Информатика программирование : Учебное пособие: Наследование и классы-коллекции
Учебное пособие: Наследование и классы-коллекции
Факультет "Информатика и системы управления"
Методические указания к лабораторной работе
по курсу
"Распределенные системы обработки информации"
Наследование
и классы-коллекции
Москва 2004
г.
Оглавление
Цель работы.. 3
Задание для домашней подготовки. 3
Задания к лабораторной работе. 3
Задание 1 3
Задание 2 4
Содержание отчета. 4
Контрольные вопросы. 4
Литература. 6
Приложение 1. Спецификация класса Statistics. 7
Приложение 2. Работа со строками. 9
Приложение 3. Классы – коллекции. 20
Приложение 4. Работа с датами и временем. 41
Приложение 5. Файловый ввод/вывод. 43
Приложение 6. Обработка исключений. 48
Цель
работы
1. Научиться работать с коллекциями и
классами, реализующими интерфейс Collection.
2. Познакомиться с основными классами
пакета java.util.
3. Освоить работу с системным временем
(Класс java.util.Date).
4. Научиться работать с файлами и
потоками ввода/вывода.
5. Научиться обрабатывать строки
(объекты класса String).
6. Применить полученные знания на
практике
Задание
для домашней подготовки
1. Ознакомиться с материалом,
предоставленным в приложениях к данным методическим указаниям.
2. Изучить примеры программ, реализующих
файловый ввод/вывод (см. Приложение 5).
3. Ознакомиться с текстом задания к
лабораторной работе в соответствии с вариантом и написать программу.
Задания
к лабораторной работе
Задание 1
2 варианта:
1) Написать программу, которая считывает
текст из входного файла, подсчитывает, сколько раз встретился каждый символ
русского алфавита, и выводит результат в выходной файл, например, в виде строк
символ - число”.
2) Написать программу, которая считывает
текст из входного файла, формирует множество слов и выводит результат в
выходной файл. Одинаковые слова, встретившиеся в тексте, нужно вывести в третий
файл в виде строк “слово - число”.
Для обоих вариантов:
o Классы – коллекции, с помощью которых
будет выполнена обработка текста, студент выбирает самостоятельно.
Задание
2
Строки и файлы [Л.2 на
с.107-109]. Номер задания соответствует порядковому номеру в журнале (по модулю
20).
Содержание отчета
Отчет должен содержать:
1. Постановку задачи, решаемой
отлаженной программой.
2. Руководство пользователя отлаженной
программы, содержащее описание интерфейсов всех функций программы.
3. Листинг программы с необходимыми
комментариями.
Контрольные
вопросы
1. Как изменить кодировку символов (“KOI8_R”, “Cp866”,
) в потоках ввода/вывода?
2. Как сделать программу
нечувствительной к регистру символов входного файла?
3. Как изменить программу, чтобы имена
входных/выходных файлов нужно было бы вводить с клавиатуры или задавать в
командной строке.
4. Как нужно изменить программу, чтобы
после объявления метода public static void main(String[]
args) не нужно было бы записывать throws IOException.
5. Как известно, время в приложения Java записывается в виде целочисленных
значений типа long, выраженных в миллисекундах и
отсчитываемых с полуночи (00:00:00 GMT) 1 января 1970 года. На сколько лет хватит размера (8байт) значения типа
long для отсчета миллисекунд?
6. Как можно изменить программу, чтобы
подсчитать время обработки файлов без использования класса Date, введя одну дополнительную
переменную.
7. Как сравнить две строки.
8. Как выбрать i-ый символ строки.
Литература
1.
Арнолд
К., Гослинг Дж., Холмс Д. Язык программирования Java:Пер. с англ. – М.:
Издательский дом «Вильямс», 2001 г. – 624 с., ил.
2.
Павловская
Т.А., Щупак Ю.А. С/С++. Структурное программирование: Практикум. -СПб.: Питер,
2002. -240с.
Дополнительная
1.
Официальный
сайт Java — http://java.sun.com/ (есть раздел на русском языке с учебником).
2.
Java™ 2 SDK, Standard Edition Documentation — http://java.sun.com/products/jdk/1.5/index.html.
3.
Джеймс Гослинг, Билл Джой, Гай Стил. Спецификация языка Java (The Java
Language Specification — http://www.javasoft.com/docs/books/jls/). Перевод на русский язык
http://www.uni-vologda.ac.ru/java/jls/index.html
4.
Официальный
сайт проекта Eclipse — http://www.eclipse.org/.
А также
5.
Дмитрий
Рамодин. Начинаем программировать на языке Java.
6.
Николай
Смирнов. Java 2: Учебное пособие.
7.
Картузов
А. В. Программирование на языке Java.
8.
Вязовик
Н.А. Программирование на Java.
Приложение
1. Спецификация класса Statistics.
import java.io.*;//подключение
пакета с классами ввода/вывода
import java.util.*; //подключение
пакета с классами коллекций и времени
public class
Statistics {
public static
void main(String[] args) throws IOException{
BufferedReader
br = new BufferedReader(new InputStreamReader(new FileInputStream("d:\\input.txt"));
//Входной поток — из
файла d:\input.txt
BufferedWriter
bw = new BufferedWriter(new OutputStreamWriter(new
FileOutputStream("d:\\output.txt"));
//Выходной поток — в файл
d:\output.txt
//инициализация
экземпляра класса, реализующего интерфейс коллекций
int c = 0;
Date before = new Date(); //зафиксировали
время перед обработкой
while ((c = br.read()) != -1) { //пока не достигнут
конец файла d:\input.txt
//обработка
/*
например, если ранее
определена строка String s="";
то можно записать s+=(char)c;
Тогда все содержимое
файла d:\input.txt
будет записано в строку s
*/
}
br.close(); //закрываем входной поток после чтения и
предварительной обработки
for (/*цикл*/){
//обработка и запись в
выходной поток
bw.write(/*слово*/+" "+/*число*/+"\r\n");
}
bw.close(); //закрываем выходной поток после записи файла
Date after = new Date(); //фиксируем
время после обработки
System.out.println("Обработка
продолжалась "+(after.getTime()-before.getTime())+"
миллисекунд");
//выводим на консоль время
обработки в миллисекундах
} //конец public static void main(String[]
args)
} //конец класса Statistics
Приложение
2. Работа со строками
Очень большое место в
обработке информации занимает работа с текстами. Как и многое другое, текстовые
строки в языке Java являются объектами. Они представляются экземплярами класса String или класса StringBuffer.
Зачем в язык введены два
класса для хранения строк? В объектах класса String хранятся строки-константы неизменной длины и содержания. Это значительно
ускоряет обработку строк и позволяет экономить память, разделяя строку между
объектами, использующими ее. Длину строк, хранящихся в объектах класса StringBuffer, можно менять, вставляя и добавляя
строки и символы, удаляя подстроки или сцепляя несколько строк в одну строку.
Напомним, что символы в
строках хранятся в кодировке Unicode, в которой каждый символ занимает два
байта. Тип каждого символа char.
Класс
String
Перед работой со строкой
ее следует создать. Это можно сделать разными способами.
Самый
простой способ создать строку — это организовать ссылку типа String на строку-константу:
String si = "Это
строка.";
Если константа длинная,
можно записать ее в нескольких строках текстового редактора, связывая их
операцией сцепления:
String s2 = "Это
длинная строка, " +
"записанная в двух
строках исходного текста";
Не забывайте разницу
между пустой строкой String
s = "", не
содержащей ни одного символа, и пустой ссылкой String s = null, не указывающей ни на какую строку и не являющейся объектом.
Самый правильный способ
создать объект с точки зрения ООП — это вызвать его конструктор в операции new.
Класс String предоставляет девять конструкторов:
·
String() — создается объект с пустой строкой;
·
String(String
str) — из одного объекта
создается другой, поэтому этот конструктор используется редко;
·
String(StringBuffer
str) — преобразованная
копия объекта класса StringBuffer;
·
String(byte[]
byteArray) — объект
создается из массива байтов byteArray;
·
String(char []
charArray) — объект
создается из массива charArray символов Unicode;
·
String(byte []
byteArray, int offset, int count) — объект создается из части массива байтов byteArray, начинающейся с индекса offset и содержащей count
байтов;
·
String(char []
charArray, int offset, int count) — то же, но массив состоит из символов Unicode;
·
String(byte[]
byteArray, String encoding) — символы, записанные в массиве байтов, задаются в Unicode-строке, с
учетом кодировки encoding;
·
String(byte[]
byteArray, int offset, int count, String encoding) — то же самое, но только для части
массива.
При неправильном задании
индексов offset, count
или кодировки encoding возникает исключительная ситуация.
У кириллицы есть, по
меньшей мере, четыре кодировки:
·
В MS-DOS
применяется кодировка СР866.
·
В UNIX обычно
применяется кодировка KOI8-R.
