n,
minimum, j, i, obmen:integer;
a:array
[1..15] of integer;
begin
n:=strtoint
(edit1. Text);
//
задание массива
for
j:=1 to n do
a[j]:=StrToInt
(StringGrid1. Cells [0, j‑1]);
for
j:=1 to n do begin
// номер минимального
элемента
minimum:=j;
for
i:=j+1 to n do if a[i] < a [minimum] then minimum:=i;
// запоминание
минимального элемента
obmen:=a[j];
a[j]:=a[minimum];
a[minimum]:=obmen;
// вывод отсортированного
массива
for i:=0 to n
do
stringgrid2.
Cells [0, j‑1]:=inttostr (a[j]);
end;
end;
procedure
TForm1. Button4Click (Sender: TObject);
var
n,
obmen, i, j:integer;
a:array
[1..15] of integer;
colicobmen:boolean;
begin
n:=strtoint
(edit1. Text);
//
задание массива
for
i:=1 to n do
a[i]:=
StrToInt (StringGrid1. Cells [0, i‑1]);
//
сортировка массива
repeat
colicobmen:=FALSE;
for
j:=1 to n‑1 do
if
a[j] > a [j+1] then
begin
obmen:=a[j];
a[j]:=a
[j+1];
a [j+1]:=obmen;
colicobmen:=TRUE;
end;
//
вывод массива
for
i:=1 to n do
stringgrid2.
Cells [0, i‑1]:=inttostr (a[i]);
until
not colicobmen;
stringgrid2.
Cells [0, i‑1]:=inttostr (a[i]);
end;
procedure
TForm1. Button5Click (Sender: TObject);
var
a:array
[1..15] of integer;
i,
j, m, L, R, n, x:integer;
begin
n:=strtoint
(edit1. Text);
//
задание массива
for
i:=1 to n do
a[i]:=StrToInt
(StringGrid1. Cells [0, i‑1]);
// алгоритм сортировки
двоичным включением
for i:=2 to n
do
begin
x:=a[i];
L:=1;
R:=i;
while
L<R do begin
m:=(L+R)
div 2;
if
a[m]<=x then L:=m+1 else R:=m;
end;
for
j:=i downto R+1 do a[j]:=a [j‑1];
a[R]:=x;
end;
//
вывод отсортированного массива
for
i:=1 to n do
stringgrid2.
Cells [0, i‑1]:=inttostr (a[i]);
end;
procedure
TForm1. Button6Click (Sender: TObject);
const
t=15;
var
n:integer;
a:array
[1..15] of integer;
i,
j, k, s:integer;
x:integer;
m:1..t;
h:array
[1..t] of integer;
begin
n:=strtoint
(edit1. Text);
//
задание массива
for
i:=1 to n do
a[i]:=StrToInt
(StringGrid1. Cells [0, i‑1]);
// алгоритм Шелла
h[1]:=9;
h[2]:=5;
h[3]:=3;
h[4]:=1;
for
m:=1 to t do
begin
k:=h[m];
s:=-k;
//
барьеры для каждого шага
for
i:=k+1 to n do
begin
x:=a[i];
j:=i-k;
if
s=0 then s:=-k;
s:=s+1;
a[s]:=x;
while
x<a[j] do begin a [j+k]:=a[j];
j:=j-k;
end;
a [j+k]:=x;
end;
end;
//
вывод отсортированного массива
for
i:=1 to n do
stringgrid2.
Cells [0, i‑1]:=inttostr (a[i]);
end;
procedure
TForm1. Button7Click (Sender: TObject);
var
n:integer;
a:array
[1..15] of integer;
L,
R, x, k:integer;
procedure
sift (L, R:integer);
var
i,
j:integer;
x,
y:integer;
begin
i:=L;
j:=2*L;
x:=a[L];
if
(j<R) and (a[j]<a [j+1]) then j:=j‑1;
while
(j<=R) and (x<a[j]) do begin y:=a[i];
a[i]:=a[j];
a[j]:=y;
a[i]:=a[j];
i:=j;
j:=2*j;
if
(j<R) and (a[j]<a [j+l]) then j:=j+l;
end;
end;
begin
n:=strtoint
(edit1. Text);
// задание искомого
массива
for k:=1 to n
do
a[k]:=StrToInt
(StringGrid1. Cells [0, k‑1]);
// алгоритм сортировки с
помощью дерева
//
построение пирамиды
L:=(n
div 2)+1;
R:=n;
while
L>1 do begin L:=L‑1;
SIFT
(L, R);
end;
//
сортировка
while
R>1 do begin x:=a[l];
a[l]:=a[R];
a[R]:=x;
R:=R‑1;
SIFT
(1, R);
end;
// вывод
отсортированного массива
for k:=1 to n
do
stringgrid2.
Cells [0, k‑1]:=inttostr (a[k]);
end;
procedure
TForm1. Button8Click (Sender: TObject);
var
n:integer;
a:array
[1..15] of integer;
i,
j, x:integer;
begin
n:=strtoint
(edit1. Text);
//
задание искомого массива
for
i:=1 to n do
a[i]:=StrToInt
(StringGrid1. Cells [0, i‑1]);
//
алгоритм пузырьковой сортировки
for
i:=2 to n do for j:=n downto i do begin
if
a [j‑1]>a[j] then begin x:=a [j‑1];
a [j‑1]:=a[j];
a[j]:=x;
end;
end;
//
вывод отсортированного массива
for i:=1 to n
do
stringgrid2.
Cells [0, i‑1]:=inttostr (a[i]);
end;
procedure
TForm1. Button9Click (Sender: TObject);
var
n:integer;
a:array
[1..15] of integer;
i,
j, k, L, R, x: integer;
begin
n:=strtoint
(edit1. Text);
// задание искомого
массива
for i:=1 to n
do
a[i]:=StrToInt
(StringGrid1. Cells [0, i‑1]);
// алгоритм шейкерной
сортировки
L:=2;
R:=-n;
k:=n;
repeat
for
i:=2 to n do
for
j:=-R downto L do begin
if
a [j‑1]>a[j] then begin x:=a [j‑1];
a [j‑1]:=a[j];
a[j]:=x;
k:=j;
end;
end;
L:=k+1;
for
i:=2 to n do
for
j:=L to R do begin
if
a [j‑1]>a[j] then begin x:=a [j‑1] end else
a [j‑1]:=a[j];
a[j]:=x;
k:=-j;
end;
R:=k‑1;
until L>R;
//
вывод отсортированного массива
for
i:=1 to n do
stringgrid2.
Cells [0, i‑1]:=inttostr (a[i]);
end;
procedure
TForm1. Button10Click (Sender: TObject);
var
n:integer;
a:array
[1..15] of integer;
i:integer;
procedure
sort (L, R: integer);
var
i,
j:integer;
x,
y:integer;
begin
i:=L;
j:=R;
x:=a[(L+R)
div 2];
repeat
while
a[i]<x do i:=i+l;
while
x<a[j] do j:=j‑1;
if
i<=j then begin y:=a[i];
a[i]:=a[j];
a[j]:=y;
i:=i+l;
j:=j-l;
end;
until
i>j;
if
L<j then SORT (L, j);
if
i<R then SORT (i, R);
end;
begin
n:=strtoint
(edit1. Text);
//
задание искомого массива
for
i:=1 to n do
a[i]:=StrToInt
(StringGrid1. Cells [0, i‑1]);
// алгоритм быстрой
сортировки
//
рекурсивная процедура
SORT (1, n);
//
вывод отсортированного массива
for i:=1 to n
do
stringgrid2.
Cells [0, i‑1]:=inttostr (a[i]);
end;
procedure
TForm1. Button17Click (Sender: TObject);
begin
AboutBox.showmodal;
end;
end.
1.3.3 Пример выполнения
Задание: заданы два одномерных
массива А и В, содержащие по n элементов каждый.
Объединить эти два массива в один, исключив повторяющиеся элементы. Считать,
что массивы А и В отсортированы по убыванию.
Теоретическое
описание метода
Метод
пузырька, как таковой, не требует глубокого рассмотрения. Смысл метода
заключается в том, что мы находим в определённой области максимальный (или
минимальный элемент) и помещаем его в начало исследуемой области, далее
уменьшаем область поиска на 1 и повторяем те же действия, не имеет худшего
случая, всегда O(n2).
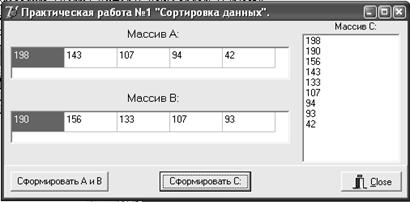
Рисунок 1.15
Форма с результатами расчета
Код
программы на Delphi:
const
n=5;
var
a:array
[1..n] of Byte;
b:array
[1..n] of Byte;
c:
array of Byte;
i:byte;
implementation
procedure
TForm1. Button1Click (Sender: TObject);
var
m, x:byte;
begin
randomize;
for
i:=1 to n do begin
a[i]:=random(200);
b[i]:=random(200);
end;
for
m:=n downto 2 do begin
for
i:=1 to m‑1 do begin
if
a[i]<a [i+1] then begin
x:=a[i];
a[i]:=a
[i+1];
a [i+1]:=x;
end;
if
b[i]<b [i+1] then begin
x:=b[i];
b[i]:=b
[i+1];
b [i+1]:=x;
end;
end;
end;
for
i:=1 to n do begin
StringGrid1.
Cells [i – 1,0]:=IntToStr (a[i]);
StringGrid2.
Cells [i – 1,0]:=IntToStr (b[i]);
end;
end;
procedure
TForm1. Button2Click (Sender: TObject);
label
m1;
var
k, l, x:byte;
begin
k:=1;
l:=1;
x:=0;
SetLength
(c, 1);
while
(k<=n) or (l<=n) do begin
m1:
if a[k]>b[l] then begin
x:=x+1;
SetLength
(c, x);
c [x‑1]:=a[k];
k:=k+1;
goto
m1;
end;
if
a[k]<b[l] then begin
x:=x+1;
SetLength
(c, x);
c [x‑1]:=b[l];
end;
l:=l+1;
end;
For
i:=0 to high(c) do ListBox1. Items. Add (IntToStr(c[i]));
end;
end.
1.3.4 Варианты
заданий
Варианты 1
27 имеют пояснения к выполнению решений в [7].
1) Для
заданного массива A размером n требуется выполнить проверку на
упорядоченность. Результат присвоить переменной строкового типа (сделать вывод,
каким именно образом упорядочен массив, если он окажется упорядоченным: по
возрастанию, по убыванию, по неубыванию, по невозрастанию). Пояснения в [7],
стр. 245.
2) Выполнить
поиск заданного элемента в упорядоченном массиве. Пояснения в [7], стр. 246.
3) Требуется
объединить два упорядоченных по возрастанию массива A и B одного
размера N (N – заданное натуральное число) в один массив размером
2N также упорядоченный по возрастанию. Пояснения в [7], стр. 247.
4) Требуется
объединить два упорядоченных по убыванию массива A и B одного размера
N (N – заданное натуральное число) в один массив размером 2N
также упорядоченный по убыванию. Пояснения в [7], стр. 247.
5) Требуется
объединить два массива A и B одного размера N (N
заданное натуральное число) в один массив размером 2N, упорядоченный по
возрастанию. [7], стр. 247.
6) Требуется
объединить два массива A и B одного размера N (N
заданное натуральное число) в один массив размером 2N, упорядоченный по
убыванию. Пояснения в [7], стр. 247.
7) Требуется
объединить два упорядоченных массива A и B одного размера N
(N – заданное натуральное число) по возрастанию в один массив размером 2N,
упорядоченный по неубыванию. [7], стр. 247; [9], стр. 75.
8) Требуется
объединить два упорядоченных массива A и B одного размера N
(N – заданное натуральное число) по убыванию в один массив размером 2N,
упорядоченный по невозрастанию. Пояснения в [7], стр. 247.
9) Требуется
определить количество совпадающих элементов двух упорядоченных по убыванию
массивов A и B. Размеры массивов не обязательно одинаковые.
Пояснения в [7], стр. 248.
10) Требуется
определить количество совпадающих элементов двух неупорядоченных массивов A
и B. Размеры массивов не обязательно одинаковые. Пояснения в [7], стр. 248.
11) Требуется
определить количество совпадающих элементов двух упорядоченных по убыванию
массивов A и B. Размеры массивов одинаковые. Пояснения в [7],
стр. 248.
12) Требуется
определить количество совпадающих элементов двух неупорядоченных массивов A
и B. Размеры массивов одинаковые. Пояснения в [7], стр. 248.
13) Требуется
определить количество совпадающих элементов двух упорядоченных по возрастанию
массивов A и B. Размеры массивов не обязательно одинаковые.
Пояснения в [7], стр. 248.
14) Фамилии
участников соревнований по фигурному катанию после короткой программы
расположены в порядке, соответствующем занятому месту. Составить список
участников в порядке их стартовых номеров для произвольной программы (участники
выступают в порядке, обратном занятым местам). Пояснения в [7], стр. 255.
15) Японская
радиокомпания провела опрос 250 радиослушателей по трём вопросам:
1) Какое
животное Вы связываете с Японией и японцами?
2) Какая
черта характера присуща японцам больше всего?
3) Какой
неодушевлённый предмет или понятие Вы связываете с Японией?
Большинство
опрошенных прислали ответы на все или на часть вопросов. Составить программу
получения первых пяти наиболее часто встречающихся ответов по каждому вопросу и
доли (в%) каждого такого ответа. Предусмотреть необходимость сжатия столбца
ответов в случае отсутствия ответов на некоторые вопросы. Пояснения в [7], стр. 264.
16) В памяти
компьютера хранится список фамилий абонентов в алфавитном порядке их номеров
телефонов. Составить программу, обеспечивающую быстрый поиск фамилии абонента
по номеру телефона. Пояснения в [7], стр. 266.
17) В памяти
ЭВМ хранятся списки номеров телефонов и фамилий абонентов, упорядоченные по
номерам телефонов, для каждого из пяти телефонных узлов города. Один телефонный
узел включает несколько АТС (не более 10). Номера АТС (первые две цифры номера
телефона), относящихся к каждому телефонному узлу, также хранятся в памяти ЭВМ.
Составить программу, обеспечивающую быстрый поиск фамилии абонента по заданному
номеру телефона (количественные данные по телефонной сети не относятся к г. Москва).
Пояснения в [7], стр. 266
18) Требуется
упорядочить заданный одномерный массив A размером N (N
заданное натуральное число) по возрастанию методом пузырька.
19) Требуется
упорядочить заданный одномерный массив A размером N (N
заданное натуральное число) по убыванию методом пузырька.
20) Требуется
упорядочить заданный одномерный массив A размером N (N
заданное натуральное число) по возрастанию методом Шелла.
21) Требуется
упорядочить заданный одномерный массив A размером N (N
заданное натуральное число) по убыванию методом Шелла.
22) Требуется
упорядочить заданный одномерный массив A размером N (N
заданное натуральное число) по возрастанию методом прямого включения. Пояснения
в [9], стр. 78 – стр. 80.
23) Требуется
упорядочить заданный одномерный массив A размером N (N
заданное натуральное число) по возрастанию методом прямого выбора. Пояснения в
[9], стр. 79 – стр. 80.
24) Требуется
упорядочить заданный одномерный массив A размером N (N
заданное натуральное число) по убыванию методом прямого включения. Пояснения в
[9], стр. 78.
25) Требуется
упорядочить заданный одномерный массив A размером N (N
заданное натуральное число) по убыванию методом прямого выбора. Пояснения в
[9], стр. 79 – стр. 80.
26) Требуется
упорядочить заданный одномерный массив A размером N (N
заданное натуральное число) по убыванию методом сортировки прямым обменом
(шейкерная сортировка).
27) Требуется
упорядочить заданный одномерный массив A размером N (N
заданное натуральное число) по убыванию методом улучшенной сортировки
разделением (быстрая сортировка с рекурсией).
28) Составить
программу сортировки, используя деревья сортировки (улучшенная сортировка
выбором – сортировка с помощью дерева).
29) Составить
программу сортировки в файле (сортировка последовательного файла).
30) Составить
программу сортировки в файле (сортировка последовательного файла слиянием).
31) Дан
одномерный массив А, состоящий из N элементов (N – заданное
натуральное число). Если элементы массива А составляют строго монотонную
последовательность, то все положительные элементы массива заменить единицей,
иначе отсортировать массив по возрастанию.
32) Дан
одномерный массив А, состоящий из N элементов (N – заданное
натуральное число). Если имеется хотя бы одна пара совпадающих элементов, то
упорядочить элементы этого массива по неубыванию, иначе записать элементы этого
массива в обратном порядке.
33) Заданы
два одномерных целочисленных массива А и В, состоящие из N
элементов каждый (N – заданное натуральное число). Объединить элементы
этих двух массивов в один и упорядочить их по неубыванию, удалив из него
элементы, являющиеся четными положительными числами.
34) Дан
одномерный целочисленный массив А, состоящий из N элементов (N
заданное натуральное число). Присвоить переменной F значение 1, если
элементы массива составляют строго возрастающую последовательность, F=-1,
если строго убывающую, F=2, если элементы массива составляют
знакочередующуюся последовательность, F=0, если она не является строго
монотонной или знакочередующейся.
35) Дан
одномерный массив А, состоящий из N элементов (N – заданное
натуральное число). Упорядочить массив А по неубыванию, воспользовавшись
следующим алгоритмом сортировки. Отыскивается максимальный элемент и
переносится в конец. Затем этот алгоритм применяется ко всем элементам кроме последнего
и т. д.
36) Даны два
одномерных целочисленных массива А и В, состоящих из N
элементов каждый (N – заданное натуральное число). Сформировать массив,
элементы которого являются пересечением указанных массивов, и расположить его
элементы по неубыванию. Одинаковые значения заносить только один раз. Если
пресечение массивов есть пустое множество, то выдать соответствующее текстовое
сообщение.
37) Даны два
одномерных целочисленных массива А и В, состоящих из N
элементов каждый, N – заданное натуральное число. Сформировать массив С,
элементы которого являются объединением указанных массивов, и расположить его
элементы по неубыванию. Одинаковые значение заносить только один раз.
38) Дан
одномерный массив А, состоящий из N элементов (N – заданное
натуральное число). Присвоить переменной F=1, если элементы массива составляют
строгую возрастающую арифметическую прогрессию, и F=-1, если строго
убывающую арифметическую прогрессию.
39) Дан
одномерный целочисленный массив А, состоящий из N элементов, N
заданное натуральное число. Пусть МАХ – наибольшее, а MIN
наименьшее значения среди элементов массива. Составить одномерный массив В
из простых чисел из сегмента [MIN, МАХ], которые не являются элементами
массива А, записав его элементы в порядке неубывания. Если таких
элементов нет, то выдать соответствующее текстовое сообщение.
40) Каждый из
12 магазинов имеет свой список товаров с известными ценами и в известном
количестве. Число товаров в каждом списке различно и заранее не определено.
Подсчитать, на какую сумму денег имеет товаров каждый магазин, расположив
список в порядке убывания этой суммы.
41) Каждая из
30 групп студентов имеет свой процент успеваемости (от 0 % до 100 %).
Составить список номеров групп, которым необходимо повысить успеваемость до
среднего уровня. Список расположить в порядке убывания процента успеваемости
этих групп.
42) В
магазине имеются товары различных наименований. В течение дня каждый из М
покупателей (М – заданное число) сообщил о своем намерении приобрести
определенное количество товара одного из наименований. Требуется определить
суммарный спрос на товары каждого наименования, расположив товары в порядке
убывания дневного спроса на них.
43) Опросили
200 подписчиков. Каждый из них назвал три любимые газеты. Напечатать
пронумерованный список первых 10 наиболее популярных газет, расположив названия
газет в списке в порядке уменьшения числа поданных за них голосов.
Предусмотреть, что каждый из опрошенных должен назвать три разные газеты, а
общее число названных газет может быть как больше, так и меньше 10.
44) Каждый из
X магазинов в течение
месяца работал Di дней (N и Di – заданные числа, где i=l,
2,…, X). Известна прибыль каждого магазина в каждый день его работы.
Необходимо напечатать упорядоченный по месячным доходам список названий
магазинов, имеющих прибыль в пересчете на один день работы выше средней дневной
прибыли по всем магазинам.
45) В
гостинице N этажей по M номеров на этаже (N и М заданы, а
нумерация гостиничных номеров сплошная). Требуется для каждого номера ввести
его стоимость и информацию о том, свободен он, занят или забронирован, а затем
получить ведомости всех свободных, занятых и забронированных номеров в порядке
возрастания их стоимости с указанием стоимости проживания, этажа и номера гостиницы.
46) В
итоговой таблице первого круга футбольного чемпионата, каждая из N
команд (N и названия команд заданы) представлена количеством забитых и
пропущенных голов в каждой из встреч с противниками. Перечислить команды,
которые в сумме забили в чужие ворота голов больше, чем пропустили в свои, в
порядке убывания разности забитых и пропущенных голов.