·
На компьютерах
Apple Macintosh используется кодировка MacCyrillic.
·
Есть еще и
международная кодировка кириллицы ISO8859-5;
Если исходный кириллический
ASCII-текст был в одной из этих кодировок, а местная кодировка СР1251, то
Unicode-символы строки Java не будут соответствовать кириллице.
В этих случаях
используются последние два конструктора, в которых параметром encoding указывается, какую кодовую таблицу
использовать конструктору при создании строки.
Еще один способ создать
строку — это использовать два статических метода
copyValueOf(char[]
charArray) и copyValueOf(char[]
charArray, int offset, int length).
Они создают строку по
заданному массиву символов и возвращают ее в качестве результата своей работы.
Например, после выполнения следующего фрагмента программы
char[] с = ('С', 'и',
'м', 'в', 'о1, 'л', 'ь', 'н', 'ы', 'й'};
String s1 =
String.copyValueOf(с);
String s2 =
String.copyValueOf(с, 3, 7);
получим в объекте s1 строку "Символьный", а в объекте s2 — строку "вольный".
Сцепление
строк
Со строками можно
производить операцию сцепления строк, обозначаемую знаком плюс +. Эта операция
создает новую строку, просто составленную из состыкованных первой и второй
строк. Ее можно применять и к константам, и к переменным. Например:
String
attention = "Внимание: ";
String s =
attention + "неизвестный символ";
Вторая операция
присваивание += — применяется к переменным в левой части:
attention += s;
Поскольку операция + перегружена со сложения чисел на сцепление строк, встает
вопрос о приоритете этих операций. У сцепления строк приоритет выше, чем у
сложения, поэтому, записав "2" + 2 + 2, получим строку
"222". Но, записав 2 + 2 + "2", получим строку "42",
поскольку действия выполняются слева направо. Если же запишем "2" + (2 + 2), то получим "24".
Манипуляции
строками
В классе String есть множество методов для работы со строками.
Как узнать длину строки
Для того чтобы узнать
длину строки, т. е. количество символов в ней, надо обратиться к методу length():
String s =
"Write once, run anywhere.";
int len = s.length{);
или еще проще
int len =
"Write once, run anywhere.".length();
поскольку
строка-константа — полноценный объект класса String.
Заметьте, что строка — это не массив, у нее нет поля length.
Как выбрать символы из строки
Выбрать символ с индексом
ind (индекс первого символа равен нулю)
можно методом charAt(int
ind) Если индекс ind отрицателен или не меньше чем длина строки, возникает
исключительная ситуация.
Все символы строки в виде
массива символов можно получить методом toCharArray(), возвращающим массив символов.
Если же надо включить в
массив символов dst, начиная с индекса ind массива подстроку от индекса begin включительно до индекса end исключительно, то используйте метод getChars(int begin, int end, char[]
dst, int ind) типа void.
В массив будет записано end - begin символов, которые займут элементы
массива, начиная с индекса ind до индекса ind + (end - begin) - 1.
Если надо получить массив
байтов, содержащий все символы строки в байтовой кодировке ASCII, то
используйте метод getBytes().
Этот метод при переводе
символов из Unicode в ASCII использует локальную кодовую таблицу.
Если же надо получить
массив байтов не в локальной кодировке, а в какой-то другой, используйте метод getBytes(String encoding).
Как выбрать подстроку
Метод substring(int begin, int end) выделяет подстроку от символа с
индексом begin включительно до символа с индексом end исключительно. Длина подстроки будет равна end - begin.
Метод substring (int begin) выделяет подстроку от индекса begin включительно до конца строки.
Если индексы
отрицательны, индекс end больше длины строки или begin больше чем end,
то возникает исключительная ситуация.
Например, после выполнения
String s =
"Write onсe, run anywhere.";
String sub1 =
s.substring(6, 10);
String sub2 =
s.substring(16);
получим в строке sub1 значение "once", а в sub2 — значение "anywhere".
Как сравнить строки
Операция сравнения == сопоставляет только ссылки на строки. Она выясняет,
указывают ли ссылки на одну и ту же строку. Например, для строк
String s1 =
"Какая-то строка";
String s2 =
"Другая-строка";
сравнение s1 == s2 дает в результате false.
Значение true получится, только если обе ссылки указывают на одну и
ту же строку, например, после присваивания si = s2.
Интересно, что если мы
определим s2 так:
String s2 ==
"Какая-то строка";
то сравнение s1 == s2 даст в результате true, потому что компилятор создаст только один экземпляр
константы "Какая-то строка" и направит на него все ссылки.
Для сравнения содержимого
строк есть несколько методов.
Логический метод equals (Object obj), переопределенный из класса Оbject, возвращает true,
если аргумент obj не равен null, является объектом класса String,
и строка, содержащаяся в нем, полностью идентична данной строке вплоть до
совпадения регистра букв. В остальных случаях возвращается значение false.
Логический метод equalsIgnoreCase(Object obj) работает так же, но одинаковые буквы,
записанные в разных регистрах, считаются совпадающими.
Метод compareTo(string str) возвращает целое число типа int, вычисленное по следующим правилам:
1. Сравниваются символы данной строки this и строки str с
одинаковым индексом, пока не встретятся различные символы с индексом, допустим k, или пока одна из строк не закончится.
2. В первом случае возвращается значение
this.charAt(k) -
str.charAt(k), т. е.
разность кодировок Unicode первых несовпадающих символов.
3. Во втором случае возвращается значение
this.length() -
str.length(), т. е.
разность длин строк.
4. Если строки совпадают, возвращается
0.
Если значение str равно null,
возникает исключительная ситуация.
Нуль возвращается в той
же ситуации, в которой метод equals()
возвращает true.
Метод compareToignoreCase(string str) производит сравнение без учета
регистра букв, точнее говоря, выполняется метод
this.toUpperCase().toLowerCase().compareTo(
str.toUpperCase().toLowerCase());
Еще один метод— compareTo (Object obj) создает исключительную ситуацию,
если obj не является строкой. В остальном он
работает как метод compareTo(String
str).
Эти методы не учитывают
алфавитное расположение символов в локальной кодировке.
Русские буквы расположены
в Unicode по алфавиту, за исключением одной буквы. Заглавная буква Ё
расположена перед всеми кириллическими буквами, ее код '\u040l', а строчная буква е — после всех русских букв, ее
код '\u0451'.
Кодировки
русских букв:
‘А’ ~ 1040 ~ \u410
‘Я’~ 1071 ~ \u42F
‘а’ ~ 1072 ~ \u430
‘я’ ~ 1103 ~ \u44F
Как найти символ в строке
Поиск всегда ведется с
учетом регистра букв.
Первое появление символа ch в данной строке this
можно отследить методом indexOf(int
ch), возвращающим индекс
этого символа в строке или -1, если символа ch в строке this нет.
Например, "Молоко", indexOf('о') выдаст в результате 1.
Второе и следующие
появления символа ch в данной строке this можно отследить методом indexOf(int ch, int ind).
Этот метод начинает поиск
символа ch с индекса ind. Если ind <
0, то поиск идет с начала строки, если ind
больше длины строки, то символ не ищется, т. е. возвращается -1.
Последнее появление
символа ch в данной строке this отслеживает метод lastIndexof (int ch). Он просматривает строку в обратном
порядке. Если символ ch не найден,
возвращается.-1.
Предпоследнее и
предыдущие появления символа ch в данной строке
this можно отследить методом lastIndexof(int ch, int ind), который просматривает строку в
обратном порядке, начиная с индекса ind.
Если ind больше длины строки, то поиск идёт от конца строки,
если ind < 0, то возвращается -1.
Как найти подстроку
Поиск всегда ведется с
учетом регистра букв.
Первое вхождение
подстроки sub в данную строку this отыскивает метод indexof
(String sub). Он возвращает индекс первого символа
первого вхождения подстроки sub в строку или
-1, если подстрока sub не входит в строку this.
Если вы хотите начать
поиск не с начала строки, а с какого-то индекса ind, используйте метод indexOf (String sub, int ind). если ind
< 0, то поиск идет с
начала строки, если ind больше .длины строки, то символ не
ищется, т. е. возвращается -1.
Последнее вхождение
подстроки sub в данную строку this можно отыскать методом lastindexof (string sub),
возвращающим индекс первого символа последнего вхождения подстроки sub в строку this
или (-1), если подстрока sub не входит в строку this.
Последнее вхождение
подстроки sub не во всю строку this, а только в ее начало до индекса ind можно отыскать методом lastIndexof(String stf, int ind). Если ind
больше длины строки, то поиск идет от конца строки, если ind < 0, то возвращается -1.
Перечисленные выше методы
создают исключительную ситуацию, если
sub == null.
Если вы хотите
осуществить поиск, не учитывающий регистр букв, измените предварительно регистр
всех символов строки.
Как изменить регистр символов
Метод toLowerCase ()
возвращает новую строку, в которой все буквы переведены в нижний регистр, т. е.
сделаны строчными.
Метод toUpperCase () возвращает новую строку, в которой
все буквы переведены в верхний регистр, т. е. сделаны прописными.
При этом используется
локальная кодовая таблица по умолчанию. Если нужна другая локаль, то
применяются методы toLowerCase(Locale loc) и toUpperCase(Locale loc).
Как заменить отдельный символ
Метод replace (int old, int new) возвращает новую строку, в которой
все вхождения символа old заменены символом new. Если символа old в
строке нет, то возвращается ссылка на исходную строку.
Например, после
выполнения "Рука в
руку сует хлеб", replace ('у', 'е') получим строку "Река в реке сеет хлеб".
Регистр букв при замене
учитывается.
Как убрать пробелы в начале и конце
строки
Метод trim() возвращает новую строку, в которой удалены
начальные и конечные символы с кодами, не превышающими '\u0020'.
Как преобразовать данные другого
типа в строку
В языке Java принято
соглашение — каждый класс отвечает за преобразование других типов в тип этого
класса и должен содержать нужные для этого методы.
Класс String содержит восемь статических методов valueof (type elem) преобразования в строку примитивных
типов boolean, char,
int, long, float, double,
массива char[], и просто объекта типа Object.
Девятый метод valueof(char[] ch, int offset, int
len) преобразует в
строку подмассив массива ch, начинающийся с индекса offset и имеющий len
элементов.
Кроме того, в каждом
классе есть метод toString
(), переопределенный или
просто унаследованный от класса Object.
Он преобразует объекты класса в строку. Фактически, метод valueOf() вызывает метод toString() соответствующего класса. Поэтому
результат преобразования зависит от того, как реализован метод toString().
Еще один простой способ
сцепить значение elem какого-либо типа с пустой строкой: "" + elem. При этом неявно вызывается метод elem.toString ().
Синтаксический
разбор строки
Задача разбора введенного
текста — вечная задача программирования, наряду с сортировкой и поиском.
В пакет java.util входит простой класс StringTokenizer, облегчающий разбор строк.
Класс StringTokenizer
Класс StringTokenizer из пакета java.util небольшой, в нем три конструктора и шесть методов.
Первый конструктор StringTokenizer (String str) создает объект, готовый разбить
строку str на слова, разделенные пробелами,
символами табуляций '\t', перевода строки '\n' и возврата каретки '\r'. Разделители не включаются в число слов.
Второй конструктор StringTokenizer (String str, String delimeters) задает разделители вторым параметром delimeters,
например:
StringTokenizer("Казнить,нельзя:пробелов-нет",
" \t\n\r,:-");
Здесь первый разделитель
пробел. Потом идут символ табуляции, символ перевода строки, символ возврата
каретки, запятая, двоеточие, дефис. Порядок расположения разделителей в строке delimeters
не имеет значения. Разделители не включаются в число слов.
Третий конструктор
позволяет включить разделители в число слов:
StringTokenizer(String
str, String delimeters, boolean flag);
В разборе строки на слова
активно участвуют следующие методы:
o метод nextToken() возвращает в виде строки следующее слово.
o метод hasMoreTokens() возвращает true, если в
строке еще есть слова, и false, если слов больше нет.
o метод countTokens() возвращает число оставшихся слов.
o метод nextToken(string newDelimeters) позволяет "на ходу" менять разделители. Следующее слово будет
выделено по новым разделителям newDelimeters; новые разделители действуют далее
вместо старых разделителей, определенных в конструкторе или предыдущем методе nextToken().
o методы nextElement() и hasMoreElements()
реализуют интерфейс Enumeration. Они
просто обращаются к методам nextToken() и hasMoreTokens().
Пример. Разбиение строки
на слова :
String s = "Строка,
которую мы хотим разобрать на слова";
StringTokenizer
st = new StringTokenizer(s, " \t\n\r,.");
while(st.hasMoreTokens()){
// Получаем слово и
что-нибудь делаем с ним, например,
// просто выводим на
экран
System.out.println(st.nextToken())
;
}
Полученные слова обычно
заносятся в какой-нибудь класс-коллекцию: Vector, Stack или другой, наиболее подходящий для дальнейшей обработки текста
контейнер. Классы-коллекции мы рассмотрены далее.
Приложение 3. Классы – коллекции
При решении
задач, в которых количество элементов заранее неизвестно, элементы надо часто
удалять и добавлять используются коллекции.
В языке Java
с самых первых версий есть класс Vector, предназначенный для хранения
переменного числа элементов самого общего типа Object.
Класс Vector
В классе Vector из пакета java.util
хранятся элементы типа Object, а значит, любого типа. Количество
элементов может быть любым и наперед не определяться. Элементы получают индексы
0, 1, 2, .... К каждому элементу вектора можно обратиться по индексу, как и к
элементу массива.
Кроме
количества элементов, называемого размером (size) вектора, есть еще размер
буфера — емкость (capacity) вектора. Обычно емкость совпадает с размером вектора,
но можно ее увеличить методом ensureCapacity(int
minCapacity) или
сравнять с размером вектора методом trimToSize().
Как
создать вектор
В классе
четыре конструктора:
Vector () — создает пустой объект нулевой
длины;
Vector (int
capacity) — создает пустой
объект указанной емкости capacity;
Vector (int
capacity, int increment)
создает пустой объект указанной емкости capacity и задает число increment, на которое увеличивается емкость
при необходимости;
vector
(Collection с) — вектор
создается по указанной коллекции. Если capacity отрицательно, создается исключительная ситуация. После создания вектора
его можно заполнять элементами.
Как
добавить элемент в вектор
Метод add (Object element) позволяет добавить элемент в конец
вектора.
Методом add (int index, Object element) можно вставить элемент в указанное место index. Элемент, находившийся на этом месте, и все
последующие элементы сдвигаются, их индексы увеличиваются на единицу.
Метод addAll (Collection coll) позволяет добавить в конец вектора все элементы коллекции coll.
Методом addAll(int index, Collection coll) возможно вставить в позицию index все элементы коллекции coll.
Как
заменить элемент
Метод set (int index, Object element) заменяет элемент, стоявший в векторе
в позиции index, на элемент element.
Как узнать
размер вектора
Количество
элементов в векторе всегда можно узнать методом size(). Метод capacity()возвращает емкость вектора.
Логический
метод isEmpty() возвращает true, если в векторе нет ни одного элемента.
Как
обратиться к элементу вектора
Обратиться к
первому элементу вектора можно методом firstElement(), к последнему — методом lastElement(),
к любому элементу — методом get(int index).
Эти методы
возвращают объект класса Object. Перед использованием его следует
привести к нужному типу.
Получить все
элементы вектора в виде массива типа Object[] можно методами toArray) и toArray (Object [] а). Второй метод заносит все элементы вектора в массив
а, если в нем достаточно места.
Как
узнать, есть ли элемент в векторе
Логический
метод contains (Object
element) возвращает true, если элемент element
находится в векторе.
Логический
метод containsAll (Collection с) возвращает true, если вектор содержит все элементы указанной
коллекции.
Как узнать
индекс элемента
Четыре метода
позволяют отыскать позицию указанного элемента element:
indexOf (Object element) — возвращает индекс первого
появления элемента в векторе;
indexOf
(Object element, int begin) — ведет поиск, начиная с индекса begin
включительно;
lastindexOf
(Object element) — возвращает
индекс последнего появления элемента в векторе;
lastindexOf
(Object element, int start) — ведет поиск от индекса start
включительно к началу вектора.
Если элемент
не найден, возвращается —1.
Как
удалить элементы
Логический
метод remove (Object
element) удаляет из
вектора первое вхождение указанного элемента element. Метод возвращает true,
если элемент найден и удаление произведено.
Метод remove (int index) удаляет элемент из позиции index и возвращает его в качестве своего результата типа Object.
Удалить
диапазон элементов можно методом removeRange(int begin, int end), не возвращающим результата. Удаляются элементы от
позиции begin включительно до позиции end исключительно.
Удалить из
данного вектора все элементы коллекции coll возможно
логическим Методом removeAll(Collection
coll).
Удалить
последние элементы можно, просто урезав вектор методом
setSizefint
newSize).
Удалить все
элементы, кроме входящих в указанную коллекцию coll, разрешает логический метод retainAll(Collection coll).
Удалить все
элементы вектора можно методом clear()или обнулив
размер вектора методом setSize(O).
Данный
листинг дополняет пример, записанный в приложении 2, обрабатывая выделенные из
строки слова с помощью вектора.