47) По
результатам опроса прошлого года известен список 10 политических деятелей в
порядке убывания их популярности. Проведен новый опрос. Каждый из N
журналистов (N – заданное число) назвал три различные фамилии из этого
списка. Требуется получить новый список в порядке убывания популярности
политических деятелей и показать место, которое занимал каждый деятель в
предыдущем опросе. Предусмотреть проверку: каждый из опрошенных журналистов
называл разные фамилии и только из имеющихся в старом списке.
48) Опросили
30 кинологов, каждый из которых 3 раза назвал одну породу собак или разные
породы собак в любом сочетании, как самую популярную (популярные) по его
мнению. Вывести на экран список пород, попавших в первую десятку в порядке
убывания популярности, с указанием числа полученных ими голосов опрошенных.
49) Каждая из
М библиотек района (М – задано) составляет заявку на приобретение
книг. Заявка содержит перечень книг, состоящий из не более 20 наименований.
Каждая библиотека в каждой строке заявки указывает название книги, фамилию
автора, а также количество экземпляров. Определить суммарный спрос на каждую из
указанных книг, и напечатать общий список книг в порядке убывания спроса.
50) 200
учеников шести школ города (номера школ заданы) принимают участие в
тестировании по математике. Правильные численные ответы к пяти предложенным
задачам даны. О каждом ученике известно: фамилия, номер школы и пять ответов на
задачи. Сведения об учениках не имеют определенной упорядоченности. Составить
списки учеников по школам, расположив в каждом списке фамилии в порядке
убывания количества решенных задач. Предусмотреть возможный ответ «не решил».
51) Каждое из
М садоводческих товариществ (М – заданное число) направляет на
базу свой список-заявку с указанием наименований требуемых и семян и их
количества в кг. Число наименований семян в заявке для каждого товарищества не
превышает 20‑ти. Составить суммарный запрос на базу, указав общее
необходимое количество семян каждого вида, расположив наименования в списке в
порядке убывания спроса.
52) В массив
размерности N (N – заданное натуральное число) ввести слова
длиной не более 15 символов каждое. Вывести на экран эти слова в порядке
увеличения их длины с указанием количества букв «i» в каждом из них.
Выполнить проверку вводимой информации.
53) Имеются
сведения о каждом рейсе Аэрофлота с номерами от 1 до 100: пункт назначения и
количество перевезенных пассажиров. Определить количество пунктов назначения и
построить списки номеров рейсов для каждого из них в порядке уменьшения числа
пассажиров, перевезенных этими рейсами.
54) Ввести в
массив N произвольных чисел (N – заданное натуральное число).
Отсортировать отрицательные числа по убыванию, положительные – по возрастанию,
оставив отрицательные на местах, принадлежащих отрицательным, а положительные
на местах, принадлежащих положительным. Постараться дополнительных массивов не
использовать. Вывести на экран исходный и полученный массивы.
55) Ввести
произвольные числа в два одномерных массива одинакового размера N (N
заданное натуральное число). Переставить элементы первого массива так, чтобы
его максимальный элемент находился на месте, расположения максимального
элемента из второго массива, а каждый очередной по убыванию элемент из первого
массива располагался на месте, соответствующем расположению очередного по
убыванию элемента второго массива. Напечатать модифицированный массив.
56) В массив
заданного размера N (от 3 до 10) ввести произвольные числа. Изменить
порядок следования элементов в нем на обратный отдельно до и отдельно после К-го
элемента массива (К задано). Напечатать модифицированный массив. При
вводе данных осуществить проверку.
57) В массив
заданного размера N (от 3 до 10) ввести произвольные числа. Не изменяя
состояния этого массива и используя лишь один дополнительный массив, напечатать
номера элементов исходного массива, соответствующие порядку убывания значений
элементов. При вводе данных осуществить проверку.
58) В два
одномерных массива одинакового размера N (N – заданное
натуральное число) ввести произвольные числа. Не изменяя исходных массивов,
сформировать из элементов первого массива третий массив так, чтобы максимальный
элемент первого массива в третьем находился на месте, соответствующем
расположению максимального во втором, а каждый очередной по убыванию элемент из
первого массива располагался в третьем на месте, соответствующем расположению
очередного по убыванию элемента второго массива. Напечатать все три массива.
59)
Напечатать в возрастающем порядке все четырехзначные натуральные числа, все
цифры которых являются соседями в натуральном ряду. Примерами таких чисел
являются 4756 и 7645. Найти количество и среднее арифметическое этих чисел.
60) Ввести
числовую матрицу размером NxM (N, M заданы). Найти
максимальный элемент среди расположенных в тех строках матрицы, которые
являются упорядоченными (либо по возрастанию, либо по убыванию), или сообщить,
что такого элемента нет.
1.4 Вопросы для самопроверки
1) Какими
свойствами обладает отношение частичного порядка? Приведите примеры этого
отношения.
2) Дайте
определение отношения линейного порядка.
3) Сформулируйте
постановку задачи сортировки.
4) В чём
заключается преимущество отсортированных (упорядоченных) данных?
5) Как
рассматривается задача сортировки с точки зрения программирования?
6) От каких
факторов зависит эффективность алгоритма сортировки?
7) Перечислите
наиболее часто используемые на практике методы поиска и сортировки.
8) Каким
образом могут быть представлены данные при поиске и сортировке?
9) Перечислите
основные операции при работе с данными.
10) В чём
заключается алгоритм линейного поиска?
11) В чём
заключается алгоритм бинарного поиска?
12) Опишите
кратко поиск в бинарных деревьях.
13) Какие
функции используются при оценке времени исполнения алгоритма?
14) В чём
заключается метод сортировки вставками?
15) В чём
заключается метод сортировки с помощью включения, прямого включения?
16) В чём
заключается метод Шелла?
17) Опишите
сортировку с помощью обменов.
18) Опишите
алгоритм быстрой сортировки, предложенный Ч. Хоаром (QuickSort).
Практическая работа № 2. Представление множеств в
компьютере
Цель работы:
изучение представлений множеств и отношений в программах, алгоритмов с
использованием множеств; представление множеств характеристическими векторами и
их практическая реализация.
2.1
Теоретическая часть
2.1.1 Множества
и операции над ними
Множество – это
совокупность объектов, называемых элементами множества. Например:
• {Эссекс,
Йоркшир, Девон};
• {2, 3, 5,
7, 11}.
В этом
примере элементы каждого множества заключены в фигурные скобки. Чтобы
обеспечить возможность ссылок, мы будем обозначать множества прописными
латинскими буквами. Например,
S = {3, 2, 11, 5, 7} – множество,
содержащее целые числа. Заметим, что множество S совпадает с одним из
множеств, выписанных выше, поскольку порядок, в котором записываются элементы
множества, значения не имеет.
В общем
случае запись а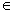 S
означает, что объект а – элемент множества S. Часто говорят, что а
принадлежит множеству S. Если объект а не принадлежит S,
то пишут: а S
означает, что объект а – элемент множества S. Часто говорят, что а
принадлежит множеству S. Если объект а не принадлежит S,
то пишут: а S. S.
В современных
языках программирования требуется, чтобы переменные объявлялись как
принадлежащие к определенному типу данных. Тип данных представляет собой
множество объектов со списком стандартных операций над ними. Определение типа
переменных равносильно указанию множества, из которого переменным присваиваются
значения [22].
Существует
несколько способов конструирования нового множества из двух данных. Опишем
коротко эти операции на множествах. Прежде всего, отметим, что все элементы
некоторых множеств принадлежали другим большим множествам. Например, все
элементы множества С = {0, 1, 4, 9, 16,…} содержатся в множестве
Z = {0, ±1, ±2, ±3,…}.
Рисунок 2.1
Диаграмма Венна подмножества А  S S
Объединением
двух множеств А и В называется множество
А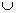 В = {х: х В = {х: х 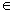 А или х А или х  В}. В}.
Оно состоит
из тех элементов, которые принадлежат либо множеству A, либо множеству В,
а возможно и обоим сразу. Диаграмма Венна объединения показана на рисунке 2.2.
Пересечением
двух множеств А и В называется множество
А  В = {х: х В = {х: х
 А и х А и х  В}. В}.
Оно состоит
из элементов, которые принадлежат как множеству А, так и множеству B.
Диаграмма Венна пересечения приведена на рисунке 2.3.
Рисунок 2.2
Диаграмма Венна Рисунок 2.3 – Диаграмма Венна для объединения множеств для
пересечения множеств
Дополнением
множества В до множества А называется
A\В = {х: х
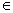 А и x А и x 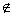 В}. В}.
Дополнение А
\ В состоит из всех элементов множества А, которые не принадлежат
В (см. рисунок 2.4). Если мы оперируем подмножествами некоего большого
множества U, мы называем U универсальным множеством для данной
задачи. На наших диаграммах Венна прямоугольник как раз и символизирует это
универсальное множество. Для подмножества А универсального множества U
можно рассматривать дополнение А до U, т. е. U \ А.
Поскольку в каждой конкретной задаче универсальное множество фиксировано,
множество U \ А обычно обозначают 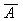 и
называют просто дополнением множества А. Таким образом, понимая, что мы
работаем с подмножествами универсального множества U можно записать и
называют просто дополнением множества А. Таким образом, понимая, что мы
работаем с подмножествами универсального множества U можно записать
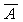 = {х: не
(х = {х: не
(х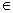 А)} ó А)} ó 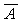 = {х: х = {х: х 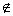 A}. A}.
Диаграмма
Венна дополнения изображена на рисунке 2.5.
|
Рисунок 2.4 – Диаграмма
Венна разности А \ В
|
Рисунок 2.5 – Диаграмма
Венна дополнения 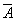
|
Симметрической
разностью двух множеств А и В называют множество А Δ В
= {х: (х 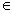 А и х А и х
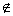 В) или (х В) или (х 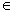 В и х В и х 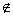 А)}. А)}.
Оно состоит
из всех тех и только тех элементов универсального множества, которые либо
принадлежат А и не принадлежат В, либо наоборот, принадлежат В,
но не А. Грубо говоря, симметрическая разность состоит из элементов,
лежащих либо в А, либо в В, но не одновременно. Диаграмма Венна,
иллюстрирующая симметрическую разность, начерчена на рисунке 2.6.
Рисунок 2.6
Диаграмма Венна симметрической разности А Δ В
2.1.2
Представление множеств и отношений в программах
В этом
параграфе рассматривается представление множеств в программах. Термин
«представление» (еще употребляют термин «реализация») применительно к
программированию означает следующее. Задать представление какого-либо объекта
(в данном случае множества) – значит, описать в терминах используемой системы
программирования структуру данных, используемую для хранения информации о
представляемом объекте, и алгоритмы над выбранными структурами данных, которые
реализуют присущие данному объекту операции. Предполагается, что в используемой
системе программирования доступны такие общеупотребительные структуры данных,
как массивы, структуры (или записи) и указатели. Таким образом, применительно к
множествам определение представления подразумевает описание способа хранения
информации о принадлежности элементов множеству и описание алгоритмов для
вычисления объединения, пересечения и других введенных операций [5].
Следует
подчеркнуть, что, как правило, один и тот же объект может быть представлен
многими разными способами, причем нельзя указать способ, который является
наилучшим для всех возможных случаев. В одних случаях выгодно использовать одно
представление, а в других – другое. Выбор представления зависит от целого ряда
факторов: особенностей представляемого объекта, состава и относительной частоты
использования операций в конкретной задаче и т. д. Умение выбрать
наиболее подходящее для данного случая представление является основой искусства
практического программирования. Хороший программист отличается тем, что он
знает много разных способов представления и умело выбирает наиболее подходящий.
Множества
и задачи информационного поиска
Наиболее
продуктивный подход к разработке эффективного алгоритма для решения любой
задачи – изучить ее сущность. Довольно часто задачу можно сформулировать на
языке теории множеств, относящейся к фундаментальным разделам математики. В
этом случае алгоритм ее решения можно изложить в терминах основных операций над
множествами. К таким задачам относятся и задачи информационного поиска, в которых
решаются проблемы, связанные с линейно упорядоченными множествами [1].
Многие
задачи, встречающиеся на практике, сводятся к одной или нескольким подзадачам,
которые можно абстрактно сформулировать как последовательность основных команд,
выполняемых на некоторой базе данных (универсальном множестве элементов). Например,
выполнение последовательности команд, состоящих из операций поиск, вставка,
удаление и минимум, составляет существенную часть задач поиска. Об этих и
других подобных командах и пойдет речь ниже [12].
Рассмотрим
несколько основных операций над множествами, типичных для задач информационного
поиска.
• Поиск (а;
S) определяет, принадлежит ли элемент а множеству S;
если а
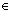 S, результат
операции – ответ «да»; в противном случае – S, результат
операции – ответ «да»; в противном случае –
ответ «нет».
• Вставка (а,
S) добавляет элемент а в множество S, то есть заменяет S
на S U {а}.
• Алгоритм
правильного обхода(S) печатает элементы множества S с
соблюдением
порядка.
• Удаление (a,
S) удаляет элемент а из множества S, то есть заменяет S
на S \ {а}.
• Объединение
(S1, S2, S3) объединяет множества S1 и S2, т. е.
строит
множество S3 = S1 U S2.
• Минимум (S)
выдает наименьший элемент множества S.
Следующая
операция – операция минимум(S). Для нахождения наименьшего элемента в
двоичном дереве поиска Т строится путь v0, vi,
, vp, где v0-корень дерева Т, vi
левый сын вершины vi-1 (i= 1,2,…, р),
а у вершины vp левый сын отсутствует. Ключ вершины vp, и является наименьшим
элементом в дереве Т. В некоторых задачах полезно иметь указатель на
вершину vy, чтобы обеспечить доступ к наименьшему элементу за
постоянное время.
Алгоритм
выполнения операции минимум(S) использует рекурсивную процедуру левый
сын(v), определяющую левого сына вершины v. Алгоритм и процедура
выглядят следующим образом.
Input
двоичное
дерево поиска Т для множества S
begin
if
T = 0 then output «дерево пусто»;
else
вызвать
процедуру левый сын(r)
(здесь r – корень
дерева Т);
минимум:=1
(v), где v – возврат процедуры левый сын;
end
Output ответ
«дерево пусто», если Т не содержит вершин;
минимум – наименьший
элемент дерева Т в противном случае.
Procedure
левый сын (v).
begin
if
v имеет левого сына w then return
левый сын (w)
else return v
end
Пример 2.1 Проследите работу
алгоритма минимум на дереве поиска, изображенном на рисунке 2.7.
Решение.
Дерево Т не пусто, следовательно, вызывается процедура левый сын (1).
Вершина 1
имеет левого сына – вершину 2, значит, вызывается процедура левый сын (2).
Вершина 2
имеет левого сына вершину 4, значит, вызывается процедура левый сын (4).
Вершина 4 не
имеет левого сына, поэтому вершина 4 и будет возвратом процедуры левый сын.
Ключом
вершины 4 является слово begin, следовательно, наименьшим элементом
дерева Т является значение минимум= begin.
Рисунок 2.7
Дерево поиска минимума S
Реализовать
операцию удаление (a, S) на основе бинарных поисковых деревьев тоже
просто. Допустим, что элемент а, подлежащий удалению, расположен в
вершине v. Возможны три случая:
• вершина v
является листом; в этом случае v просто удаляется
из дерева;
• у вершины v
в точности один сын; в этом случае объявляем отца вершины v отцом сына
вершины v, удаляя тем самым v из дерева (если v – корень,
то его сына делаем новым корнем);
• у вершины v
два сына; в этом случае находим в левом поддереве вершины v наибольший
элемент b, рекурсивно удаляем из этого поддерева вершину, содержащую b,
и присваиваем вершине v ключ b. (Заметим, что среди элементов,
меньших а, элемент b будет наибольшим элементом дерева. Кроме
того, вершина, содержащая b, может быть или листом, являющимся чьим-то
правым сыном, или иметь только левое поддерево.)
Ясно, что до
выполнения операции удаление (а, S) необходимо проверить, не является ли
дерево пустым и содержится ли элемент а в множестве S. Для этого
придется выполнить операцию поиск (а, S), причем, и в случае
положительного ответа необходимо выдать кроме ответа «да» и номер вершины, ключ
которой совпадает с a (далее ключ вершины v будем обозначать
через l(v)). Кроме этого, для реализации операции удаление (a,
S) требуется знать и номер вершины w, являющейся отцом вершины v.
Саму же рекурсивную процедуру удаление (а, S) можно реализовать так, как
показано ниже.
Procedure
удаление (а, S)
begin
if v – лист
then удалить v из Т
else
(2) if v
имеет только левого или только
правого сына
u then
(3) if v
имеет отца w then
назначить и сыном
w
else
сделать u
корнем дерева,
присвоив ему
номер v
else
найти в левом
поддереве v наибольший элемент b, содержащийся в вершине у;
(6)
return удаление (b, S);
(7)
l(v):=b;
end
Пример 2.2 Проследите за работой
алгоритма удаление (а, S) для двоичного дерева поиска S,
изображенного на рисунке 2.7, если a – это слово «if».
Решение.
Слово «if» расположено в корне с номером 1, у которого два сына (вершины
2 и 3), поэтому выполняем строку (5) алгоритма. Наибольшее слово, меньшее «if»
(лексикографически), расположенное в левом поддереве корня и находящееся в
вершине 2, – это end. Вызываем процедуру удаление (end, S).
Условие
строки (2) алгоритма выполняется, так как вершина 2 с ключом end имеет
только левого сына. Условие строки (3) не выполняется, так как удаляемая
вершина является корнем. Поэтому переходим к строке (4): делаем вершину 2
корнем, сыновьями которого становятся вершины 4 (левым) и 3 (правым). Работа
процедуры удаление (end, S) закончена.
Продолжаем
выполнение алгоритма (выполняем строку (7)): полагаем ключ вершины 1 равным «end»
(l (I):=end).
Полученное в
результате дерево изображено на рисунке 2.8.
Заметим, что
при работе рассмотренных алгоритмов необходимо находить сыновей, отца и ключ
заданной вершины двоичного дерева поиска. Это можно сделать довольно просто,
если дерево в памяти компьютера хранится в виде трех массивов: LEFTSON,
RIGHTSON и KEY. Эти массивы устроены следующим образом:
|
LEFTSON (i) =
|
 v, если v – левый
сын вершины i v, если v – левый
сын вершины i
*, если у вершины i левого
сына нет
|
|
RIGHTSONM (i) =
|
 v, если v – правый
сын вершины i v, если v – правый
сын вершины i
*, если у вершины i
правого сына нет
|
key(i) = l(i)
ключ вершины i.
Рисунок 2.8
Результат работы алгоритма удаление (а, S) для двоичного дерева поиска S
Например,
бинарное поисковое дерево, изображенное на рисунке 2.7, может быть представлено
в виде таблицы 2.1.
Таблица 2.1
Представление бинарного поискового дерева в виде таблицы
|
I
|
LEFTSON |
RIGHTSON |
KEY |
| 1 |
2 |
3 |
if
|
| 2 |
4 |
* |
end
|
| 3 |
* |
6 |
then
|
| 4 |
* |
5 |
begin
|
| 5 |
* |
* |
else
|
| 6 |
* |
* |
while
|
Правила
поиска сыновей и ключа заданной вершины следуют из определения массивов.
Определение отца заданной вершины состоит в нахождении строки массивов LEFTSON
или RIGHTSON, в которой находится номер заданной вершины. Например,
отцом вершины 4 является вершина 2, так как число 4 находится во второй строке
массива LEFTSON.
Объединение
множеств
Обратимся
теперь к объединению множеств, то есть к операции объединение (S1, S2,
S3).
Если
множества S1 и S2 линейно упорядочены, то естественно требовать
такого порядка и от их объединения. Один из возможных способов объединения
состоит в последовательном выполнении описанной выше операции вставка для
добавления каждого элемента одного множества в другое. При этом, очевидно,
операцию вставка предпочтительнее выполнять над элементами меньшего множества с
целью сокращения времени на объединение. Отметим, что такой способ работы подходит
как для непересекающихся, так и для пересекающихся множеств.
Во многих
задачах объединяются непересекающиеся множества. Это упрощает процесс, так как
исчезает необходимость каждый раз проверять, содержится ли добавляемый элемент
в множестве, либо удалять повторяющиеся экземпляры одного и того же элемента из
S3.
Процедура
объединения непересекающихся множеств применяется, например, при построении
минимального остовного дерева в данном нагруженном графе.
Рассмотрим
алгоритм объединения непересекающихся множеств на основе списков. Будем
считать, что элементы объединяемых множеств пронумерованы натуральными числами
1,2,…. n. Кроме того, предположим, что имена множеств – также
натуральные числа. Это не ограничивает общности, поскольку имена множеств можно
просто пронумеровать натуральными числами.
Представим
рассматриваемые множества в виде совокупности линейных связанных списков. Такую
структуру данных можно организовать следующим образом.
Сформируем
два массива R и next размерности n, в которых R(i)
имя множества, содержащего элемент i, a next(i) указывает номер
следующего элемента массива R, принадлежащего тому же множеству, что и
элемент i. Если i – последний элемент какого-то множества, то положим
next(i) = 0. Для указателей на первые элементы каждого множества
будем использовать массив list, число элементов которого равно числу
рассматриваемых в задаче множеств, и элемент которого list(j)
содержит номер первого элемента множества с именем j в массиве R.