Работа с вектором
Vector v =
new Vector();
String s =
"Строка, которую мы хотим разобрать на слова.";
StringTokenizer
st = new StringTokenizer(s, " \t\n\r,.");
while
(st.hasMoreTokens()){
// Получаем
слово и заносим в вектор
v.add(st.nextToken());
// Добавляем в конец вектора
}
System.out.println(v.firstElement());
// Первый элемент
System.out.println(v.lastElement());
// Последний элемент
v.setSize(4);
// Уменьшаем число элементов
v.add("собрать.");
// Добавляем в конец
//
укороченного вектора
v.set(3, "опять");
// Ставим в позицию 3
for
(int i = 0; i < v.sizeO; i++) // Перебираем весь вектор
System.out.print(v.get(i)
+ " ");
System.out.println();
Класс Vector является примером того, как можно объекты класса Object, a значит, любые объекты, объединить в коллекцию.
Этот тип коллекции упорядочивает и даже нумерует элементы. В векторе есть
первый элемент, есть последний элемент. К каждому элементу обращаются
непосредственно по индексу. При добавлении и удалении элементов оставшиеся
элементы автоматически перенумеровываются.
Второй пример
коллекции — класс Stack — расширяет кладе Vector.
Класс Stack
Класс Stack из пакета java.util. объединяет элементы в стек.
Стек (Stack)
реализует порядок работы с элементами подобно магазину винтовки— первым
выстрелит патрон, положенный в магазин последним,— или подобно железнодорожному
тупику — первым из тупика выйдет вагон, загнанный туда последним. Такой порядок
обработки называется LIFO (Last In — First Out).
Перед работой
создается пустой стек конструктором Stack ().
Затем на стек
кладутся и снимаются элементы, причем доступен только "верхний"
элемент, тот, что положен на стек последним.
Дополнительно
к методам класса vector класс Stack содержит пять методов, позволяющих работать с коллекцией как со стеком:
push (Object
item) —помещает элемент item в стек;
pop () — извлекает верхний элемент из
стека;
peek () — читает верхний элемент, не извлекая
его из стека;
empty () — проверяет, не пуст ли стек;
search
(Object item) — находит
позицию элемента item в стеке. Верхний элемент имеет
позицию 1, под ним элемент 2 и т. д. Если элемент не найден, возвращается — 1.
Еще один
пример коллекции совсем другого рода — таблицы — предоставляет класс Hashtable.
Класс Hashtable
Класс Hashtable расширяет абстрактный класс Dictionary. В объектах этого класса хранятся
пары "ключ — значение".
Из таких пар
"Фамилия И. О. — номер" состоит, например, телефонный справочник.
Каждый объект
класса Hashtable кроме размера (size) — количества
пар, имеет еще две характеристики: емкость (capacity) — размер буфера, и показатель
загруженности (load factor) — процент заполненности буфера, по достижении
которого увеличивается его размер.
Как
создать таблицу
Для создания
объектов класс Hashtable предоставляет четыре конструктора:
Hashtable() — создает пустой объект с начальной
емкостью в 101 элемент и показателем загруженности 0,75;
Hashtable
(int capacity) — создает
пустой объект с начальной емкостью capacity и показателем загруженности 0,75;
Hashtable(int
capacity, float loadFactor) — создает пустой Объект с начальной емкостью capacity и показателем загруженности loadFactor;
Hashtable
(Map f) — создает объект
класса Hashtable, содержащий все элементы отображения
f, с емкостью, равной удвоенному числу
элементов отображения f, но не менее 11, и показателем
загруженности 0,75.
Как
заполнить таблицу
Для
заполнения объекта класса Hashtable
используются два метода:
Object
put(Object key, Object value) — добавляет пару "key — value",
если ключа key не было в таблице, и меняет значение
value ключа key, если он уже есть в таблице. Возвращает старое значение ключа или null, если его не было. Если хотя бы один параметр равен null, возникает исключительная ситуация;
void
putAll(Map f)
добавляет все элементы отображения f. В
объектах-ключах key должны быть реализованы методы hashCode() и equals ().
Как
получить значение по ключу
Метод get (Object key) возвращает значение элемента с
ключом key в виде объекта класса Object. Для дальнейшей работы его следует преобразовать к
конкретному типу.
Как узнать
наличие ключа или значения
Логический
метод containsKey(Object
key) возвращает true, если в таблице есть ключ key.
Логический
метод containsvalue
(Object value) или
старый метод contains
(Object value)
возвращают true, если в таблице есть ключи со
значением value.
Логический
метод isEmpty() возвращает true, если в таблице нет элементов.
Как получить все элементы таблицы
Метод values()представляет все значения value таблицы в виде интерфейса Collection. Все модификации в объекте collection изменяют таблицу, и наоборот.
Метод keyset() предоставляет все ключи key таблицы в виде интерфейса set. Все изменения в объекте set корректируют таблицу, и наоборот.
Метод entrySet() представляет все пары "key — value" таблицы в виде интерфейса Set. Все модификации в объекте Set
изменяют таблицу, и наоборот.
Метод toString()
возвращает строку, содержащую все пары.
Как удалить элементы
Метод remove (Object key) удаляет пару с ключом key, возвращая значение этого ключа, если оно есть, и null, если пара с ключом key не найдена.
Метод clear() удаляет все элементы, очищая таблицу.
Пример
программы «Телефонный справочник».
import java.util.*;
class
PhoneBook{
public
static void main(String[] args){
Hashtable
yp = new Hashtable();
String
name = null;
yp.put("John",
"123-45-67");
yp.put
("Lemon", "567-34-12");
yp.put("Bill",
"342-65-87");
yp.put("Gates",
"423-83-49");
yp.put("Batman",
"532-25-08");
try{
name
= args[0];
}
catch(Exception
e){
System.out.println("Usage:
Java PhoneBook Name");
}
return;
}
if
(yp.containsKey(name))
System.out.println(name
+ "'s phone = " + yp.get(name));
else
System.out.println("Sorry,
no such name");
)
}
Класс Properties
Класс Properties расширяет класс Hashtable. Он предназначен в основном для ввода и вывода пар свойств
системы и их значений. Пары хранятся в виде строк типа String. В классе Properties два конструктора:
Properties() — создает пустой объект;
Properties
(Properties default) — создает
объект с заданными парами свойств default.
Кроме унаследованных
от класса Hashtable методов в классе Properties есть еще следующие методы.
Два метода,
возвращающих значение ключа-строки в виде строки:
• String getProperty (String
key) — возвращает значение по ключу key;
• String
getProperty(String.key, String defaultValue) — возвращает значение по ключу key; если такого
ключа нет, возвращается defaultValue.
Метод setProperty(String key, String value) добавляет новую пару, если ключа key нет, и меняет значение, если ключ key есть.
Метод load(Inputstream in) загружает свойства из входного
потока in.
Методы
list(PrintStream out) И list (PrintWriter out) выводят свойства в выходной
поток out.
Метод store (OutputStream out, String
header) выводит свойства
в выходной поток out с заголовком header.
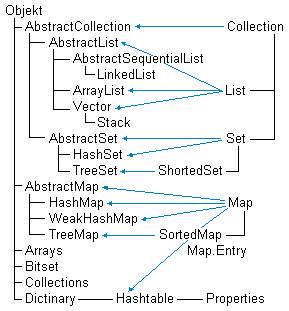
Рисунок. Иерархия классов и
интерфейсов-коллекций.
Примеры
классов Vector, Stack,
Hashtable, Properties
показывают удобство классов-коллекций. Поэтому в Java 2 разработана целая
иерархия коллекций. Она показана на рисунке. Справа записаны имена интерфейсов.
Стрелки указывают классы, реализующие эти интерфейсы. Все коллекции разбиты на
три группы, описанные в интерфейсах List, Set и Map.
Примером
реализации интерфейса List может служить класс Vector, примером реализации интерфейса мар — класс Hashtable.
Коллекции List и Set имеют много
общего, поэтому их общие методы объединены и вынесены в суперинтерфейс Collection.
Интерфейс
Collection
Интерфейс collection из пакета java.util описывает общие свойства коллекций List и Set. Он содержит
методы добавления и удаления элементов, проверки и преобразования элементов:
boolean add
(Object obj) — добавляет
элемент obj в конец коллекции; возвращает false, если такой элемент в коллекции уже есть, а коллекция
не допускает повторяющиеся элементы; возвращает true, если добавление прошло удачно;
boolean
addAll (Collection coll)
добавляет все элементы коллекции coll в
конец данной коллекции;
void clear() — удаляет все элементы коллекции;
boolean
contains (Object obj)
проверяет наличие элемента obj в коллекции;
boolean
containsAll (Collection coll) — проверяет наличие всех элементов коллекции coll в данной коллекции;
boolean
isEmpty() — проверяет,
пуста ли коллекция;
iterator iterator
() — возвращает итератор
данной коллекции;
boolean
remove (Object obj)
удаляет указанный элемент из коллекции; возвращает false, если элемент не найден, true, если удаление прошло успешно;
boolean
removeAll (Collection coll) — удаляет элементы указанной коллекции, лежащие в данной коллекции;
boolean
retainAll (Collection coll) — удаляет все элементы данной коллекции, кроме элементов коллекции coll;
int size () — возвращает количество элементов в
коллекции;
Object []
toArray() — возвращает
все элементы коллекции в виде массива;
Objectn
toArray(Object[] a)
записывает все элементы коллекции в массив а, если в нем достаточно места.