Кроме того,
сформируем массив size, каждый элемент которого size(j) содержит количество
элементов множества с именем j.
Будем
различать внутренние имена множеств, содержащиеся в массиве к, и внешние
имена, получаемые множествами в результате выполнения операции объединение.
Соответствие между внутренними и внешними именами множеств можно установить с
помощью массивов Ехт-NAME и INT-NAME. Элемент массива EXT-NAME(j)
содержит внешнее имя множества, внутреннее имя которого есть j, а
INT-NAME(k) – внутреннее имя множества, внешнее имя которого есть к.
Пример 2.3 Используя только что
определенные массивы, опишите множества {1,3,5,7}, {2,4.8}, {6} с внешними
именами 1, 2, 3 и внутренними именами 2, 3, 1 соответственно.
Решение.
Прежде всего, отметим, что общее количество элементов всех множеств равно
восьми. Поэтому размерность массивов R и next будет n = 8.
Кроме того, напомним, что номера элементов массивов list, SIZE, Ехт-NAME
и значения элементов массива R – это внутренние имена множеств, а
массива INT-NAME внешние.
Алгоритм
выполнения операции объединение (S1, S2, S3) состоит в добавлении к списку
элементов большего из множеств S1 и S2 элементов меньшего множества и
присвоение полученному множеству внешнего имени S3. При этом вычисляется также
размер построенного множества S3.
Объединение (i,
j, к)
Input
i, j – внешние
имена объединяемых множеств
(пусть размер
i меньше размера j);
массивы R, NEXT,
LIST, SIZE, ЕХТ-NAME,
INT-NAME;
begin
A:=INT-NAME(i);
B:=INT-NAME(j);
element:=LIST(A);
while
element <> 0 do
begin
R(element):=B;
last:=element;
element:=NEXT(element)
end
NEXT(last):=LIST(B);
LIST(B):=LIST(A);
SIZE(B):=SIZE(B)
+ SIZE(A);
INT-NAME(K):=B;
EXT-NAME(B):=k
End
Объединение
множеств i, j с внешним именем k.
В процессе
работы алгоритм совершает следующие действия:
1) определяет
внутренние имена множеств i и j;
2) определяет
начало списка элементов меньшего множества;
3) просматривает
список элементов меньшего множества и изменяет соответствующие элементы массива
R на внутреннее имя большего множества;
4) объединяет
множества путем подстановки меньшего множества перед большим;
5) присваивает
новому множеству внешнее имя k.
Заметим, что
время выполнения операции объединения двух множеств с помощью рассмотренного
алгоритма пропорционально мощности меньшего множества.
2.1.3 Алгоритмы
генерации множеств
Реализация
операций над подмножествами заданного универсума U
Пусть
универсум U – конечный, и число элементов в нем не превосходит
разрядности ЭВМ: мощность |U| < n. Элементы универсума
нумеруются: U = {u1,…, un}.
Подмножество А универсума U представляется кодом (машинным словом
или битовой шкалой) С, в котором:
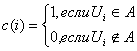
где С(i)
это i‑й разряд кода С.
Код
пересечения множеств А и В есть поразрядное логическое
произведение кода множества А и кода множества В. Код объединения
множеств А и В есть поразрядная логическая сумма кода множества А
и кода множества В. Код дополнения множества А есть инверсия кода
множества А. В большинстве ЭВМ для этих операций есть соответствующие
машинные команды. Таким образом, операции над небольшими множествами выполняются
весьма эффективно.
Если мощность
универсума превосходит размер машинного слова, но не очень велика, то для
представления множеств используются массивы битовых шкал. В этом случае
операции над множествами реализуются с помощью циклов по элементам массива [23].
Генерация
всех подмножеств универсума
Во многих
переборных алгоритмах требуется последовательно рассмотреть все подмножества
заданного множества. В большинстве компьютеров целые числа представляются
кодами в двоичной системе счисления, причем число 2k – 1 представляется кодом,
содержащим k единиц. Таким образом, число 0 является представлением пустого
множества 0, число 1 является представлением подмножества, состоящего из
первого элемента, и т. д. Следующий тривиальный алгоритм перечисляет
все подмножества n‑элементного множества (представлен в
паскале-подобном коде, описание в [23]).
Алгоритм 1.1:
Алгоритм генерации всех подмножеств n‑элементного множества
Вход: n
 0 – мощность
множества 0 – мощность
множества
Выход:
последовательность кодов подмножеств i
for
i from 0 to 2n – 1 do
yield i
end for
Обоснование: Алгоритм
выдает 2n различных целых чисел, следовательно, 2n различных
кодов.
С увеличением
числа n увеличивается количество двоичных разрядов, необходимых для его
представления. Самое большое (из генерируемых) число 2n‑1 требует
для своего представления ровно n разрядов. Таким образом, все
подмножества генерируются, причем ровно по одному разу.
Во многих
переборных задачах требуется рассмотреть все подмножества некоторого множества
и найти среди них то, которое удовлетворяет заданному условию. При этом
проверка условия часто может быть весьма трудоемкой и зависеть от состава
элементов очередного рассматриваемого подмножества. В частности, если очередное
рассматриваемое подмножество незначительно отличается по набору элементов от
предыдущего, то иногда можно воспользоваться результатами оценки элементов,
которые рассматривались на предыдущем шаге перебора. В таком случае, если
перебирать множества в определенном порядке, можно значительно ускорить работу
переборного алгоритма. [5]
Алгоритм
построения бинарного кода Грея
Данный
алгоритм генерирует последовательность всех подмножеств n‑элементного
множества, причем каждое следующее подмножество получается из предыдущего
удалением или добавлением одного элемента.
Алгоритм 1.2:
Алгоритм построения бинарного кода Грея Вход: n 0 – мощность множества 0 – мощность множества
Выход:
последовательность кодов подмножеств В
В: array
[l..n] of 0..1 {битовая шкала для представления подмножеств}
for
i from 1 to n do
B[i]: = 0 {инициализация}
end for
yield В {пустое
множество}
for
i from I to 2n – 1 do
p: = Q(i) {определение
элемента, подлежащего добавлению или удалению}
B[р]: = 1 – В[р]
{добавление или удаление элемента}
yield В {очередное
подмножество} end for
proc Q(i) {количество
2 в разложении i на множители + 1} q: = l; j: = i while j четно do
j:=j/2;
q: = q + l end while return q end proc
Обоснование
Для n
= 1 искомая последовательность кодов суть 0,1. Пусть есть искомая
последовательность кодов В1,…,  для
n = к. Тогда последовательность кодов B10,…, для
n = к. Тогда последовательность кодов B10,…, 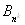 0, 0, 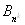 1, …. B11
будет искомой последовательностью для n = к + 1. Действительно, в
последовательности B10,…, 1, …. B11
будет искомой последовательностью для n = к + 1. Действительно, в
последовательности B10,…, 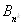 0, 0,
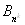 1,…, В11
имеется 2k+1 кодов, они все различны и соседние различаются ровно в
одном разряде по строению. Именно такое построение и осуществляет данный алгоритм.
На нулевом шаге алгоритм выдает правильное подмножество В (пустое).
Пусть за первые 2k – 1 шагов алгоритм выдал последовательность значений В.
При этом В [k + 1] = В [k + 2] = • • • = В[n] = 0. На 2 k‑ом шаге разряд В
[k + 1] изменяет свое значение с 0 на 1. После этого будет повторена
последовательность изменений значений В [1. k] в обратном порядке, поскольку
Q (2k + m) = Q (2k – m) для 1,…, В11
имеется 2k+1 кодов, они все различны и соседние различаются ровно в
одном разряде по строению. Именно такое построение и осуществляет данный алгоритм.
На нулевом шаге алгоритм выдает правильное подмножество В (пустое).
Пусть за первые 2k – 1 шагов алгоритм выдал последовательность значений В.
При этом В [k + 1] = В [k + 2] = • • • = В[n] = 0. На 2 k‑ом шаге разряд В
[k + 1] изменяет свое значение с 0 на 1. После этого будет повторена
последовательность изменений значений В [1. k] в обратном порядке, поскольку
Q (2k + m) = Q (2k – m) для 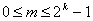
Пример 2.4
Таблица 2.5
Протокол выполнения алгоритма 1.2 для п = 3
| i |
Р |
|
В |
|
|
|
|
0 |
0 |
0 |
| 1 |
1 |
0 |
0 |
1 |
| 2 |
2 |
0 |
1 |
1 |
| 3 |
1 |
0 |
1 |
0 |
| 4 |
3 |
1 |
1 |
0 |
| 5 |
1 |
1 |
1 |
1 |
| 6 |
2 |
1 |
0 |
1 |
| 7 |
1 |
1 |
0 |
0 |
Представление
множеств упорядоченными списками
Если универсум
очень велик (или бесконечен), а рассматриваемые подмножества универсума не
очень велики, то представление с помощью битовых шкал не является эффективным с
точки зрения экономии памяти. В этом случае множества обычно представляются
списками элементов. Элемент списка при этом представляется записью с двумя
полями: информационным и указателем на следующий элемент. Весь список представляется
указателем на первый элемент.
elem = record
i: info; {информационное
поле}
n: elem {указатель
на следующий элемент} end record
При таком
представлении трудоемкость операции 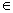 составит
O(n), а трудоемкость операций составит
O(n), а трудоемкость операций 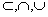 составит
О(nm), где n и m – мощности участвующих в операции
множеств. составит
О(nm), где n и m – мощности участвующих в операции
множеств.
Если элементы
в списках упорядочить, например, по возрастанию значения поля i, то
трудоемкость всех операций составит О(n). Эффективная реализация
операций над множествами, представленными в виде упорядоченных списков,
основана на весьма общем алгоритме, известном как алгоритм типа слияния.
1
1 1
1 2 1
13 3 1
14 6 4 1
Рисунок 2.9
Иллюстрация к алгоритму слияния
В этом
равнобедренном треугольнике каждое число (кроме единиц на боковых сторонах)
является суммой двух чисел, стоящих над ним. Число сочетаний С (m, n) находится в (m +
1) – м ряду на (n + 1) – м месте.
Генерация
подмножеств
Элементы
множества {1,…, m} упорядочены. Поэтому каждое n‑элементное
подмножество также можно рассматривать как упорядоченную последовательность. На
множестве таких последовательностей естественным образом определяется
лексикографический порядок. Следующий простой алгоритм генерирует все n‑элементные
подмножества m‑элементного множества в лексикографическом порядке.
Алгоритм 1.3.
Генерация n‑элементных подмножеств m‑элементного
множества
Вход: n – мощность подмножества, m – мощность множества, m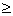 n > 0. n > 0.
Выход:
последовательность всех n‑элементных подмножеств m‑элементного
множества в лексикографическом порядке.
for
i from 1 to m do
A[i]: = i {инициализация
исходного множества} end for
if
m = n then
yield
A [1..n] {единственное подмножество} exit end if
p: = n {p – номер
первого изменяемого элемента} while p 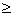 1 do 1 do
yield A [1..n]
{очередное подмножество в первых n элементах массива А} if А[i] = m then
р: = р – 1 {нельзя
увеличить последний элемент} else
р:=n {можно увеличить
последний элемент} end if if p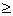 1 then 1 then
for
i from n downto p do
А[i]: = А[р]+i‑р+1 {увеличение элементов} end for end
if end while
Заметим, что
в искомой последовательности n‑элементиых подмножеств (каждое из
которых является возрастающей последовательностью n чисел из диапазона
l..m) вслед за последовательностью (ai,…, an)
следует последовательность
(b1,…,
bn) = (а1…, ap-1,
ар + 1, ар + 2,…, ар
+ n-р +1), где р – максимальный индекс, для которого bn
= ар + n - р + 1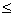 m. Другими
словами, следующая последовательность получается из предыдущей заменой некоторого
количества элементов в хвосте последовательности на идущие подряд целые числа,
но так, чтобы последний элемент не превосходил n, а первый изменяемый
элемент был на 1 больше, чем соответствующий элемент в предыдущей
последовательности. Таким образом, индекс р, начиная с которого следует
изменить «хвост последовательности», определяется по значению элемента А[n].
Если А[n] < m, то следует изменять только А[n],
и при этом р: = n. Если же уже А(n) = m, то
нужно уменьшать индекс р: =р – 1, увеличивая длину изменяемого
хвоста. m. Другими
словами, следующая последовательность получается из предыдущей заменой некоторого
количества элементов в хвосте последовательности на идущие подряд целые числа,
но так, чтобы последний элемент не превосходил n, а первый изменяемый
элемент был на 1 больше, чем соответствующий элемент в предыдущей
последовательности. Таким образом, индекс р, начиная с которого следует
изменить «хвост последовательности», определяется по значению элемента А[n].
Если А[n] < m, то следует изменять только А[n],
и при этом р: = n. Если же уже А(n) = m, то
нужно уменьшать индекс р: =р – 1, увеличивая длину изменяемого
хвоста.
2.1.4
Представление множеств в приложениях на Delphi
Тип множество
задает неупорядоченную совокупность неповторяющихся объектов. Переменная типа
множество – это совокупность объектов из исходного заданного множества – может
иметь значение «пусто» (пустое множество). Число элементов исходного множества
ограничено – оно не может быть более 256. Для задания элементов множества может
использоваться любой порядковый тип, однако порядковые номера элементов
множества, т. е. значения функции ord, должны находиться в пределах
от 0 до 255. Для задания типа множества используется следующее объявление [22]:
Type
<Имя> = set of <тип элементов>;
При задании
типа элементов необходимо соблюдать ограничения, указанные выше.
Type
A = set of Char; A1 = set of ‘A’.’Z’;
Oper
= set of (Plus, Minus, Mult, Divide);
Number
= set of Byte; D = set of 1..20;
Для
переменных типа множество можно задавать типизированные константы. При этом
значения задаются в виде конструктора множества.
Const K:D =
[5,9,11,17]; R:D = [1.. 9,13,20];
Для задания
значений переменным типа множество также можно использовать конструкторы. Пусть
объявлено
Var AA:A;,
тогда возможна запись (тип A объявлен выше)
AA:=[Char(13),
Char(7), ‘0’, ‘Q’];
Если
требуется присвоить этой переменной значение «пусто», то используется такой
конструктор: AA:= [];
Операции
над множествами
Как и для
других типов, имеется ряд встроенных операций для типа множество. Пусть заданы
следующие типы и переменные: Type Mn = set of 1..50; Var A, B, C: Mn;
Пусть
переменным присвоены значения:
A:= [3,5,9,10];
B:= [1,7,9,10];
Объединение
множеств
C:=A+B; {1,3,5,7,9,10}
Разность (A-B
<> B-A)
C:=A-B;
{3,5}
C:=B-A; {1,7}
Пересечение
(умножение)
C:=A*B; {9,10}
Проверка
эквивалентности, например в операторе IF
(A = B) {False}
Проверка
неэквивалентности
(A <>
B) {True}
Проверка,
является ли одно множество подмножеством другого
(A>=B)
{False}
(A<=B)
{False}
Проверка,
входит ли заданный элемент в заданное множество
(3 in A) {True}
(3 in B) {False}
Стандартные
подпрограммы для выполнения некоторых действий над множествами
Exclude (A, 3);
удалить из множества A элемент 3}
Include (A, 3);
{вставить элемент 3 в множество A}.
2.1.5
Характеристический вектор множества
Характеристическим
вектором Vx множества X, заданного на универсальном множестве I, является вектор,
содержащий 0 и 1. Количество элементов в векторе Vx равно количеству
элементов в универсальном множестве, причём, 1 записывается в случае, если
элемент присутствует и в универсальном множестве I, и в множестве X,
в противном случае записывается 0. Некоторые задачи с множествами, особенно на
компьютере, удобно решать, используя характеристические векторы [1].
Действия над
векторами похожи на логические операции.
Над
характеристическими векторами выполняются поразрядно логические операции:
при
пересечении – логическое умножение;
при
объединении – логическое сложение;
при
нахождении дополнения – значения в исходном векторе изменяются на противоположные.
При объединении
множеств  элементы характеристического
вектора считают по правилу: элементы характеристического
вектора считают по правилу:
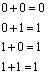
2) При
пересечении множеств 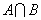 элементы
характеристического вектора считают по правилу: элементы
характеристического вектора считают по правилу:
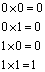
3) При
нахождении дополнения 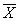 нули меняют на
единицы, единицы – на нули; нули меняют на
единицы, единицы – на нули;
4) При
нахождении симметричной разности 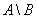 ,
используют формулу: ,
используют формулу:
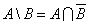
Пример 2.5 Пусть I = {1, 2,
3, 4, 5, 6}, А={1, 2, 4, 5} и В={3, 5} Характеристическим вектором множества А
является вектор а = (1, 1, 0, 1, 1, 0). Характеристический вектор множества В
равен b = (0, 0, 1, 0, 1, 0).
Вычислим
характеристический вектор множества A U  .
Он равен .
Он равен
а или (не b) = (1,
1, 0, 1, 1, 0) или (1, 1, 0 1, 0, 1) = (1,1,0,1,1,1).
Следовательно,
A U  = {1, 2, 4, 5, 6}. = {1, 2, 4, 5, 6}.
Характеристический
вектор множества А Δ В равен
(а и
(не b)) или (b и (не а)) = ((1, 1, 0, 1, 1, 0) и (1, 1, 0,
1, 0, 1)) или
или ((0, 0,
1, 0, 1, 0) и (0, 0, 1, 0, 0, 1)) = (1, 1, 0, 1, 0, 0) или (0, 0, 1, 0, 0, 0) =
(1, 1, 1, 1, 0, 0).
Таким
образом, А Δ В = {1, 2, 3, 4}.
2.2
Практическая часть
2.2.1 Задание
к работе
1. Изучить
теоретический материал, включая и дополнительные сведения, представленные в теоретической
части.
2. Задать
самостоятельно универсальное множество X, множества A, B, C (или
некоторые из них, т. к. в некоторых вариантах используются только два
множества).
3. Cформировать
характеристические векторы для исходных множеств и получить результирующее
множество (по варианту), используя характеристические вектора.
4. Вычислить
элементы результирующего множества (по варианту), используя операции над
множествами.
5. Вывести
результаты, полученные в пункте 3 и пункте 4.
6. Сравнить
эти результаты и сделать выводы.
7. Пункты 3 и
4 выполнить двумя способами: аналитически и реализовать в виде приложения на
Delphi.
Примечание:
1. Если в
выражении используется операция разности или симметрической разности, то при
выполнении действий с характеристическими векторами (пункт 3) заменить их
другими операциями на множествах (использовать формулы из лекций и [23]).
2. При
выполнении пункта 4 операцию симметрической разности заменить другими
операциями, которые используются в Object Pascal.
3. В качестве
дополнительного задания предлагается реализовать любой описанный в
теоретической части алгоритм в виде приложения на Delphi.
2.2.2
Примеры выполнения
Пример 1.
1) Задание по
варианту
I:={1,2,3,4,5,6,7}
Значения
векторов A, B, C берутся произвольно, но с учетом, что количество
элементов не должно быть больше 7.
Найти:
характеристический вектор множеств A, B и C, характеристический
вектор множества D – Vd, перейти от Vd к D.
2) Создать
приложение в среде Delphi, которое решит данную задачу.
3) Решить
задачу аналитически.
4) К защите
данной работы необходимо знать теоретический материал по данной теме из лекций
и методички, а также ответить на «Вопросы для самопроверки».
D=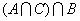
Аналитическое
решение:
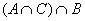
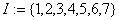
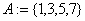
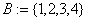
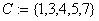
Характеристические
векторы
A:={1,0,1,0,1,0,1}
B:={1,1,1,1,0,0,0}
C:={1,0,1,1,1,0,1}
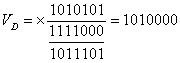
Переходим от 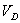 к D к D
D:= 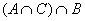 ={1,3} ={1,3}
Форма
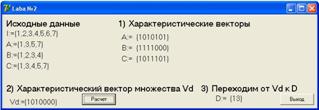
Рисунок 2.10
Формы с результатами
Код программы
implementation
procedure
TForm1. Button1Click (Sender: TObject);
var
n,
A, B, C: set of char;
s,
s1, s2, s3, s11, s22, s33, s4, s44, s5, s55:string;
i:integer;
begin
s:='1234567';
n:=['1'..'7'];
A:=['1',
'3', '5', '7'];
B:=['1',
'2', '3', '4'];
C:=['1',
'3', '4', '5', '7'];
begin
for
i:=1 to 7 do
begin
if
(s[i] in A) then
s1:=s1+'1'
else
s1:=s1+'0';
end;
s11:='
{'+s1+'}';
label7.
Caption:=s11;
end;
begin
for
i:=1 to 7 do
begin
if
(s[i] in B) then
s2:=s2+'1'
else
s2:=s2+'0';
end;
s22:='
{'+s2+'}';
label12.