Интерфейс List
Интерфейс List из пакета java.util, расширяющий интерфейс Collection,
описывает методы работы с упорядоченными коллекциями. Иногда их называют последовательностями
(sequence). Элементы такой коллекции
пронумерованы, начиная от нуля, к ним можно обратиться по индексу. В отличие от
коллекции Set элементы коллекции List могут повторяться.
Класс Vector — одна из реализаций интерфейса List.
Интерфейс List добавляет к методам интерфейса Collection методы, использующие индекс index элемента:
void add(int
index, Object obj)
вставляет элемент obj в позицию index; старые элементы, начиная с позиции index, сдвигаются, их индексы увеличиваются на единицу;
boolean
addAll(int index, Collection coll) — вставляет все элементы коллекции coll;
Object
get(int index)
возвращает элемент, находящийся в позиции index;
int
indexOf(Object obj)
возвращает индекс первого появления элемента obj в коллекции;
int
lastindexOf (Object obj)
возвращает индекс последнего появления элемента obj в коллекции;
Listiterator
listiterator ()
возвращает итератор коллекции;
Listiterator
listiterator (int index)
возвращает итератор конца коллекции от позиции index;
Object Set
(int index, Object obj)
заменяет элемент, находящийся в позиции index,
элементом obj;
List
subListUnt from, int to)
возвращает часть коллекции от позиции from
включительно до позиции to исключительно.
Интерфейс Set
Интерфейс Set из пакета java.util, расширяющий интерфейс Collection,
описывает неупорядоченную коллекцию, не содержащую повторяющихся элементов. Это
соответствует математическому понятию множества (Set). Такие коллекции удобны для проверки наличия или отсутствия у элемента
свойства, определяющего множество. Новые методы в интерфейс Set не добавлены, просто метод add () не станет добавлять еще одну копию элемента, если
такой элемент уже есть в множестве.
Этот
интерфейс расширен интерфейсом SortedSet.
Интерфейс
SortedSet
Интерфейс SortedSet из пакета java.util, расширяющий интерфейс Set, описывает упорядоченное множество, отсортированное по
естественному порядку возрастания его элементов или по порядку, заданному
реализацией интерфейса Comparator.
Элементы не
нумеруются, но есть понятие первого, последнего, большего и меньшего элемента.
Дополнительные
методы интерфейса отражают эти понятия:
Comparator comparator () — возвращает способ упорядочения
коллекции; Object
first()— возвращает
первый, меньший элемент коллекции;
SortedSet
headSet (Object toElement) — возвращает начальные, меньшие элементы до элемента toElement исключительно;
Object last
() — возвращает
последний, больший элемент коллекции;
SortedSet
subSet(Object fromElement, Object toElement) — возвращает подмножество коллекции от элемента fromElement включительно до элемента toElement исключительно;
SortedSet
tailSet (Object fromElement) — возвращает последние, большие элементы коллекции от элемента fromElement включительно.
Интерфейс Map
Интерфейс Map из пакета java.util описывает коллекцию, состоящую из пар "ключ — значение". У
каждого ключа только одно значение, что соответствует математическому понятию
однозначной функции или отображения.
Такую
коллекцию часто называют еще словарем (dictionary) или ассоциативным массивом (associative
array).
Обычный
массив — простейший пример словаря с заранее заданным числом элементов. Это
отображение множества первых неотрицательных целых чисел на множество элементов
массива, множество пар "индекс массива – элемент массива".
Класс HashTable — одна из реализаций интерфейса мар.
Интерфейс Map содержит методы, работающие с ключами и значениями:
boolean
containsKey (Object key) — проверяет наличие ключа key;
boolean
containsValue (Object value) — проверяет наличие
значения value;
Set entrySet
() — представляет
коллекцию в виде множества, каждый элемент которого — пара из данного
отображения, с которой можно работать методами вложенного интерфейса Map.Entry;
Object get
(Object key)
возвращает значение, отвечающее ключу key;
Set keySet() — представляет ключи коллекции в
виде множества;
Object put(Object key, Object value) — добавляет пару "key— value", если такой пары не было, и
заменяет значение ключа key, если такой ключ уже есть в
коллекции;
void putAll
(Map m) — добавляет к
коллекции все пары из отображения m;
Collection
values() — представляет
все значения в виде коллекции.
В интерфейс Mар вложен интерфейс Map.Entry, содержащий методы работы с отдельной парой.
Интерфейс SortedMap
Интерфейс SortedMap, расширяющий интерфейс Map, описывает упорядоченную по ключам коллекцию мар.
Сортировка производится либо в естественном порядке возрастания ключей, либо, в
порядке, описываемом в интерфейсе Comparator.
Элементы не
нумеруются, но есть понятия большего и меньшего из двух элементов, первого,
самого маленького, и последнего, самого большого элемента коллекции. Эти
понятия описываются следующими методами:
Comparator comparator () — возвращает способ упорядочения
коллекции;
Object
firstKey() — возвращает
первый, меньший элемент коллекции;
SortedMap
headMap(Object toKey) — возвращает
начало коллекции до элемента с ключом toKey исключительно;
Object
lastKey() — возвращает
последний, больший ключ коллекции;
SprtedMap
subMap (Object fromKey, Object toKey) — возвращает часть коллекции от элемента с ключом
fromKey включительно до элемента с ключом toKey исключительно;
SortedMap
tallMap (Object fromKey)
возвращает остаток коллекции от элемента fromKey
включительно.
Вы можете
создать свои коллекции, реализовав рассмотренные интерфейсы. Это дело трудное,
поскольку в интерфейсах много методов. Чтобы облегчить эту задачу, в Java API
введены частичные реализации интерфейсов — абстрактные классы-коллекции.
Абстрактные
классы-коллекции
Эти классы
лежат в пакете
java.util,
Абстрактный
класс AbstractGollection реализует интерфейс Collection, но оставляет нереализованными
методы iterator (), size ().
Абстрактный
класс AbstractList реализует интерфейс List, но оставляет нереализованным метод get() и унаследованный метод size() Этот класс позволяет реализовать коллекцию спрямым доступом к
элементам, подобно массиву
Абстрактный
класс AbstractSequentialList реализует интерфейс List, но оставляет нереализованным метод listiterator(int index) и унаследованный метод size(). Данный класс позволяет реализовать коллекции с последовательным
доступом к элементам с помощью итератора Listiterator
Абстрактный
класс AbstractSet реализует интерфейс Set, но оставляет нереализованными методы, унаследованные
от AbstractCollection
Абстрактный
класс AbstractMap реализует интерфейс Map, но оставляет нереализованным метод entrySet (),
Наконец, в
составе Java API есть полностью реализованные классы-коллекции помимо уже
рассмотренных классов Vector, Stack, Hashtable и Properties, Это классы ArrayList, LinkedList, HashSet,
TreeSet, HashMap, TreeMap, WeakHashMap ,
Для работы с
этими классами разработаны интерфейсы Iterator,
Listiterator,
Comparator И классы
Arrays И Collections.
Перед тем как
рассмотреть использование данных классов, обсудим понятие итератора.
Интерфейс
Iterator
В 90-х годах
было решено заносить данные в определенную коллекцию, скрыв ее внутреннюю
структуру, а для работы с данными использовать методы этой коллекции.
В частности,
задачу обхода возложили на саму коллекцию. В Java API введен интерфейс Iterator, описывающий способ обхода всех
элементов коллекции. В каждой коллекции есть метод iterator(), возвращающий реализацию интерфейса Iterator для указанной коллекции. Получив эту реализацию, можно обходить
коллекцию в некотором порядке, определенном данным итератором, с помощью
методов, описанных в интерфейсе Iterator и реализованных в этом итераторе. Подобная техника использована в классе
StringTokenizer.
В интерфейсе Iterator описаны всего три метода:
o логический метод hasNext () возвращает true, если обход еще не завершен;
o метод next() делает текущим следующий элемент коллекции и возвращает его в виде
объекта класса Object;
o метод remove() удаляет текущий элемент коллекции.
Можно
представить себе дело так, что итератор — это указатель на элемент коллекции.
При создании итератора указатель устанавливается перед первым элементом, метод next() перемещает указатель на первый элемент и показывает
его. Следующее применение метода next()
перемещает указатель на второй элемент коллекции и показывает его. Последнее
применение метода next() выводит указатель за последний
элемент коллекции.
Метод remove(), пожалуй, излишен, он уже не
относится к задаче обхода коллекции, но позволяет при просмотре коллекции
удалять из нее ненужные элементы.
Пример. Использование итератора вектора
Vector v =
new Vector();
String s =
"Строка, которую мы хотим разобрать на слова.";
StringTokenizer
st = new StringTokenizer(s, " \t\n\r,.");
while
(st.hasMoreTokens()){
// Получаем
слово и заносим в вектор.
v.add(st.nextToken());
// Добавляем в конец вектора }
System.out.print*Ln(v.firstElement(});
// Первый элемент
System.out.println(v.lastElement());
// Последний элемент
v.SetSize(4);
// Уменьшаем число элементов
v.add("собрать.");
// Добавляем в конец укороченного вектора
v.Set(3,
"опять"); // Ставим в позицию 3
for
(int i = 0; i < v.sizeO; i++) // Перебираем весь вектор
System.out.print(v.get(i)
+ ".");
System.out.println(};
Iterator
it = v.Iterator (); // Получаем итератор вектора
try{
while(it.hasNext())
// Пока в векторе есть элементы,
System.out.println(it.next());
// выводим текущий элемент
}catch(Exception
e){}
Интерфейс Listlterator
Интерфейс ListIterator расширяет интерфейс Iterator, обеспечивая перемещение по
коллекции как в прямом, так и в обратном направлении. Он может быть реализован
только в тех коллекциях, в которых есть понятия следующего и предыдущего
элемента и где элементы пронумерованы.
В интерфейс ListIterator добавлены следующие методы:
void add
(Object element)
добавляет элемент element перед текущим элементом;
boolean
hasPrevious()
возвращает true, если в коллекции есть элементы,
стоящие перед текущим элементом;
int
nextindex() — возвращает
индекс текущего элемента; если текущим является последний элемент коллекции,
возвращает размер коллекции;
Object
previous() — возвращает
предыдущий элемент и делает его текущим;
int previous
index() — возвращает
индекс предыдущего элемента;
void Set
(Object element) — заменяет
текущий элемент элементом element;
выполняется
сразу после next() или previous().
Как видите,
итераторы могут изменять коллекцию, в которой они работают, добавляя, удаляя и
заменяя элементы. Чтобы это не приводило к конфликтам, предусмотрена
исключительная ситуация, возникающая при попытке использования итераторов
параллельно "родным" методам коллекции. Именно поэтому в следующем
примере действия с итератором заключены в блок try(){}— catch(){}.
Пример с
использованием итератора ListIterator.
Vector v =
new Vector();
String s =
"Строка, которую мы хотим разобрать на слова.";
StringTokenizer
st = new StringTokenizer(s, " \t\n\r,.");
while
(st.hasMoreTokens()){
// Получаем
слово и заносим в вектор
v.add(st.nextToken());
// Добавляем в конец вектора
}
ListIterator
lit = v.listlterator(); // Получаем итератор вектора
// Указатель
сейчас находится перед началом вектора
try{
while(lit.hasNext())
// Пока в векторе есть элементы
System.out.println(lit.next());
// Переходим к следующему
// элементу и
выводим его
// Теперь
указатель за концом вектора. Пройдем к началу
while
(lit.hasPrevious())System.out.println(lit.previous());
}
catch (Exception e) {}
Посмотрим
теперь, какие возможности предоставляют классы-коллекции Java2.
Классы,
создающие списки
Класс ArrayList полностью реализует интерфейс List и итератор типа Iterator. Класс ArrayList очень похож на класс Vector, имеет тот же набор методов и может использоваться в
тех же ситуациях.
В классе ArrayList три конструктора;
ArrayList()— создает пустой объект;
ArrayList(Collection
coll) — создает объект,
содержащий все элементы коллекции coll;
ArrayList
(int initCapacity) — создает пустой
Объект емкости
initCapacity.
Единственное
отличие класса ArrayList от класса Vector заключается в том, что класс ArrayList не синхронизован. Это означает что одновременное
изменение экземпляра этого класса несколькими подпроцессами приведет к
непредсказуемым результатам.
Сравнение
элементов коллекций
Интерфейс Comparator описывает два метода сравнения:
int compare (Object obji,
Object obj2)
возвращает отрицательное число, если obj1 в каком-то смысле меньше obj2; нуль, если они считаются равными;
положительное число, если obj1 больше obj2. Этот метод сравнения
обладает свойствами тождества, антисимметричности и транзитивности;
boolean
equals (Object obj)
сравнивает данный объект с объектом obj,
возвращая true, если объекты совпадают в каком-либо
смысле, заданном этим методом.
Для каждой
коллекции можно реализовать эти два метода, задав конкретный способ сравнения
элементов, и определить объект класса SortedMap вторым конструктором. Элементы коллекции будут автоматически
отсортированы в заданном порядке.
Классы,
создающие множества
Класс HashSet полностью реализует интерфейс Set и итератор типа Iterator. Класс HashSet используется в тех случаях, когда
надо хранить только одну копию каждого элемента.
В классе HashSet четыре конструктора:
HashSet() — создает пустой объект с
показателем загруженности 0,75;
HashSet (int
capacity) — создает
пустой объект с начальной емкостью capacity и показателем загруженности 0,75;
HashSet (int
capacity, float loadFactor) — создает пустой объект с начальной емкостью capacity и показателем загруженности loadFactor;
HashSet
(Collection coll)
создает объект, содержащий все элементы коллекции coll, с емкостью, равной удвоенному числу элементов
коллекции coll, но не менее 11, и показателем
загруженности 0,75.
Упорядоченные
множества
Класс TreeSet полностью реализует интерфейс SortedSet и итератор типа Iterator. Класс TreeSet реализован как бинарное дерево поиска, значит, его
элементы хранятся в упорядоченном виде. Это значительно ускоряет поиск нужного
элемента.
Порядок
задается либо естественным следованием элементов, либо объектом, реализующим
интерфейс сравнения Comparator.
Этот класс
удобен при поиске элемента во множестве, например, для проверки, обладает ли
какой-либо элемент свойством, определяющим множество.
В классе TreeSet четыре конструктора:
TreeSet() — создает пустой объект с
естественным порядком элементов;
TreeSet
(Comparator с) — создает
пустой объект, в котором порядок задается объектом сравнения с;
TreeSet
(Collection coll)
создает объект, содержащий все элементы коллекции coll, с естественным порядком ее элементов;
TreeSet
(SortedMap sf) — создает
объект, содержащий все элементы отображения sf, в
том же порядке.
Действия с
коллекциями
Коллекции
предназначены для хранения элементов в удобном для дальнейшей обработки виде.
Очень часто обработка заключается в сортировке элементов и поиске нужного
элемента. Эти и другие методы обработки собраны в класс Collections.
Методы класса Collections
Все методы
класса Collections статические, ими можно пользоваться,
не создавая экземпляры классу Collections
Как обычно в
статических методах, коллекция, с которой работает метод, задается его
аргументом.
Сортировка
может быть сделана только в упорядочиваемой коллекции, реализующей интерфейс List. Для сортировки в классе Collections есть два метода:
static void
sort (List coll)
сортирует в естественном порядке возрастания коллекцию coll, реализующую интерфейс List;
static
void sort (List coll, Comparator c) — сортирует коллекцию coll
в порядке,
заданном объектом с. После сортировки можно осуществить бинарный поиск в
коллекции:
static int
binarySearch(List coll, Object element) — отыскивает элемент element в отсортированной в естественном порядке возрастания
коллекции coll и возвращает индекс элемента или
отрицательное число, если элемент не найден; отрицательное число показывает
индекс, с которым элемент element был бы
вставлен в коллекцию, с обратным знаком;
static int
binarySearchfList coll, Object element, Comparator c) — то же, но коллекция отсортирована
в порядке, определенном объектом с.
Четыре метода
находят наибольший и наименьший элементы в упорядочиваемой коллекции:
static Object
max (Collection coll)
возвращает наибольший в естественном порядке элемент коллекции coll;
static Object max (Collection coll, Comparator c) — то
же в порядке,заданном объектом с;
static Object
min (Collection coll) — возвращает наименьший в
естественном порядке элемент коллекции coll;
static
Object min(Collection coll, Comparator c) — то же в порядке, заданном объектом с.
Два метода
"перемешивают" элементы коллекции в случайном порядке:
static void
shuffle (List coll)
случайные числа задаются по умолчанию;
static void
shuffle (List coll, Random r) — случайные числа определяются объектом r.
Метод reverse (List coll) меняет порядок расположения
элементов на обратный.
Метод copy (List from, List to) копирует коллекцию from в коллекцию to.
Метод fill (List coll, Object element) заменяет все элементы существующей
коллекции coll элементом element.
Приложение 4. Работа с датами и
временем
Работа с
датами и временем
Методы работы
с датами и показаниями времени собраны в два класса: Calendar и Date из пакета java.util.