Caption:=s22;
end;
begin
for
i:=1 to 7 do
begin
if
(s[i] in C) then
s3:=s3+'1'
else
s3:=s3+'0';
end;
s33:='
{'+s3+'}';
label13.
Caption:=s33;
{Задаем
характеристические векторы}
end;
begin
for
i:=1 to 7 do
if((s1
[i])=(s2 [i])) and ((s3 [i])=(s2 [i])) and ((s3 [i])='1') then
s4:=s4+'1'
else
s4:=s4+'0';
s44:='
{'+s4+'}';
label17.
Caption:=s44;
{Находим
Характеристический вектор
множества Vd}
end;
begin
for
i:=1 to 7 do
if
s4 [i]='1' then
s5:=s5+inttostr(i);
s55:='
{'+s5+'}';
label21.
Caption:=s55;
{Переходим от
Vd к D}
end;
end;
procedure
TForm1. Button2Click
(Sender:
TObject);
begin
close;
end;
end.
2.2.3 Варианты заданий
1) 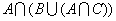
2) 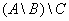
3) 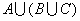
4) 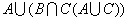
5) 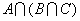
6) 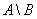
7) 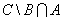
8) 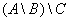
9) 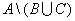
10) 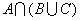
11) 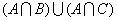
12) 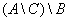
13) 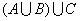
14) 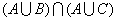
15) 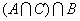
16) 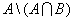
17) 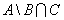
18) 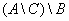
19) 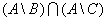
20) 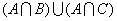
21) 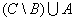
22) 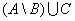
23) 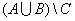
24) 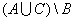
25) 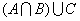
26) 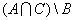
27) 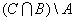
28) 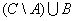
29) 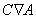
30) 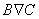
31) 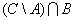
32) 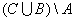
33) 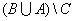
34) 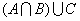
35) 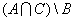
36) 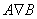
37) 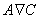
38) 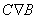
39) 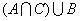
40) 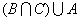
41) 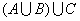
42) 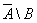
43) 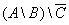
44) 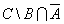
45) 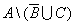
46) 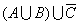
47) 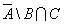
47) 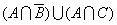
49) 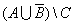
50) 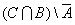
2.3 Вопросы
для самопроверки
1) Какие
основные символы, используемые в теории множеств, вы знаете?
2) Перечислите
основные операции над множествами и функции, применимые к множествам, которые
используются в Delphi.
3) Что такое
множество? Как его обозначить? Как можно задать множество?
4) Какое
множество называют счетным? Какое – пустым?
5) Что такое
подмножество?
6)
Сформулируйте основные свойства счетных множеств.
7) Определите
понятие вектора, булеана.
8)
Сформулируйте основные аксиомы теории множеств.
9) Какие
соотношения (действия) между множествами вы знаете, как они обозначаются?
10) Какое множество
можно назвать универсальным?
11) Какие
операции (из аналогичных арифметическим) нельзя производить с множествами?
12) Что такое
диаграмма Эйлера-Венна? Проиллюстрируйте с помощью диаграмм Эйлера-Венна
объединение и пересечение трех множеств.
13) Дайте
определение декартова произведения множеств; какие теоремы о декартовом
произведении Вы знаете?
14) Поясните
термин «мощность множества».
15)
Сформулируйте (и докажите) основные тождества алгебры множеств.
16) Дайте
определение проекции вектора.
17) Что
понимается под соответствием между множествами?
18) Дайте
определение функции с точки зрения теории множеств. Приведите пример.
19) Дайте
определение бинарного отношения, перечислите свойства.
20) Какие
отношения называют рефлексивными, транзитивными?
21) Что такое
«класс эквивалентности»?
22) Для чего
нужна диаграмма Хассе?
23) Дайте
определение нечёткого множества.
24) Какие
операции допустимы над нечёткими множествами?
25) Дайте
определение расстояний Хемминга и его основных свойств.
26)
Перечислите основные алгоритмы генерации множеств.
Практическая работа № 3. Элементы
теории графов
Цель работы:
изучение математических структур для представления графов, изучение наиболее
известных алгоритмов на графах и построение приложений на Delphi для описания
графов в виде математических структур, реализации некоторых алгоритмов на
графах.
3.1 Теоретическая
часть
В данном
параграфе многие определения и рисунки взяты из [17] и [19], являются
дополнительными сведениями для материала, рассматриваемого в [24].
Пусть V
конечное множество (множество вершин), А – множество упорядоченных пар
вершин, элементы которого называются ребрами.
Тогда графом G
(V, A) называется совокупность множества вершин и множества ребер.
Вершины а и с соединяются ребром, если (а, с)ÌА.
Пусть дано
множество вершин V и декартово произведение VхV
множество всевозможных пар вершин. Тогда графом G является подмножество
декартового произведения.
Ребро графа G
ориентировано, если порядок пары (a, b) существенен.
Ребро графа G
не ориентировано, если порядок пары (a, b) несущественен.
Рисунок 3.1
Ориентированный граф
Граф
называется ориентированным, если все его ребра ориентированы.
Граф G
называется неориентированным, если все его ребра неориентированы.
Смешанным
графом называется граф, у которого есть как ориентированные, так и
неориентированные ребра.
Каждому ребру
E=ía, bý можно поставить в соответствие некоторое
число.
Граф G,
каждому ребру которого присвоено число (например, расстояние) называется сетью.
Пусть даны a,
b – вершины графа. Ребро E их соединяет. Тогда говорят, что ребро E
инцидентно вершинам a и b. И обратно – вершины a и b
инцидентны ребру E.
При
изображении графа имеется большая свобода в размещении вершин и дуг.
Рисунок 3.2
Три изображения одного и того же графа
Пусть G
и G1 графы, V и V1 – множества их вершин соответственно.
Графы G и G1 изоморфны, если существует взаимнооднозначное соответствие
между множествами их вершин V и V1 и вершины в графе G
соединены ребром в том и только том случае, если соответствующие вершины соединены
ребром в графе G1.
Если графы G
и G1 ориентированы, то направления ребер должны соответствовать друг
другу. Изоморфные графы имеют одинаковые свойства.
Вершина, не
инцидентная никакому ребру, называется изолированной. Граф, состоящий из
изолированных вершин, называется нуль граф. Обозначается через О.
Граф, любые две
вершины которого соединены ребром, называется полным графом U=U(V).
Петлей
называется ребро L=(a, a). Петля считается неориентированным
ребром.

Рисунок 3.3
Петля
Пара вершин
может соединяться несколькими различными ребрами.
Пара ребер Ei
Ej, ориентированная в противоположном направлении, эквивалентна одному
неориентированному ребру.
Таким
образом, мы можем любой неориентированный граф превратить в ориентированный.
При этом количество ребер увеличивается в 2 раза.
Граф
называется плоским, если может быть изображен на плоскости так, чтобы его ребра
пересекались только в вершинах.
Граф назовем
однородным степени k, если локальные степени во всех его вершинах равны k,
т. е. 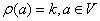
|
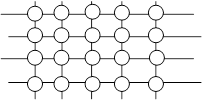
Рисунок 3.4 – Бесконечный
однородный граф
|
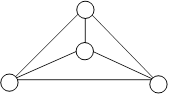
Рисунок 3.5 – Конечный
однородный граф
|
Граф H
называется частью графа G, если подмножество вершин его V(H)
содержится во множестве вершин V(G) и все ребра части графа H
являются ребрами G и обозначается HÌG.
Для любой
части H графа G существует дополнение  , которое состоит из всех ребер
графа G, не принадлежащих H. , которое состоит из всех ребер
графа G, не принадлежащих H.
Рисунок 3.6
Граф G Рисунок
3.7 – Часть графа G
Пусть H1
и H2 – две части графа G. Сумма этих частей H1UH2
есть часть, состоящая из ребер, принадлежащих H1 или H2. Пересечение
D=H1 H2 – есть часть, состоящая
из ребер, принадлежащих H1 и H2 одновременно. Две части не
пересекаются по вершинам, если они не имеют общих вершин, и, следовательно,
ребер. Части H1 и H2 не пересекаются по ребрам, если они не имеют
общих ребер H1 H2 – есть часть, состоящая
из ребер, принадлежащих H1 и H2 одновременно. Две части не
пересекаются по вершинам, если они не имеют общих вершин, и, следовательно,
ребер. Части H1 и H2 не пересекаются по ребрам, если они не имеют
общих ребер H1 H2=0. Если H1 и H2
непересекающиеся части графа G, то их сумма называется прямой и H1UH2=G. H2=0. Если H1 и H2
непересекающиеся части графа G, то их сумма называется прямой и H1UH2=G.
Бинарные
отношения и графы
Бинарные
отношения можно изобразить графом: вершины графа – элементы множества V,
ребра графа соединяют вершины, которые находятся в отношении друг к другу.
Любой граф
определяет бинарное отношение R на множестве вершин V, если для
каждого ребра (a, b) выполняется aRb. Нельзя говорить о
взаимнооднозначном соответствии между графами и бинарными отношениями. Пустому
бинарному отношению соответствует нуль-граф О. Универсальному бинарному
отношению отвечает полный граф U. Бинарному отношению aRb,
где R – отрицание R (дополнительное бинарное отношение) отвечает
граф G(R)=U(V) – G(R). Обратному
бинарному отношению bR*a отвечает обратный граф G (R*),
т. е. граф с измененной ориентацией ребер. Операции, которые вводятся для
бинарных отношений, могут быть перенесены на графы.
Симметричное
бинарное отношение: если aRb, то bRa.
Рефлексивность:
бинарное отношение aRa соответствует графу с петлей в каждой вершине.
Транзитивность:
если aRb и bRc, то aRc. Для графа это означает, что если
существует ребро (a, b) и ребро (b, c), то существует ребро (a,
c). Такой граф называется связным.
Свойство
связности можно рассмотреть как бинарное отношение, которое:
а)
рефлексивно: вершина а связана сама с собой;
б)
симметрично: если вершина а связана с вершиной b, то и вершина b
связана с вершиной a;
в)
транзитивно: если вершина a связана с вершиной b, и b
связана с вершиной с, то вершина a связана с вершиной c.
Отношение
связности есть отношение эквивалентности, т. е. оно разбивает множество
вершин на попарно непересекающиеся классы.
Так как
каждое множество Vi – множество связанных вершин, а вершины из разных
множеств Vi не связаны, то имеем разложение графа G на части,
которые не пересекаются и каждая часть – связная.
Подграфы G(Vi)
называются связными компонентами графа G.
Каждый
неориентированный граф распадается единственным образом в прямую сумму всех
своих связных компонент.
Покрывающие
деревья
Граф, не
содержащий циклов, называется ациклическим. Деревом называется связный граф, не
содержащий циклов. Пусть VG – число элементов в множестве вершин, VL
число элементов множества ребер дерева.
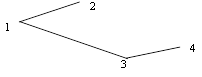
Рисунок 3.8
Дерево
VG =VL‑1
Добавим ребро
появляется цикл, удалим ребро – теряется связность. Лесом называется
несвязный граф, компонентами которого являются деревья.
Пусть VLl – число элементов в
множестве ребер леса, VGl – число элементов в
множестве вершин леса, k – число деревьев в лесе.
VLl = VGl - k
Если дерево Т
имеет корень, то дерево называется деревом с корнем. Выделим в дереве Т
некоторую цепь.
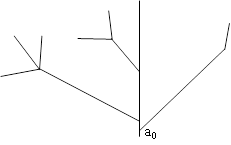
Рисунок 3.9
Дерево
Задача.
Как узнать,
существуют ли циклы в графе?
Для дерева
связь между числом ребер и числом вершин такова
Vl=VG‑1. Рассмотрим
s=
Vl-VG+1, s называется цикломатическим числом. Если граф G
дерево, то s=0, если s не равно нулю, то в графе G есть циклы.
Алгоритм
построения произвольного покрывающего дерева [20]
Ограничения:
в графе не должно быть петель. Букетом называется произвольное дерево в графе.
Шаг 1.
Выбираем произвольное ребро и помечаем его х (красим в голубой цвет).
Шаг 2.
Выбираем другое произвольное непомеченное ребро. Если оба конца ребра лежат в
одном букете, красим ребро в красный цвет. В противном случае – в голубой.
Шаг 3. Если
все вершины графа вошли в один букет, то процедура заканчивается, т. к.
помеченные голубым ребра образуют покрывающее дерево. В противном случае – перейти
к шагу 2.
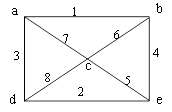
Рисунок 3.10
Граф
1 шаг: (a,
d) – помечаем голубым
2 шаг: (b,
e) – помечаем голубым
3 шаг: (d,
e) – помечаем голубым
4 шаг: (a,
b) – помечаем красным
5 шаг: (a,
c) – получаем голубым

Рисунок 3.11
Дерево
Алгоритм
построения минимального и максимального покрывающего дерева [21]
Пусть каждому
ребру графа G присвоена длина (вес) l (x, y) (таблица 3.1).
Весом дерева называется сумма весов ребер, входящих в дерево. Минимальным
деревом называется дерево с минимальным весом.
Алгоритм
формируется так же, как и алгоритм построения произвольного покрывающего
дерева. Но ребра просматриваются в порядке возрастания их веса.
Таблица 3.1
Веса ребер графа
|
|
A
|
b
|
c
|
d
|
e
|
|
a
|
0 |
5 |
50 |
85 |
90 |
|
b
|
5 |
0 |
70 |
60 |
50 |
|
c
|
50 |
70 |
0 |
8 |
20 |
|
d
|
85 |
60 |
8 |
0 |
10 |
|
e
|
90 |
50 |
20 |
10 |
0 |
Порядок
просмотра
(a, b)
5 (b, e) – 50 упорядочим ребра по возрастанию
(c,
d) – 8 (b, d) – 60
(d,
e) – 10 (b, c) – 70
(c,
e) – 20 (a, d) – 85
(a, c)
50 (a, b) – 90
1 шаг: (a,
b) – помечаем голубым
2 шаг: (c,
d) – помечаем голубым
3 шаг: (d,
e) – помечаем голубым
4 шаг: (c,
e) – помечаем красным
5 шаг: (a,
c) – помечаем голубым
Дерево
построено!
Рисунок 3.12
Дерево
Алгоритм
построения максимального ориентированного дерева(алгоритм Эдмонса) [15]:
Шаг 1.
Последовательно в произвольном порядке просматриваем вершины графа G0.
Просмотр вершины заключается в том, чтобы из дуг, заходящих в эту вершину,
выбрать дугу с максимальным весом. При просмотре следующих вершин к уже
отобранным ранее дугам добавляются новые дуги. Если добавление ребра не
нарушает свойства букета, то добавление ребер продолжается. Если новое ребро
образует контур, перейти к шагу 2.
Шаг 2. В
случае формирования контура строится уменьшенный граф путем стягивания дуг и
вершин выявленного контура исходного графа Go в одну вершину V.
В новом графе
веса ребер (xi, vi) полагаются равными
l
(x, vi)=l (x, y)+l (r, s)
l (t, y),
где К
контур, а у – вершина, принадлежащая контуру.
l (x, vi) – ребро,
переходящее в ребро l (x, vi)
l (r, s) – ребро,
имеющее в контуре минимальный вес
l (t, y) – ребро,
заходящее в вершину у и имеющее максимальный вес
Шаг 3.
Выполняется тогда, когда вершины нового графа попадают в букет, а дуги образуют
дерево.
Возможны 2
случая:
вершина Vo
является корнем дерева, тогда необходимо рассмотреть ребра букета в новом графе
совместно с ребрами контура. Удалить из рассматриваемого множества ребер ребро
с минимальным весом;
если Vo
не является корнем дерева – в букете нового графа имеется лишь одно ребро,
заходящее в некоторую вершину Z и одно ребро контура, заходящее в ту же
вершину. Удаляем ребро контура, заходящее в вершину Z.
Пример.
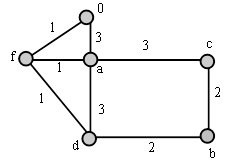
Рисунок 3.13
Граф
Просмотр
вершин: Букет получаемых ребер
a (da)
b (da)
(cb)
c (da)
(cb) (ac)
d (da)
(cb) (ac) (bd)
Ребра (ac) (cb)
(bd) (da) образуют контур. Минимальный вес ребра в
контуре 2.
Стягиваем
контур в одну вершину и рассматриваем граф:
Рисунок 3.14
Граф
l(fe)=1
l (e, Vo)=l(ea)+2–3=3+2–3=2
l
(f, Vo)=l (f, a)+2–3=-1
l
(f, Vo) 1=l(fd)+2‑l (b, d)=1+2–2=1
Просмотр
вершин Букет ребер
e (fe)
f (fe)
Vo (fe)
(eVo)
Получили множество
ребер исходного графа Go такое:
(fe) (ea)
образуют букет
(ac) (cb)
(bd) (da) – образуют контур
Vo не является контуром
дерева, удаляем (da), поскольку (da) – ребро из контура. Получили
дерево:
(fe) (ea)
(ac) (cb) (bd) с весом l=1+2+3+2+2=10
Задача о
кратчайших путях
Пусть G
ориентированный граф, Е – ребра графа. Каждому ребру соответствует
число.
Рисунок 3.15
Эйлеров цикл
Задача
Эйлера о Кенигсбергских мостах [19]: необходимо выйти из любой точки города и
вернуться в нее, при этом пройдя по каждому мосту только один раз. Эйлер свел
эту задачу к графу: существует ли в конечном графе такой цикл, в котором каждое
ребро участвует только один раз? Цикл, в котором каждое ребро графа G
участвует всего один раз, называется эйлеровым циклом. Граф, содержащий эйлеров
цикл, называется эйлеровым.
Дальнейшее
развитие задачи об Эйлеровом цикле
Припишем
ребрам графа длину μ (ai, aj). Требуется найти путь в графе,
который проходит через все ребра и имеет наименьшую длину.
Пример.
Рисунок 3.16
Граф
S – стартовая вершина. Из
вершины S надо пройти по всем ребрам так, чтобы маршрут имел минимальную
длину. Очевидно, что длина маршрута будет минимальной, если каждое ребро будет
пройдено всего один раз – т. е. маршрут будет эйлеровым циклом.
Все локальные
степени – четные, значит граф эйлеров.
Варианты
прохождения по циклу:
1)
(sa) (ab) (bc) (cd) (db) (ds)
2)
(sa)
(ab) (bd) (dc) (cb) (bs)
3)
(sb)
(bc) (cd) (db) (ba) (as)
4)
(sb)
(bd) (dc) (cb) (ba) (as)
Длина
эйлерова цикла – 22. Любой из вариантов 1–4 содержит каждое ребро графа, следовательно,
длина одинакова для всех циклов 1–4. Длина эйлерова цикла не зависит от того,
какая вершина будет выбрана за исходную.
Задача поиска
эйлерова цикла – это задача о: – поиске наилучшего способа прохождения бригады
по дорогам; – прохождении с/х техники по полям.
Впервые эта
задача рассматривалась в связи с нахождением оптимального маршрута следования
почтальона, который доставляет письма своим адресатам и должен при этом пройти
минимальный путь.
Алгоритм
нахождения эйлерова цикла для неориентированного графа [19]:
Дан эйлеров
граф – т. е. граф с четными локальными степенями.
Найдем первое
ребро х, инцидентное вершине S. Затем найдем ребро, смежное с
ребром х, которое не образует цикл и еще не было использовано. Продолжим
этот процесс до тех пор, пока не вернемся в вершину S. Если в
построенный цикл С1 вошли все ребра графа – задача решена.
Если в
построенный цикл С1 вошли не все ребра – строим цикл С2,
состоящий из неиспользованных ребер и начинающийся с произвольного
неиспользованного ребра.
Таким
образом, строим циклы С2, С3,….Образование циклов продолжается до
тех пор, пока не будут использованы все ребра.
Все циклы Сi
необходимо объединить в один цикл. Условие объединения циклов С1 и С2
наличие у них общей вершины х. Начинаем движение с любой вершины и
двигаемся по циклу С1 до тех пор, пока не дойдем до х. Затем
проходим ребро. С» и возвращаемся в х. Продолжаем обход по оставшимся
ребрам до возвращения к исходной точке. Эта процедура легко обобщается на
случай любого числа объединяемых циклов.
Циклы
Эйлера для ориентированного графа
Алгоритм
построения эйлерова цикла в эйлеровом ориентированном графе является аналогом
алгоритма построения эйлерова цикла для неориентированного графа.
Строятся
циклы Сi с учетом ориентации ребер, и затем все циклы объединяются в
один.
Гамильтонов
цикл (задача о коммивояжере)
Простой цикл,
проходящий через каждую вершину графа только один раз, называется гамильтоновым
циклом.
Если ребрам
приписана длина, то различные варианты циклов отличаются друг от друга. Поэтому
ставится задача нахождения гамильтонова цикла, имеющего минимальную длину.
Гамильтонов
цикл наименьшей длины называется оптимальным гамильтоновым циклом (ОГЦ)
Поиск
оптимального гамильтонова цикла – задача о коммивояжере, который должен
посетить множество пунктов и вернуться домой, пройдя наименьший путь.
Решением
задачи о коммивояжере не всегда является ОГЦ.