Объект класса
Date хранит число миллисекунд, прошедших
с 1 января 1970 г. 00:00:00 по Гринвичу. Это "день рождения" UNIX, он
называется "Epoch".
Класс Date
удобно использовать для отсчета промежутков времени в миллисекундах.
Получить
текущее число миллисекунд, прошедших с момента Epoch на той машине, где выполняется программа, можно статическим методом
System.currentTimeMillis()
В классе Date два конструктора. Конструктор Date() заносит в создаваемый объект текущее время машины, на
которой выполняется программа, по системным часам, а конструктор Date(long millisec)
указанное число.
Получить значение,
хранящееся в объекте, можно методом long getTime(),
установить
новое значение — методом setTime(long
newTime).
Три
логических метода сравнивают отсчеты времени:
boolean after
(long when) — возвращает
true, если время when больше данного;
boolean
before (long when)
возвращает true, если время when меньше данного;
boolean after
(Object when)
возвращает true, если времена when — объекта класca Date и
данное совпадают.
Еще два
метода, сравнивая отсчеты времени, возвращают отрицательное число типа int, если данное время меньше аргумента when; нуль, если
времена совпадают; положительное число, если данное время больше аргумента when:
int
compareTo(Date when);
int
compareTo(Оbject when)
если when не относится к объектам класса Date, создается исключительная ситуация.
Преобразование
миллисекунд, хранящихся в объектах класса Date,
в текущее время и дату производится методами класса Calendar.
Класс
Calendar
Класс Calendar — абстрактный, в нем собраны общие
свойства календарей: юлианского, григорианского, лунного. В Java API пока есть
только одна его реализация — подкласс GregorianCalendar.
Поскольку Сalendar — абстрактный класс, его экземпляры
создаются четырьмя статическими методами по заданной локали и/или часовому
поясу:
Calendar
getlnstance()
Calendar
getlnstance(Locale loc)
Calendar
getlnstance(TimeZone tz)
Calendar
getlnstance(TimeZone tz, Locale loc)
Для работы с
месяцами определены целочисленные константы от JANUARY
до DECEMBER, для работы с днями недели
константы MONDAY до SUNDAY.
Первый день
недели можно узнать методом int
getFirstDayOfWeek(), a установить — методом setFirstDayOfWeek(int day), например:
setFirstDayOfWeek(Calendar.MONDAY)
Остальные
методы позволяют просмотреть время и часовой пояс или установить их.
Представление
даты и времени
Различные
способы представления дат и показаний времени можно осуществить методами,
собранными в абстрактный класс DateFormat и его
подкласс SimpleDateFormat из пакета Java. text.
Класс DateFormat предлагает четыре стиля представления
даты и времени:
стиль SHORT представляет дату и время в коротком числовом виде:
27.04.01 17:32; в локали США: 4/27/01 5:32 РМ;
стиль MEDIUM задает год четырьмя цифрами и показывает секунды:
27.04.2001 17:32:45; в локали США месяц представляется тремя буквами;
стиль LONG представляет месяц словом и добавляет часовой пояс:
27 апрель 2001 г. 17:32:45 GMT+03.-00;
стиль FULL в русской локали таков же, как и стиль LONG; в локали США добавляется еще день недели.
Есть еще
стиль DEFAULT, совпадающий со стилем MEDIUM.
При создании
объекта класса SimpieDateFormat можно задать в конструкторе шаблон,
определяющий какой-либо другой формат, например:
SimpieDateFormat
sdf = new SimpieDateFormat("dd-MM-yyyy hh.mm");
System.out.println(sdf.format(new Date()));
Получим вывод
в таком виде: 27-07-2004 17.32.
Приложение 5. Файловый
ввод/вывод.
Поскольку
файлы в большинстве современных операционных систем понимаются как
последовательность байтов, для файлового ввода/вывода создаются байтовые потоки
с помощью классов FileInputStream и FileOutputStream.
Очень много файлов содержат тексты, составленные из символов. Несмотря на то,
что символы могут храниться в кодировке Unicode, эти тексты чаще всего записаны
в байтовых кодировках. Поэтому и для текстовых файлов можно использовать
байтовые потоки. В таком случае со стороны программы придется организовать
преобразование байтов в символы и обратно.
Чтобы
облегчить это преобразование, в пакет java.io введены классы FileReader и FileWriter. Они организуют
преобразование потока: со стороны программы потоки символьные, со стороны файла
байтовые. Это происходит потому, что данные классы расширяют классы
InputStreamReader и OutputstreamWriter, соответственно, значит, содержат
"переходное кольцо" внутри себя.
Несмотря на
различие потоков, использование классов файлового ввода/вывода очень похоже.
В
конструкторах всех четырех файловых потоков задается имя файла в виде строки
типа String или ссылка на объект класса
File. Конструкторы не только создают объект, но и отыскивают файл и открывают
его. Например:
FileInputStream
fis = new FileInputStream("C:\\PrWr.Java");
FileReader
fr = new FileReader("D:\\jdkl.3\\src\\PrWr.Java");
При неудаче
выбрасывается исключение класса FileNotFoundException, но конструктор класса
FileWriter выбрасывает более общее исключение IOException.
После
открытия выходного потока типа FileWriter или FileOutputStream
содержимое файла, если он был не пуст, стирается. Для того чтобы можно было
делать запись в конец файла, и в том и в другом классе предусмотрен конструктор
с двумя аргументами. Если второй аргумент равен true, то происходит дозапись в
конец файла, если false, то файл заполняется новой информацией. Например:
FileWriter
fw = new FileWriter("c:\\8.txt", true);
FileOutputStream
fos = new FileOutputStream("D:\\samples\\newfile.txt");
Сразу после
выполнения конструктора можно читать файл:
fis.read();
fr.read();
или
записывать в него:
fos.write((char)с); fw.write((char)с);
По окончании
работы с файлом поток следует закрыть методом close().
Преобразование
потоков в классах FileReader и FileWriter выполняется по кодовым таблицам
установленной на компьютере локали. Для правильного ввода кириллицы надо
применять FileReader, a нe FileInputStream. Если файл содержит текст в кодировке,
отличной от локальной кодировки, то придется вставлять "переходное
кольцо" вручную, как это может делаться для консоли, например:
InputStreamReader
isr = new InputStreamReader(fis, "KOI8_R"));
Байтовый
поток fis определен выше.
Получение
свойств файла
В
конструкторах классов файлового ввода/вывода, описанных в предыдущем разделе,
указывалось имя файла в виде строки. При этом оставалось неизвестным,
существует ли файл, разрешен ли к, нему доступ, какова длина файла.
Получить
такие сведения можно от предварительно созданного экземпляра класса File,
содержащего сведения о файле. В конструкторе этого класса
File(String
filename)
указывается
путь к файлу или каталогу, записанный по правилам операционной системы.
Конструктор
не проверяет, существует ли файл с таким именем, поэтому после создания объекта
следует это проверить логическим методом exists().
Класс File
содержит около сорока методов, позволяющих узнать различные свойства файла или
каталога.
Прежде всего,
логическими методами isFile(), isDirectory() можно выяснить, является ли путь, указанный в конструкторе,
путем к файлу или каталогу.
Для каталога
можно получить его содержимое — список имен файлов и подкаталогов— методом list(), возвращающим массив строк String[].
Можно получить такой же список в виде массива объектов класса File[] методом listFiles().
Если каталог
с указанным в конструкторе путем не существует, его можно создать логическим
методом mkdir(). Этот метод возвращает true, если
каталог удалось создать. Логический метод mkdirs() создает еще и все несуществующие каталоги, указанные в пути.
Логические
методы canRead(), canwrite() показывают права доступа к файлу.
Файл можно
переименовать логическим методом renameTo(File newName) или удалить логическим методом delete(). Эти методы возвращают true, если
операция прошла удачно.
Если файл с
указанным в конструкторе путем не существует, его можно создать логическим
методом createNewFile(), возвращающим true, если файл не
существовал, и его удалось создать, и false, если файл уже существовал.
Несколько
методов getxxx() возвращают имя файла, имя каталога и
другие сведения о пути к файлу. Эти методы полезны в тех случаях, когда ссылка
на объект класса File возвращается другими методами и
нужны сведения о файле. Наконец, метод toURL()
возвращает путь к файлу в форме URL.
Буферизованный ввод/вывод
Операции ввода/вывода по сравнению с операциями в оперативной памяти
выполняются очень медленно. Для компенсации в оперативной памяти выделяется
некоторая промежуточная область — буфер, в которой постепенно накапливается
информация. Когда буфер заполнен, его содержимое быстро переносится
процессором, буфер очищается и снова заполняется информацией.