Гамильтоновы
графы применяются для моделирования многих практических задач. Графическая
модель задачи коммивояжера состоит из гамильтонова графа, вершины которого
изображают города, а ребра – связывающие их дороги. Кроме того, каждое ребро
оснащено весом, обозначающим транспортные затраты, необходимые для путешествия
по соответствующей дороге, например, расстояние между городами или время
движения по дороге. Для решения задачи нам необходимо найти гамильтонов цикл
минимального общего веса.
Рисунок 3.17
Ребра, входящие в гамильтонов цикл С
К сожалению,
алгоритм решения данной задачи, дающий оптимальное решение, пока не известен. Для
сложных сетей число гамильтоновых циклов, которые необходимо просмотреть для
выделения минимального, непомерно огромно. Однако существуют алгоритмы поиска
субоптимального решения [1]. Субоптимальное решение необязательно даст цикл
минимального общего веса, но найденный цикл будет, как правило, значительно
меньшего веса, чем большинство произвольных гамильтоновых циклов! Один из таких
алгоритмов – алгоритм ближайшего соседа.
Этот алгоритм
выдает субоптимальное решение задачи коммивояжера, генерируя гамильтоновы циклы
в нагруженном графе с множеством вершин V. Цикл, полученный в результате
работы алгоритма, будет совпадать с конечным значением переменной маршрут,
а его общая длина – конечное значение переменной w.
begin
Выбрать v
V;
маршрут:=v;
w:=0;
v':=v;
Отметить v';
while
остаются неотмеченные вершины do begin
Выбрать
неотмеченную вершину и,
ближайшую к
v';
маршрут:=
маршрут u;
w:= w + вес
ребра v'u;
v':=u;
Отметить v';
end
маршрут:=
маршрут v;
w:= w + вес
ребра v'v;
end
Пример.
Примените алгоритм ближайшего соседа к графу, изображенному на рисунке 3.18. За
исходную вершину возьмите вершину D.
Рисунок 3.18
Граф
Таблица 3.2
Алгоритм ближайшего соседа
|
|
и |
маршрут |
w
|
v'
|
| Исходные значения |
–
|
D
|
0 |
D
|
|
|
С
|
dc
|
3 |
С
|
|
|
А
|
DCA
|
9 |
A
|
|
|
В
|
DCAB
|
14 |
В
|
| Последний проход |
В
|
DCABD
|
24 |
В
|
В результате
работы алгоритма был найден гамильтонов цикл DCABD общего веса 24. Делая
полный перебор всех циклов в этом маленьком графе, можно обнаружить еще два
других гамильтоновых цикла: ABCDA общего веса 23 и ACBDA общего
веса 31. В полном графе с двадцатью вершинами существует приблизительно 6,1 *
10^16 гамильтоновых циклов, перечисление которых требует чрезвычайно много
машинной памяти и времени.
Реализация примера
данного алгоритма в Delphi:
procedure
TForm1. Button1Click (Sender: TObject);
const
mat:array [1.. 4,1..4] of byte=((0,5,6,8), (5,0,7,10), (6,7,0,3), (8,10,3,0));
Versh:array
[1..4] of char=('a', 'b', 'c', 'd');
buk:char='d';
Type
t=set of 'a'..'d';
Var
dlina, i, j, min, n, k, s:byte;
put:string;
z:t;
begin
dlina:=0;
Memo1.
Lines. Clear;
for
i:=1 to 4 do if versh[i]=buk then begin n:=i; s:=i;
include
(z, buk);
put:=put+buk;
end;
for
j:=1 to 3 do begin
if
mat [n, 1]<>0 then begin min:=mat [n, 1]; k:=1; end
else
begin min:=mat [n, 2]; k:=2; end;
for
i:=1 to 4 do
if
(mat [n, i]<min) and (mat [n, i]<>0) and (not (versh[i] in z)) then begin
min:=mat
[n, i];
k:=i;
end;
dlina:=dlina+min;
put:=put+versh[k];
include
(z, versh[k]);
n:=k;
end;
put:=put+'d';
dlina:=dlina+mat
[k, s];
Memo1.
Lines. Add ('маршрут:'+' '+put);
Memo1.
Lines. Add ('длина маршрута='+IntToStr(dlina));
end;
end.
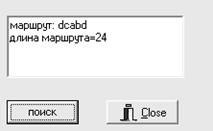
Рисунок 3.19
Форма с результатом
3.2 Практическая часть
3.2.1 Задание
к работе
1 изучить
теоретический материал по методическому пособию [24], лекциям и записям на
практических занятиях;
2 получить
задание по индивидуальному варианту в виде графа или матрицы смежности, в
первом случае построить матрицу смежности, во втором – нарисовать граф;
3 составить
подробное описание графа: ориентированный или неориентированный, количество
вершин, дуг (рёбер), содержит ли циклы и какие, найти степени вершин,
количество компонент связности и т. д.;
4 создать
приложение на Delphi для расчёта матрицы инцидентности по известной матрице
смежности (если граф достаточно сложный, то можно взять подграф этого графа);
5 в качестве
дополнительного творческого задания создать приложение на Delphi для реализации
алгоритма ближайшего соседа, алгоритма Прима, алгоритма Уоршелла, алгоритма
Дейкстры, алгоритма определения количества компонент связности графа и других
известных алгоритмов на графах. [13], [17], [18], [19], [20], [21].
3.2.2 Примеры выполнения
Пример 1: По
заданной матрице смежности построить матрицу инцидентности.
implementation
procedure
TForm1. UpDown1Click (Sender: TObject; Button: TUDBtnType);
begin
with
UpDown1 do begin
with
StringGrid1 do begin
RowCount:=Position;
ColCount:=Position;
end;
StringGrid2.
RowCount:=Position;
end;
end;
procedure
TForm1. BitBtn1Click (Sender: TObject);
var
i, j, CD, P, n:byte;
MS:array
of array of byte;
MI:array
of array of ShortInt;
begin
P:=StrToInt
(Edit1. Text);
SetLength
(MS, P, P);
CD:=0;
for
i:=0 to P‑1 do for j:=0 to P‑1 do begin
MS
[i, j]:=StrToInt (StringGrid1. Cells [j, i]);
if
MS [i, j]=1 then inc(CD);
end;
SetLength
(MI, P, CD);
for
i:=0 to High(MS) do for j:=0 to CD‑1 do MI [i, j]:=0;
n:=0;
for
i:=0 to High(MS) do for j:=0 to High(MS) do
if
MS [i, j]=1 then begin
MI
[i, n]:=1;
MI
[j, n]:=-1;
inc(n);
end;
StringGrid2.
ColCount:=CD;
for
i:=0 to High(MS) do for j:=0 to CD‑1 do
StringGrid2.
Cells [j, i]:=IntToStr (MI[i, j]);
end;
end.
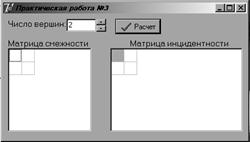
Рисунок 3.20
Форма с результатом
Пример 2: По
заданной матрице смежности построить матрицу инцидентности.
var
Form1:
TForm1;
const
maxv=4;
type
canh=record dinh1, dinh2:byte;
dodai:real;
end;
dothi=record
n:byte;
l:array
[1..maxv, 1..maxv] of real;
x,
y:set of 1..maxv;
t:array
[1..maxv] of canh;
nt:byte;
it:real;
end;
implementation
{$R
*.dfm}
procedure
TForm1. Button1Click (Sender: TObject);
var
g:dothi;
min:real;
x, y,
x0, y0:1..maxv;
i, j:byte;
begin
memo1. Clear;
g.n:=maxv;
edit1.
Text:=inttostr(maxv);
stringgrid1.cells
[0,0]:=' Номер';
for
i:=1 to maxv do begin
stringgrid1.cells
[0, i]:=inttostr(i);
stringgrid1.cells
[i, 0]:=inttostr(i); end;
g.nt:=0;
g.it:=0; g.x:=[1..g.n]; g.y:=[1];
for
i:=1 to maxv do
for
j:=1 to maxv do g.l [i, j]:=strtofloat (stringgrid1. Cells [j, i]);
while
g.nt<g.n‑1 do begin
min:=-1;
for
x:=1 to g.n do
for
y:=1 to g.n do
if
(x in g.y) and (y in (g.x-g.y)) and (g.l [x, y]>0) then
begin
if
(min=-1) or (min>g.l [x, y]) then begin
min:=g.l
[x, y];
x0:=x;
y0:=y; end;
end;
g.y:=g.y+[y0];
g.nt:=g.nt+1;
g.it:=g.it+min;
with
g.t [g.nt] do begin
dinh1:=x0;
dinh2:=y0;
dodai:=min;
end; end;
for
i:=1 to (maxv‑1) do
with
g.t[i] do
memo1.
Lines.add ('Ребро:
'+inttostr(dinh1)+inttostr(dinh2)+' '+
'Весом:
'+floattostr(dodai));
end;
end.
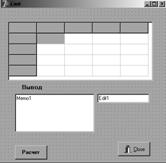
Рисунок 3.21
Форма с результатом
Пример 3:
Составить приложение на Delphi, реалилующее алгоритм Уоршелла.
var
Form1:
TForm1;
const
maxv=4;
type
canh=record dinh1, dinh2:byte;
dodai:real;
end;
dothi=record
n:byte;
l:array
[1..maxv, 1..maxv] of real;
x,
y:set of 1..maxv;
t:array
[1..maxv] of canh;
nt:byte;
it:real;
end;
implementation
{$R
*.dfm}
procedure
TForm1. Button1Click (Sender: TObject);
var
g:dothi;
min:real;
x, y,
x0, y0:1..maxv;
i, j:byte;
begin
memo1. Clear;
g.n:=maxv;
stringgrid1.cells
[0,0]:=' Номер';
for
i:=1 to maxv do begin
stringgrid1.cells
[0, i]:=inttostr(i);
stringgrid1.cells
[i, 0]:=inttostr(i); end;
g.nt:=0;
g.it:=0; g.x:=[1..g.n]; g.y:=[1];
for
i:=1 to maxv do
for
j:=1 to maxv do g.l [i, j]:=strtofloat (stringgrid1. Cells [j, i]);
while
g.nt<g.n‑1 do begin
min:=-1;
for
x:=1 to g.n do
for
y:=1 to g.n do
if
(x in g.y) and (y in (g.x-g.y)) and (g.l [x, y]>0) then
begin
if
(min=-1) or (min>g.l [x, y]) then begin
min:=g.l
[x, y];
x0:=x;
y0:=y; end;
end;
g.y:=g.y+[y0];
g.nt:=g.nt+1;
g.it:=g.it+min;
with
g.t [g.nt] do begin
dinh1:=x0;
dinh2:=y0;
dodai:=min;
end; end;
for
i:=1 to (maxv‑1) do
with
g.t[i] do
memo1.
Lines.add ('Ребро:
'+inttostr(dinh1)+inttostr(dinh2)+' '+
'Весом: '+floattostr(dodai));
end;
end.
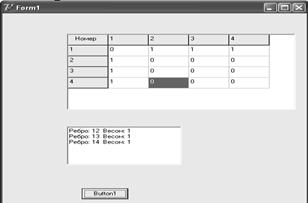
Рисунок 3.23
Форма с результатом
3.2.3 Вариантв заданий
    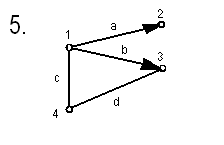 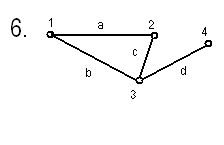 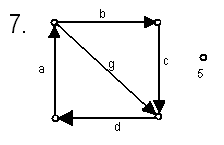 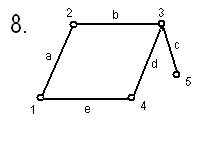 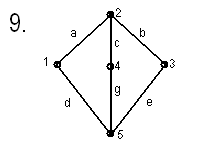 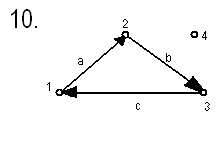 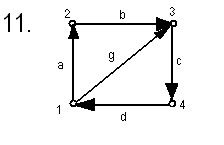 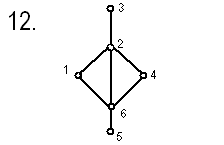 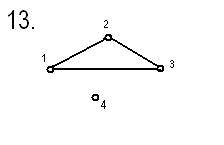 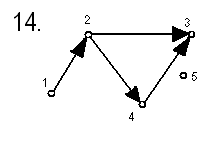 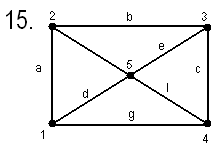 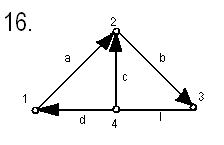 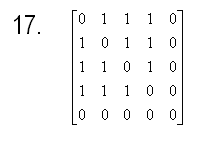  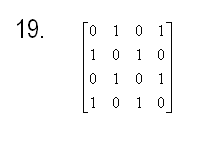 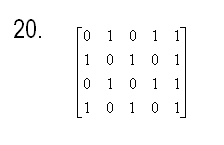 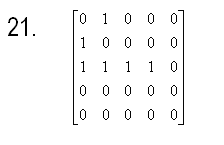 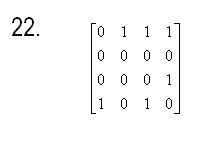 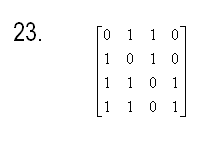  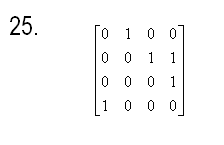 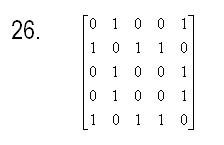 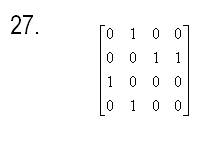  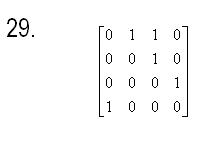  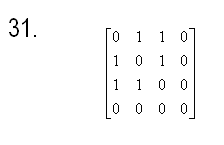 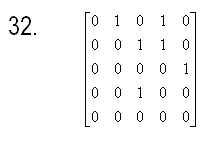 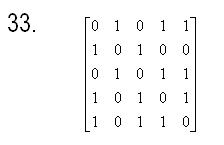  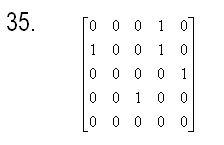  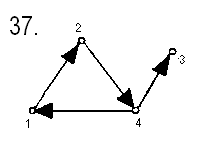 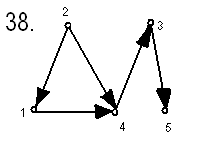  
3.3 Вопросы для самопроверки
1) Какие операции
над графами Вы знаете?
2) Как
формируется матрица смежности?
3) Как
формируется матрица весов?
4) Как
формируется матрица достижимости?
5) Как
формируется матрица инцидентности?
6) Перечислите
основные понятия, относящиеся к графам-деревьям.
7) Приведите
пример сортировки и поиска в деревьях.
8) Для
чего применяется алгоритм, подобный алгоритму Дейкстры, в коммуникационных сетях?
9)
Перечислите известные Вам алгоритмы обхода графов.
10) Что такое
транспортная сеть? Приведите пример.
11) Какой
граф называется эйлеровым? Приведите пример эйлерова графа.
12) Какой
граф называется гамильтоновым? Приведите пример гамильтонова графа.
13) Какой вид
отношений на графах представляет изоморфизм графов?
14) Приведите
пример отношения порядка и отношения эквивалентности на графе.
15) Какие алгоритмы
обхода графов Вам известны?
16) Какие виды
графов Вы знаете?
17) Что
понимается под степенью вершины?
18) Как
определяются числа внутренней и внешней устойчивости графа?
19) Как
определяются хроматическое и цикломатическое числа графа?
20) Сформулируйте
транспортную задачу и связанные с ней понятия?
21) Опишите
кратко алгоритм управления проектами.
22) Приведите
пример построения разреза графа.
23) Приведите
пример дерева с корнем.
Практическая работа № 4.
Элементы теории множеств и алгебры логики
Цель работы:
применение знаний теории множеств и алгебры логики для решения практической
задачи.
4.1
Указание к выполнению
Данная
практическая работа сочетает в себе использование элементов теории множеств и
алгебры логики. Все теоретические сведения, необходимые для выполнения данной
работы, изложены в лекциях и в уже изданных методических пособиях [23], [25]. Выполнение
данной работы рекомендуется выполнять по образцу, рассмотренному далее.
4.2
Задание к работе
1. Составить
множества из букв Ф.И.О..
2. Представить
полученные множества на кругах Эйлера.
3. Представить
буквы Ф.И.О. в двоичной системе.
4. Представить
диаграмму Венна. СНДФ.
5. Перевести
числа даты рождения в двоичную систему счисления.
Примечание: желательно реализовать
основные вычисления в приложении на Delphi.
4.3 Практическая
часть
Пример 1:
1 Множества из букв Ф.И.О.
МОРОЗОВ ОЛЕГ ЕВГЕНЬЕВИЧ
Ф = {М, О, Р, З, В};
И = {О, Л, Е, Г};
О = {Е, В, Г, Н, Ь, И, Ч};
2 Круги Эйлера и диаграммы Венна
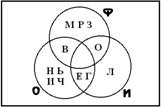
Рисунок 4.1
Круги Эйлера
Таблица 4.1
Буквы алфавита в двоичной системе
| А |
00001 |
Л |
01011 |
Ц |
10110 |
| Б |
00010 |
М |
01100 |
Ч |
10111 |
| В |
00011 |
Н |
01101 |
Ш |
11000 |
| Г |
00100 |
О |
01110 |
Щ |
11001 |
| Д |
00101 |
П |
01111 |
Ъ |
11010 |
| Е |
00110 |
Р |
10000 |
Ы |
11011 |
| Ж |
00111 |
С |
10001 |
Ь |
11100 |
| З |
01000 |
Т |
10010 |
Э |
11101 |
| И |
01001 |
У |
10011 |
Ю |
11110 |
| К |
01010 |
Ф |
10100 |
Я |
11111 |
|
|
|
Х |
10101 |
|
|
Таблица 4.2
Буквы Ф.И.О. в двоичной системе
|
|
М |
О |
Р |
З |
В |
О |
Л |
Е |
Г |
Е |
В |
Г |
Н |
Ь |
И |
Ч |
|
|
|
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
3 |
|
F1
|
1 |
1 |
0 |
1 |
0 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
0 |
8 |
|
F2
|
1 |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
1 |
1 |
0 |
1 |
1 |
1 |
0 |
1 |
10 |
|
F3
|
0 |
1 |
0 |
0 |
1 |
1 |
1 |
1 |
0 |
1 |
1 |
0 |
0 |
0 |
0 |
1 |
8 |
|
|
0 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
1 |
1 |
6 |
Таблица 4.3
СНДФ из букв Ф.И.О.
|
x1 x2 x3 x4
|
F1
|
F2
|
F3
|
| 0 0 0 0 |
1 |
1 |
0 |
| 0 0 0 1 |
1 |
1 |
1 |
| 0 0 1 0 |
0 |
0 |
0 |
| 0 0 1 1 |
1 |
0 |
0 |
| 0 1 0 0 |
0 |
0 |
1 |
| 0 1 0 1 |
1 |
1 |
1 |
| 0 1 1 0 |
1 |
0 |
1 |
| 0 1 1 1 |
0 |
1 |
1 |
| 1 0 0 0 |
0 |
1 |
0 |
| 1 0 0 1 |
0 |
1 |
1 |
| 1 0 1 0 |
0 |
0 |
1 |
| 1 0 1 1 |
0 |
1 |
0 |
| 1 1 0 0 |
1 |
1 |
0 |
| 1 1 0 1 |
1 |
1 |
0 |
| 1 1 1 0 |
1 |
0 |
0 |
| 1 1 1 1 |
0 |
1 |
1 |
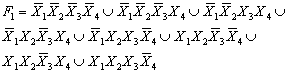
  
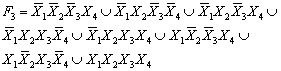
F1
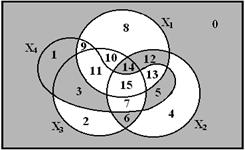
F2
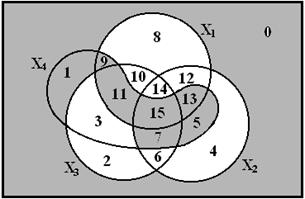
F3
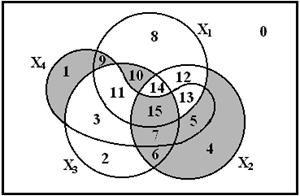
Рисунок 4.2 – Диаграммы
Венна для функций F1, F2, F3
3 Перевод
даты рождения в двоичную систему
1982.0212
|
0.0212 |
|
0.3568 |
|
1.4272 |
|
|
2 |
|
2 |
|
2 |
| 0 |
0.0424 |
0 |
0.7136 |
0 |
0.8544 |
|
|
2 |
|
2 |
|
2 |
| 0 |
0.0848 |
1 |
1.4272 |
1 |
1.7088 |
|
|
2 |
|
|
|
|
| 0 |
0.1696 |
|
|
|
|
|
|
2 |
|
|
|
|
| 0 |
0.3392 |
|
|
|
|
|
|
2 |
|
|
|
|
| 0 |
0.6784 |
|
|
|
|
|
|
2 |
|
|
|
|
| 1 |
1.3568 |
|
|
|
|
(1982.0212) 10=(11110111110.0000010101)
2
Пример 2:
автор – Якухин Дмитрий
var
k:byte;
Form1: TForm1;
type
R = set of 'A'..'Я';
implementation
{$R
*.dfm}
procedure
SNDF (y:byte; t:string);
var
i:byte;
begin
for
i:=1 to 5 do begin
Form1.
StringGrid1. Cells [y, i]:=t[i];
end;
for
i:=1 to 3 do begin
Form1.
StringGrid2. Cells [i+4, y]:=t [i+1];
end;
end;
procedure
Perebor (T:R; S:TMemo);
begin
if
('А' in T) then
begin S. Lines. Add ('А
= '+' 00001'); inc(k); SNDF (k, '00001'); Form1. StringGrid1. Cells
[k, 0]:='А'; end;
if
('Б' in T) then
begin S. Lines. Add ('Б
= '+' 00010'); inc(k); SNDF (k, '00010'); Form1. StringGrid1. Cells
[k, 0]:='Б'; end;
if
('В' in T) then
begin S. Lines. Add ('В
= '+' 00011'); inc(k); SNDF (k, '00011'); Form1. StringGrid1. Cells
[k, 0]:='В'; end;
if
('Г' in T) then
begin S. Lines. Add ('Г
= '+' 00100'); inc(k); SNDF (k, '00100'); Form1. StringGrid1. Cells
[k, 0]:='Г'; end;
if
('Д' in T) then
begin S. Lines. Add ('Д
= '+' 00101'); inc(k); SNDF (k, '00101'); Form1. StringGrid1. Cells
[k, 0]:='Д'; end;
if
('Е' in T) then
begin S. Lines. Add ('Е
= '+' 00110'); inc(k); SNDF (k, '00110'); Form1. StringGrid1. Cells
[k, 0]:='Е'; end;
if
('Ж' in T) then
begin S. Lines. Add ('Ж
= '+' 00111'); inc(k); SNDF (k, '00111'); Form1. StringGrid1. Cells
[k, 0]:='Ж'; end;
if
('З' in T) then
begin S. Lines. Add ('З
= '+' 01000'); inc(k); SNDF (k, '01000'); Form1. StringGrid1. Cells
[k, 0]:='З'; end;
if
('И' in T) then
begin S. Lines. Add ('И
= '+' 01001'); inc(k); SNDF (k, '01001'); Form1. StringGrid1. Cells
[k, 0]:='И'; end;
if
('К' in T) then
begin S. Lines. Add ('К
= '+' 01010'); inc(k); SNDF (k, '01010'); Form1. StringGrid1. Cells
[k, 0]:='К'; end;
if
('Л' in T) then
begin S. Lines. Add ('Л
= '+' 01011'); inc(k); SNDF (k, '01011'); Form1. StringGrid1. Cells
[k, 0]:='Л'; end;
if
('М' in T) then
begin S. Lines. Add ('М
= '+' 01100'); inc(k); SNDF (k, '01100'); Form1. StringGrid1. Cells
[k, 0]:='М'; end;
if
('Н' in T) then
begin S. Lines. Add ('Н
= '+' 01101'); inc(k); SNDF (k, '01101'); Form1. StringGrid1. Cells
[k, 0]:='Н'; end;
if
('О' in T) then
begin S. Lines. Add ('О
= '+' 01110'); inc(k); SNDF (k, '01110'); Form1. StringGrid1. Cells
[k, 0]:='О'; end;
if
('П' in T) then
begin S. Lines. Add ('П
= '+' 01111'); inc(k); SNDF (k, '01111'); Form1. StringGrid1. Cells
[k, 0]:='П'; end;
if
('Р' in T) then
begin S. Lines. Add ('Р
= '+' 10000'); inc(k); SNDF (k, '10000'); Form1. StringGrid1. Cells
[k, 0]:='Р'; end;
if
('С' in T) then
begin S. Lines. Add ('С
= '+' 10001'); inc(k); SNDF (k, '10001'); Form1. StringGrid1. Cells
[k, 0]:='С'; end;
if
('Т' in T) then
begin S. Lines. Add ('Т
= '+' 10010'); inc(k); SNDF (k, '10010'); Form1. StringGrid1. Cells
[k, 0]:='Т'; end;
if
('У' in T) then
begin S. Lines. Add ('У
= '+' 10011'); inc(k); SNDF (k, '10011'); Form1. StringGrid1. Cells
[k, 0]:='У'; end;
if
('Ф' in T) then
begin S. Lines. Add ('Ф
= '+' 10100'); inc(k); SNDF (k, '10100'); Form1. StringGrid1. Cells
[k, 0]:='Ф'; end;
if
('Х' in T) then
begin S. Lines. Add ('Х
= '+' 10101'); inc(k); SNDF (k, '10101'); Form1. StringGrid1. Cells
[k, 0]:='Х'; end;
if
('Ц' in T) then
begin S. Lines. Add ('Ц
= '+' 10110'); inc(k); SNDF (k, '10110'); Form1. StringGrid1. Cells
[k, 0]:='Ц'; end;
if
('Ч' in T) then
begin S. Lines. Add ('Ч
= '+' 10111'); inc(k); SNDF (k, '10111'); Form1. StringGrid1. Cells
[k, 0]:='Ч'; end;
if
('Ш' in T) then
begin S. Lines. Add ('Ш
= '+' 11000'); inc(k); SNDF (k, '11000'); Form1. StringGrid1. Cells
[k, 0]:='Ш'; end;
if
('Щ' in T) then
begin S. Lines. Add ('Щ
= '+' 11001'); inc(k); SNDF (k, '11001'); Form1. StringGrid1. Cells
[k, 0]:='Щ'; end;
if
('Ъ' in T) then
begin S. Lines. Add ('Ъ
= '+' 11010'); inc(k); SNDF (k, '11010'); Form1. StringGrid1. Cells
[k, 0]:='Ъ'; end;
if
('Ы' in T) then
begin S. Lines. Add ('Ы
= '+' 11011'); inc(k); SNDF (k, '11011'); Form1. StringGrid1. Cells
[k, 0]:='Ы'; end;
if
('Ь' in T) then
begin S. Lines. Add ('Ь
= '+' 11100'); inc(k); SNDF (k, '11100'); Form1. StringGrid1. Cells
[k, 0]:='Ь'; end;
if
('Э' in T) then
begin S. Lines. Add ('Э
= '+' 11101'); inc(k); SNDF (k, '11101'); Form1. StringGrid1. Cells
[k, 0]:='Э'; end;
if
('Ю' in T) then
begin S. Lines. Add ('Ю
= '+' 11110'); inc(k); SNDF (k, '11110'); Form1. StringGrid1. Cells
[k, 0]:='Ю'; end;
if
('Я' in T) then
begin S. Lines. Add ('Я
= '+' 11111'); inc(k); SNDF (k, '11111'); Form1. StringGrid1. Cells
[k, 0]:='Я'; end;
end;
procedure
TForm1. BitBtn1Click (Sender: TObject);
var
F, I, O:R;
h,
j, S:byte;
begin
Memo1.
Clear;
Memo2.
Clear;
Memo3.
Clear;
k:=0;
S:=0;
F:=['Я', 'К', 'У', 'Х', 'И', 'Н'];
I:=['Д', 'М', 'И', 'Т', 'Р'];
O:=['Е', 'Р', 'Г', 'В', 'И'];
perebor
(F, Memo1);
perebor
(I, Memo2);
perebor
(O, Memo3);
for
j:=1 to 5 do begin
for
h:=1 to 19 do begin
if
StringGrid1. Cells [h, j]='1' then inc(s);
end;
StringGrid1.
Cells [17, j]:=IntToStr(S);
S:=0;
(yegorov-p
Rulezzz;)}
end;
end;
procedure
TForm1. FormCreate (Sender: TObject);
var
g:byte;
begin
StringGrid1.
Cells [0,2]:='F1';
StringGrid1.
Cells [0,3]:='F2';
StringGrid1.
Cells [0,4]:='F3';
StringGrid2.
Cells [1,0]:='X1';
StringGrid2.
Cells [2,0]:='X2';
StringGrid2.
Cells [3,0]:='X3';
StringGrid2.
Cells [4,0]:='X4';
StringGrid2.
Cells [5,0]:='F1';
StringGrid2.
Cells [6,0]:='F2';
StringGrid2.
Cells [7,0]:='F3';
for
g:=0 to 15 do
StringGrid2.
Cells [0, g+1]:=IntToStr(g);
for
g:=0 to 7 do
StringGrid2.
Cells [1, g+1]:='0';
for
g:=8 to 15 do
StringGrid2.
Cells [1, g+1]:='1';
for
g:=0 to 3 do
StringGrid2.
Cells [2, g+1]:='0';
for
g:=4 to 7 do
StringGrid2.
Cells [2, g+1]:='1';
for
g:=8 to 11 do
StringGrid2.
Cells [2, g+1]:='0';
for
g:=12 to 15 do
StringGrid2.
Cells [2, g+1]:='1';
for
g:=1 to 2 do begin
StringGrid2.
Cells [3, g]:='0';
StringGrid2.
Cells [3, g+2]:='1';
StringGrid2.
Cells [3, g+4]:='0';
StringGrid2.
Cells [3, g+6]:='1';
StringGrid2.
Cells [3, g+8]:='0';
StringGrid2.
Cells [3, g+10]:='1';
StringGrid2.
Cells [3, g+12]:='0';
StringGrid2.
Cells [3, g+14]:='1';
end;
for
g:=1 to 16 do begin
if
g div 2 = g/2 then
StringGrid2.
Cells [4, g]:='1'
else
StringGrid2.
Cells [4, g]:='0';
end;
end;
Function
Dec2Bin (j:integer):string;
begin
result:='';
while
j>=1 do
begin
result:=IntToStr
(j mod 2)+result;
j:=j
div 2;
end;
end;
Function
Dec2BinDrob (j:real):string;
var
i:byte;
begin
result:='';
for
i:=1 to 11 do
begin
result:=FloatToStr
(int(j*2))+result;
j:=j*2;
if
int (j*2)>1 then j:=j‑1;
end;
end;
procedure
TForm1. BitBtn3Click (Sender: TObject);
var
p, p2, S, S2, S3:string;
i:byte;
begin
p:=Edit1.
Text;
p2:='0,'+Edit3.
Text;
S:=Dec2Bin
(StrToInt(p));
S2:=Dec2BinDrob
(StrToFloat(p2));
for
i:=11 downto 1 do begin
S3:=S3+S2
[i];
end;
Edit2.
Text:=S+'.'+S3;
end;
procedure
TForm1. BitBtn4Click (Sender: TObject);
var
i:byte;
P:string;
begin
for
i:=1 to 16 do begin
if
StringGrid2. Cells [5, i]='1' then begin
P:=StringGrid2.
Cells [1, i]+StringGrid2. Cells [2, i]+
StringGrid2.
Cells [3, i]+StringGrid2. Cells [4, i];
Label7.
Caption:=Label7. Caption+' '+P;
end;
end;
for
i:=1 to 16 do begin
if
StringGrid2. Cells [6, i]='1' then begin
P:=StringGrid2.
Cells [1, i]+StringGrid2. Cells [2, i]+
StringGrid2.
Cells [3, i]+StringGrid2. Cells [4, i];
Label8.
Caption:=Label8. Caption+' ' +P;
end;
end;
for
i:=1 to 16 do begin
if
StringGrid2. Cells [7, i]='1' then begin
P:=StringGrid2.
Cells [1, i]+StringGrid2. Cells [2, i]+
StringGrid2.
Cells [3, i]+StringGrid2. Cells [4, i];
Label9.
Caption:=Label9. Caption+' '+P;
end;
end;
end;
end.
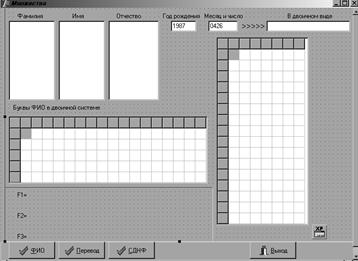
Рисунок 4.3
Форма для примера 2
4.4 Вопросы для самопроверки
1) Чем
отличается кортеж от обычного множества?
2) Приведите
пример использования кортежей в программировании.
3. Какие
операции над множествами Вы знаете?
4) Какой
способ существует для графического изображения множеств?
5) Приведите
пример универсального множества, которое используется в данной практической
работе.
6) Какие
операции (логические связки) из алгебры логики Вы знаете?
7) Возможно
ли провести аналогию между операциями над множествами и логическими операциями?
8) Какое
правило используется при построении СДНФ логической функции?
9) Какое
правило используется при построении СКНФ логической функции?
10) Каков
алгоритм перевода числа из десятичной системы счисления в двоичную систему
счисления?
11) Почему
логические функции и логические переменные часто называют двоичными?
12) Какая
связь существует между логическими функциями и функционированием компьютера,
отдельных его устройств?
Практическая работа № 5. Исследование
логических функций
Цель работы:
изучение существующих форм представления логических функций. Построение
совершенных нормальных форм логических функций. Построение таблиц истинности и
арифметических моделей логических функций в приложениях на Delphi.
Примечание:
все теоретические сведения, необходимые для выполнения данной работы, содержатся
в [25], в лекциях и в материалах семинарских занятий.
5.1 Задание
к работе
1. Используя
средства Excel и Delphi, построить таблицы истинности заданных логических
функций, если требуется, то предварительно упростить выражения, используя
законы алгебры логики и следствия из них.
2. Используя
средства Excel и Delphi, построить арифметические модели заданных логических
функций.
3. Представить
заданные логические функции в виде СДНФ, СКНФ и СПНФ.
4. Построить
логические функциональные схемы для заданных логических функций F1 и F2.
5. Сделать
выводы.
5.2
Практическая часть
5.2.1 Пример
выполнения
Задание: Построить таблицу
истинности, СДНФ, СКНФ, СПНФ и логические функциональные схемы для данных
логических функций:
F1=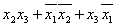
F2=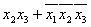 
Код программы
построения таблицы истинности логический функций:
Procedure
TForml. ButtonlClick (Sender: TObject);
var
xl, x2, x3:boolean; i:byte;
a1,
a2, a3: string;
begin
Stringgridl.
Cells [l, 0]:='xl';
Stringgridl.
Cells [2,0]:='x2';
Stringgridl.
Cells [3,0]:='x3';
Stringgrid1.
Cells [4,0]:=F1';
Stringgridl.
Cells [5,0]:='F2';
for
i:=l to 8 do begin Stringgrid1. Cells [0, i]:=inttostr (i‑1);
if
i<=4 then Stringgridl. Cells [l, i]:=’0’ else Stringgridl. Cells [l, i]:=1;
if
(i<=2) or (i=5) or (i=6) then Stringgridl. Cells [2, i]:='0’ else Stringgridl. Cells [2, i]:=' 1';
if
(i mod 2 >0) then Stringgridl. Cells [3, i]:='0' else Stringgridl. Cells [3,
i]:=1; end;
for
i:=l to 8 do begin
x1:=strtobool
(Stringgrid 1. Cells [1, i]);
x2:=strtobool
(Stringgridl. Cells [2, i]);
x3:=strtobool
(Stringgridl. Cells [3, i]);
if
(x2 and x3) or (not(xl) and not(x2)) or (x3 and not(xl)) then
Stringgridl.
Cells [4, i]:=’1’ else Stringgridl. Cells [4, i]:='0';
if
(x2 and x3) or (not(xl) and not(x2) and not(x3)) then Stringgridl. Cells [5, i]:=1
else Stringgridl. Cells [5, i]:='0'; end; end;
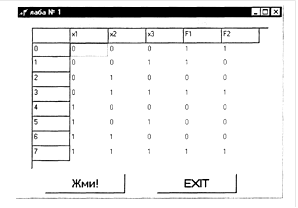
Рисунок 5.1
Форма с результатами
МДНФ:
F1 = 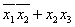
F2 = 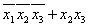
МКНФ:
F1 = 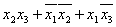
F2 = 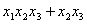
СПНФ:
F1 =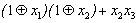
F2 =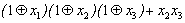
|
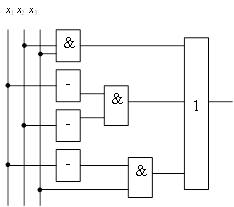
|
Рисунок 5.2
Логическая схема для МКНФ функции F1
|
5.2.2 Варианты
заданий
1)
Заданы
логические функции: F1= 1 на наборах 0, 3 и 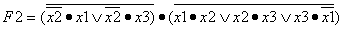
2)
Заданы
логические функции: F1= 1 на наборах 0, 1, 3 и 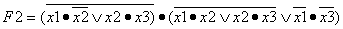
3)
Заданы
логические функции: F1= 1 на наборах 3, 7 и 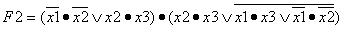
4)
Заданы
логические функции: F1= 1 на наборах 0, 1, 3, 7 и 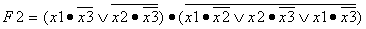
5)
Заданы
логические функции: F1= 1 на наборах 0,1,2,3,7 и 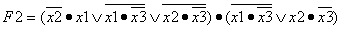
6)
Заданы
логические функции: F1= 1 на наборах 2,5,6 и 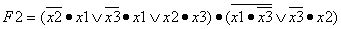
7)
Заданы
логические функции: F1= 1 на наборах 0, 2,5,7 и 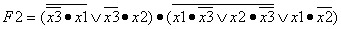
8)
Заданы
логические функции: F1= 1 на наборах 0, 1,3 и 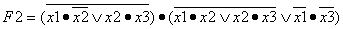
9)
Заданы
логические функции: F1= 1 на наборах 3,4,6,7 и 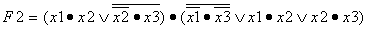
10)
Заданы
логические функции: 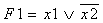 и и 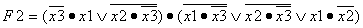
11)
Заданы
логические функции: 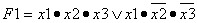 и и 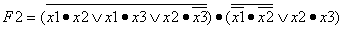
12)
Заданы
логические функции: 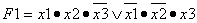 и и 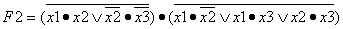
13)
Заданы
логические функции: 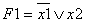 и и 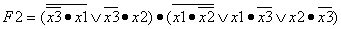
14)
Заданы
логические функции: 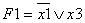 и и 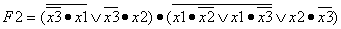
15)
Заданы
логические функции: 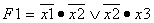 и и 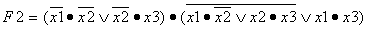
16)
Заданы
логические функции: 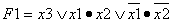 и и 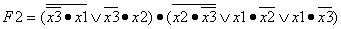
17)
Заданы
логические функции: 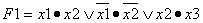 и и 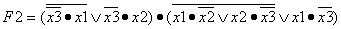
18)
Заданы
логические функции: 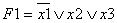 и и 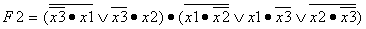
19)
Заданы
логические функции: 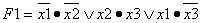 и и 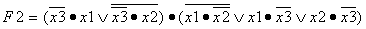
20)
Заданы
логические функции: 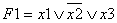 и и 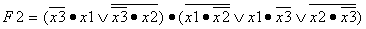
21)
Заданы
логические функции: 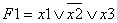 и и
22)
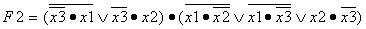
23)
Заданы
логические функции: 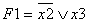 и и 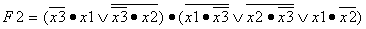
24)
Заданы
логические функции: 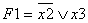 и и 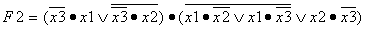
25)
Заданы
логические функции: 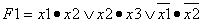 и и 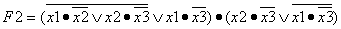
26)
Заданы
логические функции: 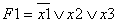 и и 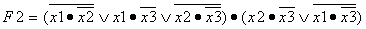
27)
Заданы
логические функции: 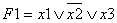 и и 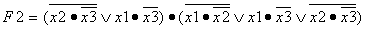
28)
Заданы
логические функции: 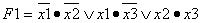 и и 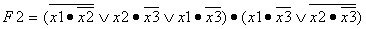
29)
Заданы
логические функции: 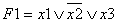 и и 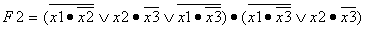
30)
Заданы
логические функции: 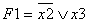 и и 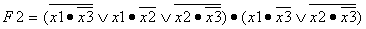
31)
Заданы
логические функции: 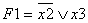 и и 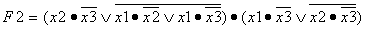
32)
Заданы
логические функции: F1=1 на наборах 4,5,7 и 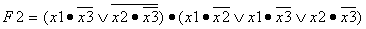
33)
Заданы
логические функции: F1=0 на наборах 2,4 и 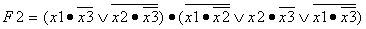
34)
Заданы
логические функции: 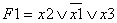 и и 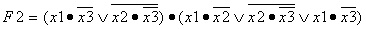
35)
Заданы
логические функции: 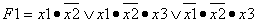 и и 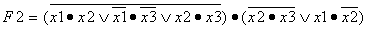
36)
Заданы
логические функции: 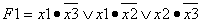 и и 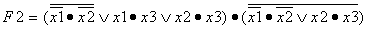
37)
Заданы
логические функции: 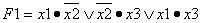 и и 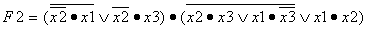
5.3 Вопросы для самопроверки
1) Какие
формы представления логических функций Вы знаете?