Классы файлового ввода/вывода не занимаются буферизацией. Для этой цели
есть четыре специальных класса BufferedXxx. Они присоединяются к потокам
ввода/вывода как "переходное кольцо", например:
BufferedReader br = new BufferedReader(isr);
BufferedWriter bw = new BufferedWriter(fw);
Потоки isr и fw определены выше.
Данная программа читает текстовый файл, написанный в кодировке СР866, и
записывает его содержимое в файл в кодировке Cp1251. При чтении и записи применяется буферизация.
import java.io.*;
class DOStoWindows{
public static void main(String[] args) throws IOException{
BufferedReader br = new BufferedReader(
new InputStreamReader(
new FileInputStream d:\\dos.txt, "Cp866"));
BufferedWriter bw = new BufferedWriter(
new OutputStreamWriter(
new FileOutputStream d:\\windows.txt, "Cp1251"));
int с = 0;
while ((c = br.read()) != -1) bw.write((char)c);
br.close(); bw.close();
System.out.println("Все OK.");
}
}
Приложение 6. Обработка исключений
Исключительные
ситуации (exceptions)
могут возникнуть во время выполнения (runtime) программы, прервав ее обычный
ход. К ним относится деление на нуль, отсутствие загружаемого файла,
отрицательный или вышедший за верхний предел индекс массива, переполнение
выделенной памяти и масса других неприятностей, которые могут случиться в самый
неподходящий момент.
В
объектно-ориентированных языках программирования принят такой подход. При
возникновении исключительной ситуации исполняющая система создает объект
определенного класса, соответствующего возникшей ситуации, содержащий сведения
о том, что, где и когда произошло. Этот объект передается на обработку
программе, в которой возникло исключение. Если программа не обрабатывает
исключение, то объект возвращается обработчику по умолчанию исполняющей
системы. Обработчик поступает очень просто: выводит на консоль сообщение о
произошедшем исключении и прекращает выполнение приложения.
Мы можем перехватить и
обработать исключение в программе. При описании обработки применяется
бейсбольная терминология. Говорят, что исполняющая система или программа
"выбрасывает" (throws) объект-исключение. Этот объект
"пролетает" через всю программу, появившись сначала в том методе, где
произошло исключение, а программа в одном или нескольких местах пытается (try)
его "перехватить" (catch) и обработать. Обработку можно сделать
полностью в одном месте, а можно обработать исключение в одном месте, выбросить
снова, перехватить в другом месте и обрабатывать дальше.
Для того чтобы попытаться
(try) перехватить (catch) объект-исключение, надо весь код программы, в котором
может возникнуть исключительная ситуация, охватить оператором try{} catch() {}.
Каждый блок catch(){} перехватывает исключение только одного типа, того,
который указан в его аргументе. Но можно написать несколько блоков catch(){}
для перехвата нескольких типов исключений.
После блоков перехвата
может быть вставлен еще один, необязательный блок finally(). Он предназначен для выполнения действий, которые надо
выполнить обязательно, чтобы ни случилось. Все, что написано в этом блоке,
будет выполнено и при возникновении исключения, и при обычном ходе программы, и
даже если выход из блока try{} осуществляется оператором return.
Если в операторе
обработки исключений есть блок finally{}, то блок catch () {} может
отсутствовать, т. е. можно не перехватывать исключение, но при его
возникновении все-таки проделать какие-то обязательные действия. Пустой блок
catch (){}, в котором между фигурными скобками нет ничего, даже пробела, тоже
считается обработкой исключения и приводит к тому, что выполнение программы не
прекратится.
То обстоятельство, что
метод не обрабатывает возникающее в нем исключение, а выбрасывает (throws) его,
следует отмечать в заголовке метода служебным словом throws и указанием класса
исключения:
private static
void f(int n) throws ArithmeticException{
System.out.println("
10 / n = " + (10 / n)) ;
}
Исключение ArithmeticException выпадает, например, при делении на
ноль.
Дело в том, что
спецификация JLS делит все исключения на проверяемые (checked), те, которые
проверяет компилятор, и непроверяемые (unchecked). При проверке компилятор
замечает необработанные в методах и конструкторах исключения и считает ошибкой
отсутствие в заголовке таких методов и конструкторов пометки throws. Именно для
предотвращения подобных ошибок вставляются в листинги блоки обработки
исключений.
Так вот, исключения
класса RuntimeException и его подклассов, одним из которых является
ArithmeticException, непроверяемые, для них пометка throws необязательна. Еще
одно большое семейство непроверяемых исключений составляет класс Error и его
расширения.
Почему компилятор не
проверяет эти типы исключений? Причина в том, что исключения класса
RuntimeException свидетельствуют об ошибках в программе, и единственно разумный
метод их обработки — исправить исходный текст программы и перекомпилировать ее.
Что касается класса Error, то эти исключения очень трудно локализовать и на
стадии компиляции невозможно определить место их появления.
Напротив, возникновение
проверяемого исключения показывает, что программа недостаточно продумана, не
все возможные ситуации описаны. Такая программа должна быть доработана, о чем и
напоминает компилятор.
Если метод или
конструктор выбрасывает несколько исключений, то их надо перечислить через
запятую после слова throws.
Этот оператор очень
прост: после слова throw через пробел записывается объект класса-исключения.
Достаточно часто он создается прямо в операторе throw, например:
throw new
ArithmeticException();
Оператор можно записать в
любом месте программы. Он немедленно выбрасывает записанный в нем
объект-исключение и дальше обработка этого исключения идет как обычно, будто бы
здесь произошло деление на нуль или другое действие, вызвавшее исключение
класса ArithmeticException.
Итак, каждый блок catch()
и перехватывает один определенный тип исключений. Если требуется одинаково
обработать несколько типов исключений, то можно воспользоваться тем, что классы-исключения
образуют иерархию. Таким образом, перемещаясь по иерархии классов-исключений,
мы можем обрабатывать сразу более или менее крупные совокупности исключений.
Рассмотрим подробнее иерархию классов-исключений.
Все классы-исключения
расширяют класс Throwable
непосредственное расширение класса Object.
У класса Throwable и у всех его расширений по традиции
два конструктора:
·
Throwable () — конструктор по умолчанию;
·
Throwable (String message) — создаваемый
объект будет содержать произвольное сообщение message.
Записанное в конструкторе
сообщение можно получить затем методом getMessage (). Если объект создавался
конструктором по умолчанию, то данный метод возвратит null.
Метод toString() возвращает краткое описание
события.
Три метода выводят
сообщения обо всех методах, встретившихся по пути "полета"
исключения:
·
printstackTrace()
выводит сообщения в стандартный вывод, как правило, это консоль;
·
printStackTrace(PrintStream
stream) — выводит сообщения в байтовый поток stream;
·
printStackTrace(PrintWriter
stream) — выводит сообщения в символьный поток stream.
У класса Throwable два непосредственных наследника
классы Error и Exception. Они не добавляют новых методов, а служат для
разделения классов-исключений на два больших семейства — семейство
классов-ошибок (error) и семейство собственно классов-исключений (exception).
Классы-ошибки,
расширяющие класс Error, свидетельствуют о возникновении сложных ситуаций в
виртуальной машине Java. Их обработка требует глубокого понимания всех
тонкостей работы JVM. Ее не рекомендуется выполнять в обычной программе. Не
советуют даже выбрасывать ошибки оператором throw. He следует делать свои
классы-исключения расширениями класса Error или какого-то его подкласса.
Имена классов-ошибок, по
соглашению, заканчиваются словом Error.
Классы-исключения,
расширяющие класс Exception, отмечают возникновение обычной нештатной ситуации,
которую можно и даже нужно обработать. Такие исключения следует выбросить
оператором throw. Классов-исключений очень много, более двухсот. Они разбросаны
буквально по всем пакетам J2SDK. В большинстве случаев вы способны подобрать
готовый класс-исключение для обработки исключительных ситуаций в своей
программе. При желании можно создать и свой класс-исключение, расширив класс
Exception или любой его подкласс.
Среди классов-исключений
выделяется класс RuntimeException — прямое расширение класса Exception. В нем и
его подклассах отмечаются исключения, возникшие при работе JVM, но не столь
серьезные, как ошибки. Их можно обрабатывать и выбрасывать, расширять своими
классами, но лучше доверить это JVM, поскольку чаще всего это просто ошибка в
программе, которую надо исправить. Особенность исключений данного класса в том,
что их не надо отмечать в заголовке метода пометкой throws.
Имена классов-исключений,
по соглашению, заканчиваются словом Exception.
Блоки catch () {}
перехватывают исключения в порядке написания этих блоков. Это правило приводит
к интересным результатам.
try{
// Операторы, вызывающие
исключения
}catch(Exception e){
// Какая-то обработка
}catch(RuntimeException re){
// Никогда не будет
выполнен!
}
Второй блок не будет
выполняться, поскольку исключение типа RuntimeException является исключением
общего типа Exception и будет перехватываться предыдущим блоком catch () {}.
|