2) В каких
случаях, на Ваш взгляд, какие формы представления логических функций являются
наиболее предпочтительными?
3) Изобразите
общую схему таблицы истинности функции 4‑х переменных.
4) Каков
приоритет выполнения логических операций?
5) Какие
логические функции есть в алгоритмическом языке Object Pascal?
6) Дайте
определение логической функции многих переменных.
7) Приведите
пример тождественно ложной логической функции. Можно ли для этой функции
построить СДНФ?
8) Приведите
пример тождественно истинной логической функции. Можно ли для этой функции
построить СКНФ?
9) На
основании каких замен можно построить арифметическую модель логической функции?
10) Перечислите
законы алгебры логики.
11) Какие
следствия из законов алгебры логики Вы знаете?
12) Назовите
учёных, которые считаются основателями алгебры логики.
Практическая работа № 6. Изучение методов
минимизации логических функций
Цель работы:
применение изученных методов минимизации логических функций для решения
конкретных задач.
6.1 Краткие
теоретические сведения
Общая задача
минимизации логических функций сводится к построению в базисе Буля функции,
содержащей минимально возможное число двоичных переменных. Исходное выражение
логической функции может быть представлено формулой в любом базисе. Поэтому на
первом этапе осуществляется переход к нормальной форме формулы булевой функции,
как правило, совершенной дизъюнктивной нормальной форме.
F 0={×;Ú; – ;Å;«;®;½;¯} – сигнатура алгебры
логики;
F 1={×;Ú;–} – базис Буля;
F 2={×;–} – базис конъюнктивный;
F 3={Ú;–} – базис дизъюнктивный;
F 4={×;Å; 1} – базис Жегалкина;
F 5={¯} – базис Вебба;
F 6={½} – базис Шеффера;
F 7={®;–} – базис импликативный и т. д.
В таблицах 6.1–4
приведены формулы в некоторых базисах и для некоторых значений функции f (x1,
x2).
Таблица 6.1
Формулы, описывающие функции в базисах F0 и F5
|
fi
|
Формулы в базисах F
0 и F 5
|
|
f1
|
(x1×x2)=(x1¯x2)¯(x1¯x2)
|
|
f6
|
(x1Åx2)=[(x1¯x1)¯(x2¯x2)]¯(x1¯x2)
|
|
f7
|
(x1Úx2)=(x1¯x2)¯(x1¯x2)
|
|
f9
|
(x1«x2)=[x1¯(x2¯x2)]¯[x2¯(x1¯x1)]
|
|
f13
|
(x1®x2)=[x2¯(x1¯x1)]¯[x2¯(x1¯x1)]
|
|
f14
|
(x1÷x2)=[(x1¯x1)¯(x2¯x2)]¯ [(x1¯x1)¯(x2¯x2)]
|
Таблица 6.2
Формулы, описывающие функции в базисах F0 и F2
|
Fi
|
Формулы в базисах F
0 и F2
|
|
f6
|
(x1Åx2)=ù(`x1×`x2)×ù(x1×x2)
|
|
f7
|
(x1Úx2)=ù(`x1×`x2)
|
|
f8
|
(x1¯x2)=(`x1×`x2)
|
|
f9
|
(x1«x2)=ù(x1×`x2)×ù(`x1×x2)
|
|
f13
|
(x1®x2)=ù(x1×`x2)
|
|
f14
|
(x1÷x2)=ù(x1×x2)
|
Таблица 6.3
Формулы, описывающие функции в базисах F0 и F3
| Fi |
Формулы в базисах F 0 и
F3 |
|
f6
|
(x1×x2)=ù(`x1Ú`x2)
|
|
f7
|
(x1Åx2)=ù(`x1Úx2)Úù(x1Ú`x2)
|
|
f8
|
(x1¯x2)=ù(x1Úx2)
|
|
f9
|
(x1«x2)=(x1Úx2)Úù(`x1Ú`x2)
|
|
f13
|
(x1®x2)=(`x1Úx2)
|
|
f14
|
(x1½x2)=(`x1Ú`x2)
|
Таблица 6.4
Формулы, описывающие функции в базисах F0 и F6
|
Fi
|
Формулы в базисах F
0 и F 6
|
|
f1
|
(x1×x2)=(x1½x2)½(x1½x2)
|
|
f6
|
(x1Åx2)=[x1½(x2½x2)]½[x2½ (x1½x1)]
|
|
f7
|
(x1Úx2)=(x1½x2)½(x1½x2)
|
|
f8
|
(x1¯x2)=[(x1½x1)½(x2½x2)½ (x2½x2)]
|
|
f9
|
(x1«x2)=[(x1½x1)½(x2½x2)]½ (x1½x2)]
|
|
f13
|
(x1®x2)=(x1½(x2½x2).
|
6.2 Практическая часть
6.2.1 Задание
к работе
1. Минимизировать
функции с помощью карт Карно или таблицы Куайна.
2. Используя средства
Excel и Delphi, построить таблицы истинности заданных логических функций.
3. Сделать
выводы.
6.2.2
Примеры выполнения
Пример 1.
Задание:
1.
Минимизировать функции с помощью таблицы Куайна.
2. Используя
программные средства Delphi, построить таблицы истинности заданных логических
функций.
1 Минимизация
с помощью таблицы Куайна:
Пусть функция
F представлена в виде СДНФ
F1СДНФ = 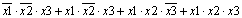
Таблица 6.5
таблица Куайна
| х1x2x3 |
001 |
101 |
110 |
111 |
|
0 0 1
1 – 1
1 1 –
|
1 |
1 |
1 |
1 |
Упростим F1СДНФ, получим:
F1МДНФ =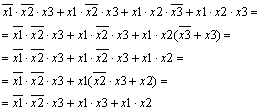
Как мы видим,
результат, полученный по таблице Куайна, совпадает с F1МДНФ.
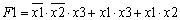
Рисунок 6.1
Графический интерфейс
2 Процедура
основного обработчика
procedure
TForm1. BitBtn1Click (Sender: TObject);
Var
i:byte;
x1,
x2, x3:boolean;
begin
for
i:=1 to 8 do begin
StringGrid1.
Cells [0, i]:=IntToStr (i‑1);
If
i<=4 then StringGrid1. Cells [1, i]:='0' else StringGrid1. Cells [1, i]:='1';
If
(i<=2) or ((i>=5) and (i<7)) then StringGrid1. Cells [2, i]:='0' else
StringGrid1. Cells [2, i]:='1';
If
(i mod 2>0) then StringGrid1. Cells [3, i]:='0' else StringGrid1. Cells [3, i]:='1';
If
i<=4 then StringGrid1. Cells [4, i]:='1' else StringGrid1. Cells [4, i]:='0';
If
(i<=2) or ((i>=5) and (i<7)) then StringGrid1. Cells [5, i]:='1' else
StringGrid1. Cells [5, i]:='0';
x1:=StrToBool
(StringGrid1. Cells [1, i]);
x2:=StrToBool
(StringGrid1. Cells [2, i]);
x3:=StrToBool
(StringGrid1. Cells [3, i]);
if
(not (x1) and not (x2) and x3) or (x1 and x3) or (x1 and x2)
then
StringGrid1. Cells [6, i]:='1'
else
StringGrid1. Cells [6, i]:='0';
end;
end;
Пример 2.
Пусть будут заданы номера наборов четырех переменных, на которых логическая
функция принимает единичное значение: f (2,5,6,7,10,12,13,14)=1.
Выразим эту
логическую функцию в СДНФ (символ конъюнкции писать не будем):
f (0010,0101, 0110, 0111,
1010, 1100, 1101, 1110) =
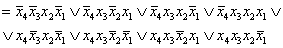 . .
Таблица 6.6
карта Карно для функции 4‑х переменных
|
|
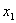
|
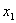
|
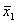
|
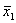
|
|
|
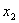
|
1100 |
1110 |
0110 |
0100 |
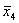
|
|
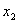
|
1101 |
1111 |
0111 |
0101 |
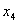
|
|
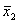
|
1001 |
1011 |
0011 |
0001 |
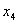
|
|
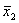
|
1000 |
1010 |
0010 |
0000 |
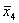
|
|
|
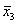
|
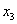
|
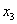
|
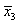
|
|
Таблица 6.7
заполненная карта
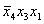 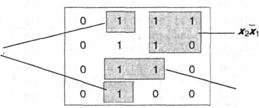 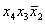
Карта Карно
для четырех переменных представлена в виде таблицы 6.6. Каждая клетка карты
соответствует конституенте. Заполненная карта представлена таблицы 6.7.
Согласно закону склеивания, две смежные конституенты с единичными значениями
всегда можно объединить для получения соответствующей импликанты. Причем смежными
считаются и те, которые лежат на границах карты. Какие именно единицы требуется
объединить для получения подходящей импликанты, легко определить визуально [5].
В соответствии с законом идемпотентности одна и та же единица таблицы 6.7 может
склеиваться с двумя или тремя смежными единицами.
6.3 Вопросы для
самопроверки
1)
Перечислите законы алгебры логики, которые наиболее часто используются при
упрощении сложных логических выражений?
2)
Перечислите правила (следствия), полученные из законов алгебры логики, которые
обычно используются при упрощении сложных логических выражений?
3) Какое логическое
выражение называется конституентой?
4) Какое
логическое выражение называется импликантой?
5) В чём
заключается задача минимизации логической функции? Основная операция,
используемая при минимизации логической функции?
6) Как
выглядит карта Карно для логической функции трёх переменных? Каков принцип е
построения?
7) В чём
заключается смысл метода карт Карно?
8) Если
логическая функция не полностью определена, то каким образом можно задать
формулу, описывающую данную функцию?
9) Требует ли
метод Куайна этапа предварительной (аналитической) минимизации?
10) Каким
образом строится таблица Куайна?
11) По какому
принципу выбираются импликанты, образующие минимизированное представление
логической функции в методе Куайна?
12) Кратко
опишите принцип, на котором базируется метод сочетания индексов.
13)
Перечислите известные Вам методы минимизации логических функций.
14)
Обязательным ли является условие того, что исходное выражение, описывающее
логическую функцию, которое требуется минимизировать, является дизъюнктивной
нормальной формой?
15) Какой из
методов минимизации логических функций, на Ваш взгляд, проще поддаётся
алгоритмизации?
Практическая работа № 7. Моделирование
работы узлов компьютера с помощью Еxcel
7.1
Теоретическая часть
В основе
работы логических схем и устройств компьютера лежит специальный математический
аппарат, называемый математической логикой [21].
Студентам
предлагается при изучении данной темы не только спроектировать реальные узлы
компьютера, но и смоделировать их работу с помощью электронной таблицы Excel.
Это сделает изучение темы более интересным, полезным. Появится полное
впечатление, что создана действующую модель реального узла компьютера.
Поскольку
логическая функция осуществляет однозначное отображение множества наборов {(x1;
x2;……; xn)}, в которых компоненты xi принимают значение из множества {0;
1}, в множество y={0; 1}, то для её реализации могут быть использованы
переключательные или вентильные элементы. Переключательные элементы обладают
двумя состояниями и двухсторонней проводимостью. Такими элементами являются
выключатели, реле, ключи, коммутаторы и т. п. Вентильные элементы
обладают также двумя состояниями, но, как правило, односторонней проводимостью.
Такими элементами являются диоды, триоды, микросхемы и т. п. Интегральные
микросхемы в одном корпусе реализуют большое число логических функций [13].
Чтобы
упорядочить проектирование и разработку различных логических или
переключательных устройств, разработаны международной и общероссийский
стандарты для обозначения различных логических функций.
В таблице 7.1
приведены основные условные обозначения логических функций [2].
Схемы,
формируемые вентильными элементами, называют комбинационными схемами. Если
комбинационная схема реализует одну булеву функцию, то её называют
одновыходовой комбинационной схемой, если несколько, то – многовыходовой
комбинационной схемой.
Схема
синтезируется из типовых логических элементов подобно тому, как сложная функция
получается суперпозицией более простых функций.
Например, на
рисунке 7.1 приведена комбинационная схема, реализующая функцию fmin.
Рисунок 7.1
Комбинационная схема для fmin
Таблица 7.1
Стандартные обозначения логических элементов
|
Логическая функция
(имя, значение)
|
обозначение по
ГОСТ 2.743–82
|
|
«ИЛИ», дизъюнкция
f (x1; x2)=(x1Úx2)
|
|
|
«И», конъюнкция
f (x1; x2)=(x1×x2)
|
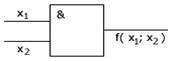
|
|
«ИЛИ – НЕ», стрелка Пирса
f (x1; x2)=
÷ (x1Úx2)=(x1¯x2)
|
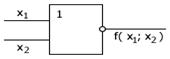
|
|
«И – НЕ», штрих Шеффера
f (x1; x2)=
÷ (x1×x2)=(x1÷ x2)
|
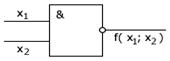
|
|
«НЕ – ИЛИ», импликация
f (x1; x2)=(x1Úx2)=(x1®x2)
|
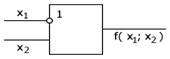
|
|
Сложение по mod
2
f (x1; x2)=(x1Åx2)
|
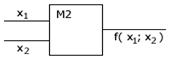
|
Понятие
о синтезе логических схем
Логические
устройства компьютера выполняют необходимые преобразования поступающей на вход
цифровой информации. При синтезе таких устройств большое применение находит
математический аппарат алгебры логики.
Обычно
процесс синтеза логических устройств состоит из следующих основных этапов:
o
На
основании анализа функций, которые должны выполняться данным устройством,
формируются логические условия его функционирования в виде соответствующей
таблицы истинности.
o
По
построенной таблице истинности записывается аналитическое выражение логической
функции в виде СДНФ или в СКНФ.
o
Производится
минимизация логической функции.
o
По
упрощенной логической формуле строится функциональная схема устройства, причем
предпочтение отдается минимальному числу и однородности логических элементов.
Среди
логических узлов компьютера широкое распространение получили комбинационные
автоматы (схемы). Такой автомат в общем случае представляются в виде
многополюсника, имеющего r входов т1, т2,…, тr и l выходов k1,
k2,…, kl. Поступающая на вход автомата информация задается
набором сигналов М (т1, т2,…, тr), образующим входное слово. При этом в
любой дискретный момент времени t. совокупность выходных сигналов – выходное
слово K (k1, k2,…, kl) – полностью определяется
входным словом М, поступившим в тот же момент времени. При изменении
набора входных сигналов М меняется набор выходных сигналов K.
Таким образом, выходные сигналы комбинационного автомата полностью определяются
входными сигналами и не зависят от внутреннего состояния автомата. Эти автоматы
не имеют памяти. Именно о синтезе таких комбинационных автоматов (схем) и
пойдет речь далее.
Построение
компьютера ведется по следующей цепочке:
элементы →
узлы → устройства.
Элементы по
своему назначению делятся на следующие группы: логические; запоминающие; вспомогательные.
Нас
интересуют логические элементы – на их основе строятся комбинационные схемы. К
числу основных логических элементов, применяемых в ЭВМ и образующих функционально
полный набор (т. е. такой набор элементов, с помощью которого может быть
реализована любая сложная логическая функция), относятся логические элементы И
(конъюнктор), ИЛИ (дизъюнктор), НЕ (инвертор). Хотя в ряде случаев некоторые
логические выражения могут быть проще реализованы с помощью более сложных
логических элементов, таких, как И-НЕ, ИЛИ-НЕ, И-ИЛИ-НЕ, ограничимся
использованием первой группы элементов.
Узел – это
совокупность функционально связанных между собой элементов. Узлы компьютера по
своему функциональному назначению делятся на следующие группы: регистры; дешифраторы;
шифраторы; схемы сравнения кодов; электронные счетчики; сумматоры.
7.2 Практическая
часть
Спроектируем
некоторые из узлов. Вся работа от построения таблиц истинности соответствующего
узла до вычерчивания его схемы будет представлена непосредственно в Excel. Все
соответствующие этапы синтеза будут иметь на рабочих листах соответствующую
нумерацию (см. выше). Для того чтобы не загромождать рабочий лист, в
большинстве случаев не приводится минимизация функций, введены сразу упрощенные
логические выражения.
Excel имеет в
своем арсенале логические функции, представленные в окне Мастера функций,
показанном на рисунке 7.2.
Рисунок 7.2
Иллюстрация к использованию Мастера функций
В качестве
аргументов логические функции И, ИЛИ, НЕ одинаково трактуют значения «0» и
«ЛОЖЬ», 1 и «ИСТИНА», а в качестве результата выдают только значения «ЛОЖЬ» или
«ИСТИНА». Поэтому для перехода от значений «ЛОЖЬ» и «ИСТИНА» к привычным 0 и 1
используется функция ЕСЛИ.
7.2.1 Схемы
сравнения кодов
Организация
сравнения двух двоичных чисел заключается в выработке признака равенства
(равнозначности) или признака неравенства (неравнозначности) двух сравниваемых
чисел. Ограничимся признаком равенства.
Одноразрядная
схема сравнения кодов
Значение
признака равенства q при сравнении одноразрядных переменных описывается
таблицей истинности, представленной на рисунке 7.3.
В ячейку в E7
введена формула: =ЕСЛИ (C7=D7; 1; 0), которая затем скопирована в
ячейки D8:D10.
Значение q1
функции виде СДНФ: 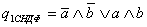 . .
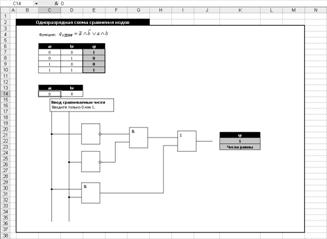
Рисунок 7.3
Образец выполнения работы
Упрощение
выражения не требуется, пункт 3 порядка проектирования логических схем
отсутствует.
Схема имеет
вид, представленный на рисунке 7.3. Схема начерчена непосредственно в Excel с
помощью панели рисования с использованием таких приемов, как копирование
повторяющихся элементов, группировка.
Дальнейшая
работа проделана для того, чтобы получить действующую модель схемы, которая при
подаче входных сигналов (сравниваемых одноразрядных двоичных чисел) будет
выдавать выходные сигналы (результат сравнения).
Ячейки C14
и D14 отведены для ввода сравниваемых одноразрядных двоичных чисел. Им
присвоены имена а и b соответственно.
Установлена
проверка данных на корректность (ввод только 0 и 1). (рисунки 7.4 – 7.5.)

Рисунок 7.4
Подсказка при вводе значений
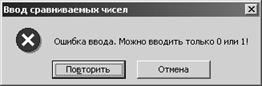
Рисунок 7.5
Сообщение об ошибке, в случае ввода некорректных данных
Для этого
ячейки C14 и D14 выделены и выполнена команда Данные, Проверка. В
диалоговом окне Проверка вводимых значений установить нужные параметры (рисунки
7.6, а-в).
|
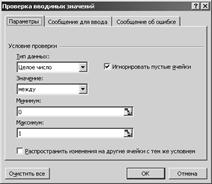
Рисунок 7.6 а
Настройка проверки вводимых значений
|
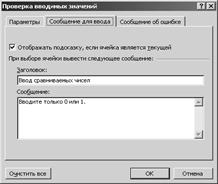
Рисунок 7.6 б
Настройка проверки вводимых значений
|
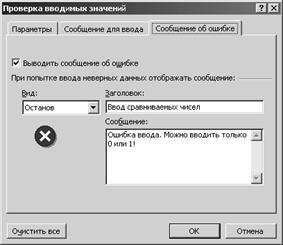
Рисунок 7.6 в-Настройка
проверки вводимых значений
В ячейку K22
введена формула:
=ЕСЛИ (ИЛИ(И (НЕ(C14);
НЕ(D14)); И (C14; D14))=ИСТИНА; 1; 0).
Функция ЕСЛИ
используется лишь для преобразования значения «ИСТИНА» в 1, а значения «ЛОЖЬ» в
0.
В ячейку K23
введена формула:
=ЕСЛИ (K22=1;
«Числа равны»; «Числа не равны»).
Для того
чтобы случайно что-то не испортить на листе, лист защищен, кроме ячеек, в
которые вводятся сравниваемые числа. Эти ячейки выделены, и выполнена команда
Формат, Ячейка, на вкладке Защита снят флажок Защищаемая ячейка. Затем
выполнена команда Сервис, Защита, Защитить лист.
На рисунке 7.3
показан вариант, когда на входы схемы аi, и bi поступают два
нуля, на выходе схемы имеем q1 (числа равны). Подавая на входы другие
комбинации 0 и 1, можно увидеть, что схема работает точно так, как описывает
таблица истинности. Можно дополнительно ввести формулы для проверки сигналов на
выходах любых элементов схемы.
Многоразрядная
схема сравнения кодов
Признак
равенства двухразрядных чисел q принимает значение 1, если выполняется
попарно равенство всех разрядов двоичных чисел.
Для примера
приведена двухразрядная схема (рисунок 7.7), что связано лишь с тем, что
неудобно рассматривать работу схемы, если она выходит за пределы экрана.
Двухразрядная схема состоит из двух одноразрядных схем.
Ячейки C7
и D7 отведены для поразрядного ввода первого числа, им присвоены имена a1
и а0 соответственно. Ячейки E7 и F7 отведены для ввода
второго числа, им присвоены имена b1 и b0 соответственно.
В ячейку L7
введена формула для выдачи результата сравнения старших разрядов чисел:
=ИЛИ (И(НЕ(C7);
НЕ(E7)); И (C7; E7)).
В ячейку L46
введена формула для выдачи результата сравнения младших разрядов чисел:
=ИЛИ (И(НЕ(F7);
НЕ(D7)); И (F7; D7)).
В ячейку O22
введена формула для выдачи признака равенства чисел:
=ЕСЛИ (И(L46;
L7)=ИСТИНА; 1; 0).
В ячейку O23
введена формула для выдачи сообщения о результате сравнения чисел:
=ЕСЛИ (O22=1;
«Числа равны»; «Числа не равны»).
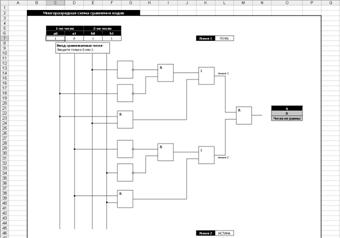
Рисунок 7.7
Двухразрядная схема сравнения кодов
На рисунке 7.7
представлен результат сравнения чисел 10 и 11. На экране результат сравнения
равен 0 и выдано сообщение «Числа не равны».
7.2.2 Дешифраторы
Дешифратором
(избирательной схемой) называется комбинационная логическая схема, в которой
определенная комбинация входных сигналов вызывает появление сигнала на одной
определенной выходной шине.
Если
количество двоичных разрядов дешифрируемого числа обозначить через n, то число выходов
дешифратора равно К = 2n.
В компьютере
с помощью дешифраторов осуществляется выборка необходимых ячеек запоминающих
устройств, расшифровка кода операции с подачей управляющих сигналов на те
элементы, узлы и устройства машины, которые связаны с выполнением данной операции.
Дешифратор
на 2 входа
Функционирование
дешифратора, имеющего 2 входа и 4 выхода, описывается таблицей истинности,
представленной на рисунке 7.8.
Выражения для
функций F1, F2, F3, F4 в виде СДНФ, реализуемые соответствующими
выходами схемы: 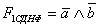 , , 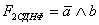 , , 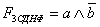 , , 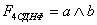 . .
Упрощение
выражения не требуется, пункт 3 порядка проектирования логических схем
отсутствует.
Схема имеет
вид, представленный на рисунке 7.8.

Рисунок 7.8
Дешифратор на 2 входа
Ячейки C13
и D13 отведены для ввода комбинации входных сигналов. Им присвоены имена
а и b соответственно.
Установлена
проверка данных на корректность (ввод только 0 и 1).
В ячейку J19
введена формула:
=И (НЕ(C13); НЕ(D13)).
В ячейку J26
введена формула:
=И (НЕ(C13); D13).
В ячейку J32
введена формула:
=И (НЕ(D13); C13).
В ячейку J38
введена формула:
=И (C13; D13).
В ячейки J20,
J27, J33, J39 введены формулы для преобразования значения
«ИСТИНА» в 1, а значения «ЛОЖЬ» в 0.
Лист защищен,
за исключением ячеек, в которые вводится входной код.
На рисунке 7.8
показан вариант, когда на входы схемы а и b поступают 0 и 0
соответственно. Сигнал 1 появляется лишь на выходе F1.
Подавая на
входы другие комбинации 0 и 1, можно увидеть, что схема работает точно так, как
описывает таблица истинности. Можно дополнительно ввести формулы для проверки
сигналов на выходах любых элементов схемы.
Для большей
наглядности на рабочем листе снята сетка, для чего выполнена команда Сервис,
Параметры и на вкладке Вид снят флажок Сетка.
С помощью
данной схемы легко показать (безусловно, упрощенно) применение дешифратора для
расшифровки кодов операций. Примите соглашение, что код 00 соответствует
сложению, 01 – вычитанию, 10 – делению, 11 – умножению. Вместо обозначений
выходов Fl, F2, F3 и F4 сделайте подписи
«Сложение», «Вычитание», «Деление», «Умножение». Тогда при появлении
определенной комбинации входных сигналов кода операции на входе дешифратора
будет показано, какую операцию следует выполнять, так как 1 появится лишь на
выходе, соответствующем этой операции. Безусловно, следует сказать, что,
например, дешифратор на 8 входов, имеющий полный набор выходных шин, сможет
расшифровать 28 = 256 различных кодов операций.
7.3 Задания
к работе
1. Выполнить
логическое проектирование дешифратора на четыре входа и четыре выхода по
индивидуальному заданию, приведённому в таблице 7.3 [15].
2. Для одной
из предложенных булевых функции системы:
Написать СКНФ
по данным таблицы 7.3.
Написать СДНФ
по данным таблицы 7.3.
Минимизировать
булеву функцию методом Квайна.
Минимизировать
булеву функцию, используя карты Карно.
3. Сравнить
результаты минимизации.
4. Выполнить
логическое проектирование схемы, реализующей минимальную булеву функцию,
используя элементы на два входа и один выход.
5. Для
системы частично определённых булевых функций (таблица 7.2): минимизировать их
описание, используя карты Карно.
Выполнить
логическое проектирование схемы, реализующей минимизированную систему булевых
функций, используя элементы на два входа и один выход.
Таблица 7.2
Значение частично определённых функций fi (x1; x2; x3; x4)
| Аргумент |
Индекс i
логической функции fi (x1; x2; x3; x4)
|
|
x1
|
x2
|
x3
|
x4
|
01 |
02 |
03 |
04 |
05 |
06 |
07 |
08 |
09 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
| 0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
* |
* |
* |
* |
1 |
1 |
* |
* |
* |
* |
| 1 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
* |
* |
* |
* |
* |
* |
* |
* |
1 |
| 0 |
1 |
0 |
0 |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
* |
* |
* |
* |
* |
* |
1 |
1 |
| 1 |
1 |
0 |
0 |
* |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
* |
* |
* |
* |
1 |
1 |
1 |
| 0 |
0 |
1 |
0 |
* |
* |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
* |
* |
1 |
1 |
1 |
0 |
| 1 |
0 |
1 |
0 |
* |
* |
* |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
1 |
1 |
1 |
0 |
0 |
| 0 |
1 |
1 |
0 |
* |
* |
* |
* |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
1 |
0 |
0 |
0 |
| 1 |
1 |
1 |
0 |
1 |
* |
* |
* |
* |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
0 |
0 |
| 0 |
0 |
0 |
1 |
1 |
1 |
* |
* |
* |
* |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
| 1 |
0 |
0 |
1 |
1 |
1 |
1 |
* |
* |
* |
* |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
| 0 |
1 |
0 |
1 |
0 |
1 |
1 |
1 |
* |
* |
* |
* |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
| 1 |
1 |
0 |
1 |
0 |
0 |
1 |
1 |
1 |
* |
* |
* |
* |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
| 0 |
0 |
1 |
1 |
0 |
0 |
0 |
1 |
1 |
1 |
* |
* |
* |
* |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
| 1 |
0 |
1 |
1 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
* |
* |
* |
* |
1 |
1 |
1 |
0 |
0 |
1 |
1 |
1 |
* |
| 0 |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
* |
* |
* |
* |
1 |
1 |
1 |
1 |
1 |
1 |
* |
* |
| 1 |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
* |
* |
* |
* |
1 |
1 |
1 |
1 |
* |
* |
* |
| Аргмент |
Индекс i логической
функции fi (x1; x2; x3; x4)
|
|
x1
|
x2
|
x3
|
x4
|
21 |
22 |
23 |
24 |
25 |
26 |
27 |
28 |
29 |
30 |
31 |
32 |
33 |
34 |
35 |
36 |
37 |
38 |
39 |
40 |
| 0 |
0 |
0 |
0 |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
1 |
1 |
1 |
1 |
1 |
0 |
0 |
0 |
| 1 |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
1 |
1 |
1 |
1 |
1 |
1 |
0 |
0 |
| 0 |
1 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
0 |
0 |
0 |
1 |
1 |
1 |
1 |
1 |
1 |
0 |
| 1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
* |
* |
0 |
0 |
0 |
1 |
1 |
1 |
1 |
1 |
1 |
| 0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
* |
* |
* |
* |
0 |
0 |
0 |
1 |
1 |
1 |
1 |
1 |
| 1 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
* |
* |
* |
* |
* |
* |
0 |
0 |
0 |
1 |
1 |
1 |
1 |
| 0 |
1 |
1 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
* |
* |
* |
* |
* |
* |
* |
* |
0 |
0 |
0 |
1 |
1 |
1 |
| 1 |
1 |
1 |
0 |
0 |
0 |
1 |
1 |
1 |
* |
* |
* |
* |
1 |
0 |
* |
* |
* |
* |
0 |
0 |
0 |
1 |
1 |
| 0 |
0 |
0 |
1 |
0 |
1 |
1 |
1 |
* |
* |
* |
* |
1 |
1 |
0 |
0 |
* |
* |
* |
* |
0 |
0 |
0 |
1 |
| 1 |
0 |
0 |
1 |
1 |
1 |
1 |
* |
* |
* |
* |
1 |
1 |
1 |
0 |
0 |
0 |
* |
* |
* |
* |
0 |
0 |
0 |
| 0 |
1 |
0 |
1 |
1 |
1 |
* |
* |
* |
* |
1 |
1 |
1 |
0 |
1 |
0 |
0 |
0 |
* |
* |
* |
* |
0 |
0 |
| 1 |
1 |
0 |
1 |
1 |
* |
* |
* |
* |
1 |
1 |
1 |
0 |
0 |
1 |
1 |
0 |
0 |
0 |
* |
* |
* |
* |
0 |
| 0 |
0 |
1 |
1 |
* |
* |
* |
* |
1 |
1 |
1 |
0 |
0 |
0 |
1 |
1 |
1 |
0 |
0 |
0 |
* |
* |
* |
* |
| 1 |
0 |
1 |
1 |
* |
* |
* |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
1 |
0 |
0 |
0 |
* |
* |
* |
| 0 |
1 |
1 |
1 |
* |
* |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
1 |
1 |
0 |
0 |
0 |
* |
* |
| 1 |
1 |
1 |
1 |
* |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
1 |
1 |
1 |
0 |
0 |
0 |
* |
| Аргумент |
Индекс i логической
функции fi (x1; x2; x3; x4)
|
|
x1
|
x2
|
x3
|
x4
|
41 |
42 |
43 |
44 |
45 |
46 |
47 |
48 |
49 |
50 |
51 |
52 |
53 |
54 |
55 |
56 |
57 |
58 |
59 |
60 |
| 0 |
0 |
0 |
0 |
* |
* |
* |
* |
0 |
0 |
* |
* |
* |
* |
0 |
0 |
0 |
1 |
1 |
1 |
1 |
1 |
1 |
0 |
| 1 |
0 |
0 |
0 |
0 |
* |
* |
* |
* |
* |
* |
* |
* |
0 |
0 |
0 |
1 |
1 |
1 |
1 |
1 |
1 |
0 |
0 |
| 0 |
1 |
0 |
0 |
0 |
0 |
* |
* |
* |
* |
* |
* |
0 |
0 |
0 |
1 |
1 |
1 |
1 |
1 |
1 |
0 |
0 |
0 |
| 1 |
1 |
0 |
0 |
0 |
0 |
0 |
* |
* |
* |
* |
0 |
0 |
0 |
1 |
1 |
1 |
1 |
1 |
1 |
0 |
0 |
0 |
* |
| 0 |
0 |
1 |
0 |
1 |
0 |
0 |
0 |
* |
* |
0 |
0 |
0 |
1 |
1 |
1 |
1 |
1 |
1 |
0 |
0 |
0 |
* |
* |
| 1 |
0 |
1 |
0 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
1 |
1 |
1 |
0 |
0 |
0 |
* |
* |
* |
| 0 |
1 |
1 |
0 |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
1 |
1 |
1 |
0 |
0 |
0 |
* |
* |
* |
* |
| 1 |
1 |
1 |
0 |
1 |
1 |
1 |
1 |
0 |
0 |
1 |
1 |
1 |
1 |
1 |
1 |
0 |
0 |
0 |
* |
* |
* |
* |
0 |
| 0 |
0 |
0 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
0 |
0 |
0 |
* |
* |
* |
* |
0 |
0 |
| 1 |
0 |
0 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
0 |
0 |
0 |
* |
* |
* |
* |
0 |
0 |
0 |
| 0 |
1 |
0 |
1 |
0 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
0 |
0 |
0 |
* |
* |
* |
* |
0 |
0 |
0 |
1 |
| 1 |
1 |
0 |
1 |
0 |
0 |
1 |
1 |
1 |
1 |
1 |
1 |
0 |
0 |
0 |
* |
* |
* |
* |
0 |
0 |
0 |
1 |
1 |
| 0 |
0 |
1 |
1 |
0 |
0 |
0 |
1 |
1 |
1 |
1 |
0 |
0 |
0 |
* |
* |
* |
* |
0 |
0 |
0 |
1 |
1 |
1 |
| 1 |
0 |
1 |
1 |
* |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
0 |
* |
* |
* |
* |
0 |
0 |
0 |
1 |
1 |
1 |
1 |
| 0 |
1 |
1 |
1 |
* |
* |
0 |
0 |
0 |
0 |
0 |
0 |
* |
* |
* |
* |
0 |
0 |
0 |
1 |
1 |
1 |
1 |
1 |
| 1 |
1 |
1 |
1 |
* |
* |
* |
0 |
0 |
0 |
0 |
* |
* |
* |
* |
0 |
0 |
0 |
1 |
1 |
1 |
1 |
1 |
1 |
| Таблица 7.3 |
| Вариант |
Логические функции |
| 1 |
(f2; f1; f3;
f4)
|
| 2 |
(f4; f3; f5;
f6)
|
| 3 |
(f6; f5; f7;
f8)
|
| 4 |
(f8; f7; f9;
f10)
|
| 5 |
(f10; f9;
f11; f12)
|
| 6 |
(f12; f11;
f13; f14)
|
| 7 |
(f14; f13;
f15; f16)
|
| 8 |
(f16; f15;
f17; f18)
|
| 9 |
(f18; f17;
f19; f20)
|
| 10 |
(f20; f19;
f21; f22)
|
| 11 |
(f22; f21;
f23; f24)
|
| 12 |
(f24; f23;
f25; f26)
|
| 13 |
(f26; f25;
f27; f28)
|
| 14 |
(f28; f27;
f29; f30)
|
| 15 |
(f30; f29;
f1; f2)
|
| 16 |
(f1; f3; f5;
f7)
|
| 17 |
(f3; f5; f7;
f9)
|
| 18 |
(f5; f7; f9;
f11)
|
| 19 |
(f7; f9; f11;
f13)
|
| 20 |
(f9; f11;
f13; f15)
|
| 21 |
(f11; f13;
f15; f17)
|
| 22 |
(f13; f15;
f17; f19)
|
| 23 |
(f15; f17;
f19; f21)
|
| 24 |
(f17; f19;
f21; f23)
|
| 25 |
(f19; f21;
f23; f25)
|
| 26 |
(f21; f23;
f25; f27)
|
| 27 |
(f23; f25;
f27; f29)
|
| 28 |
(f25; f27;
f29; f1)
|
| 29 |
(f27; f29;
f1; f3)
|
| 30 |
(f29; f1;
f3; f5)
|
7.4 Вопросы для самопроверки
1) Вычисление
по алгоритму можно рассматривать как некоторый процесс. Перечислите три в
принципе различных процесса.
2) Какими
множествами описывается конечный автомат?
3) С рядом
каких упрощающих предположений связано понятие конечного автомата?
4) Какие
вопросы рассматриваются в теории автоматов?
5)
Математической моделью каких устройств является конечный автомат?
6) Приведите
пример конечного и бесконечного автоматов.
7) Дайте
определение логического конечного автомата.
8) Какие Вы
знаете стандартные обозначения элементов, используемые при составлении
логических схем?
9) Какие
классы логических конечных автоматов Вы знаете?
10) Что такое
такт логического конечного автомата?
11) Приведите
пример конечного автомата без памяти.
12) Приведите
пример конечного автомата с памятью.
13) Приведите
пример конечного автомата с обратной связью по выходу.
14) В чём
заключается задача минимизации числа состояний автомата?
Список литературы
1 Р. Хаггарти
Дискретная математика для программистов Москва: Техносфера, 2003. – 320 с.
2 Гончарова Г.А., Мочалин А.А. Элементы
дискретной математики: Учебное пособие. – М.: ФОРУМ: ИНФРА‑М, 2004. -128 с.
3 Романовский И.В. Дискретный
анализ. Учебное пособие для студентов, специализирующихся по прикладной
математике и информатике. Издание 2‑е, исправленное, – СПб.: Невский диалект,
2000 г. -240 с., ил.
4 Д. Кнут Искусство
программирования для ЭВМ, т. 2, М.: Мир, 2000.
5 Новиков Ф.А. Дискретная
математика для программистов. – СПб.: Питер, 2001. – 304 с.: ил.
6 Ламуатье Ж.‑П. Упражнения
по программированию на Фортране IV, М.-Мир, 1978. – 168 с.: ил.
7 Светозарова Г.И. и
др. Практикум по программированию на языке Бейсик: Учеб. пособие для вузов. – М.:
Наука. Гл. ред. физ.-мат. лит., 1988. – 368 с.
8 Зеленяк О.П. Практикум
по программированию на Turbo Pascal. Задачи, алгоритмы и решения – К.: Издательство
«ДиаСофт», 2001. – 320 с.
9 Абрамов С.А., Гнездилова Г.Г.
и др., Задачи по программированию, М., Наука. Гл. ред. физ.-мат. лит., 1988.
224 с.
10
Абрамов С.А.,
Зима Е.В. Начала информатики. – М., Наука. Гл. ред. физ.-мат.
лит., 1989. – 224 с.
11
Юркин А.Г. Задачник
по программированию. – СПб.: Питер, 2002. – 192 с.
12
Хаггарти
Дискретная математика для программистов Москва: Техносфера, 2006. 350 с.
13
Шапорев С.Д. Математическая
логика. Курс лекций и практических занятий – СПб.: БХВ-Петербург, 2005. – 415 с. 6
ил.
14
Вирт
А. Алгоритмы и структуры данных: Пер. с англ., М.: Мир, 1989 – 360 с., ил.
15
Шестаков А.А.,
Дружинина О.В. Дискретная математика. Часть I, II. М. РГОТУПС, 1998. Часть
III М. РГОТУПС, 1999.
16
Могилёв А.В.
и др. Информатика: Учеб. Пособие для студентов пед. вузов под ред. Хённера Е.К.
М., 1999. – 816 с.
17
Коршунов Ю.М. Математические
основы кибернетики: Учебное пособие для вузов – М., Энергоатомиздат, 1987.
496 с.: ил.
18
Евстигнеев В.А. Применение
теории графов в программировании, М.,: Наука, 1985.
19
Оре
О. Теория графов. – М.: Наука, 1980.
20
Справочник
по математике для экономистов под общ. ред. Ермакова – М.: Финансы и
статистика, 1988
21
Судоплатов С.В.,
Овчинникова Е.В. Элементы дискретной математики: Учебник. – М.: ИНФРА
М; Новосибирск: НГТУ, 2003. – 280 с. – (Серия «Высшее образование»)
22
Емельянов В.И.,
Воробьёв В.И., Тюрина Т.П., Основы программирования на Delphi:
Учебное пособие для вузов; Под ред. В.М. Чёрненького. – М.: Высш. шк.,
2005.-231 с.: ил.
23
Тюрина Т.П.,
Емельянов В.И. Дискретная математика (часть 1). Учебное пособие, НИ
РХТУ им. Д.И. Менделеева, Новомосковск, 2004, 94 с.
24
Тюрина Т.П.,
Емельянов В.И. Дискретная математика (часть 2). Учебное пособие, НИ
РХТУ им. Д.И. Менделеева, Новомосковск, 2004, 34 с.
25
Тюрина Т.П.,
Емельянов В.И. Дискретная математика (часть 3). Учебное пособие, НИ
РХТУ им. Д.И. Менделеева, Новомосковск, 2005, 60 с.
|



