Информатика программирование : Реферат: Особенности развития, структурная и функциональная организация суперЭВМ
Реферат: Особенности развития, структурная и функциональная организация суперЭВМ
ФЕДЕРАЛЬНОЕ
АГЕНСТВО ПО ОБРАЗОВАНИЮ
Государственное
образовательное учреждение высшего профессионального образования
«ТОМСКИЙ
ПОЛИТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ»
Факультет
автоматики и вычислительной техники
Кафедра
вычислительной техники
Организация
ЭВМ и систем
Реферат на
тему
«Особенности
развития, структурная и функциональная организация суперЭВМ»
Исполнитель
студент
группы 8030 __________ И.А. Переливский
Руководитель
доцент,
к.т.н__________А.Д. Чередов
Томск – 2008
СОДЕРЖАНИЕ
Введение.........................................................................................................3
1.
Краткая история
появления параллелелизма в ЭВМ...................5
2.
Классификация
параллельных вычислительных систем............8
3.
Основные концепции
проектирования суперЭВМ....................15
4.
Краткие
харатеристики наиболее распространенных суперкомпьютеров……………………………………………………………….20
5.
Десятка самых
мощных компьютеров........................................30
Заключение..................................................................................................32
Список источников.....................................................................................33
ВВЕДЕНИЕ
В настоящее время переход
к новым поколениям вычислительных средств приобретает особую актуальность. Это
связано с потребностями решения сложных задач больших размерностей. Непрерывный
рост характеристик новых образцов вооружений требует разработки и создания
принципиально новых вычислительных средств для поддержки их эффективного
функционирования. В связи с этим, все более возрастают требования к
производительности и надежности вычислительных средств для решения
военно-прикладных задач. Однопроцессорные вычислительные системы уже не
справляются с решением большинства военно-прикладных задач в реальном времени,
поэтому для повышения производительности вычислительных систем военного
назначения все чаще используются многопроцессорные вычислительные системы (МВС).
Наибольший вклад в развитие
вычислительных средств всегда вносили технологические решения, при этом
основополагающей характеристикой поколения вычислительных систем являлась
элементная база, так как переход на новую элементную базу хорошо коррелируется
с новым уровнем показателей производительности и надежности вычислительных
систем. Разработка все новых и новых поколений микропроцессоров несколько
приостановило поиски принципиально новых архитектурных решений. В то же время
становится очевидным, что чисто технологические решения утратили свое
монопольное положение. Так, например, в ближайшей перспективе заметно
возрастает значение проблемы преодоления разрыва между аппаратными средствами
и методами программирования. Данная проблема решается чисто архитектурными
средствами, при этом роль технологии является косвенной: высокая степень
интеграции создает условия для реализации новых архитектурных решений. При этом
стало очевидным, что без кардинальной перестройки архитектурных принципов
поддерживать интенсивные темпы развития средств вычислительной техники уже
невозможно.
Основными требованиями,
предъявляемыми к многопроцессорным системам с массовым параллелизмом, являются:
необходимость высокой производительности для любого алгоритма; согласование
производительности памяти с производительностью вычислительной части;
способность микропроцессоров согласованно работать при непредсказуемых
задержках данных от любого источника и, наконец, машинно-независимое
программирование.
Увеличение степени
параллелизма вызывает увеличение числа логических схем, что сопровождается
увеличением физических размеров, в результате чего возрастают задержки сигналов
на межсоединениях. Этот фактор приводит либо к снижению тактовой частоты, либо
к созданию дополнительных логических ступеней и, в результате, к потере
производительности. Рост числа логических схем также приводит к росту
потребляемой энергии и отводимого тепла. Кроме того, следует подчеркнуть, что
более высокочастотные логические схемы при прочих равных условиях потребляют
большую мощность на один вентиль. В результате возникает теплофизический
барьер, обусловленный двумя факторами: высокой удельной плотностью теплового
потока, что требует применения сложных средств отвода тепла, и высокой общей
мощностью системы, что вызывает необходимость использования сложной системы
энергообеспечения и специальных помещений.
Другим фактором, влияющим
на архитектуру высокопроизводительных вычислительных систем, является
взаимозависимость архитектуры и алгоритмов задач. Этот фактор часто приводит к
необходимости создания проблемно-ориентированных систем, при этом может быть
достигнута максимальная производительность для данного класса задач. Указанная
взаимозависимость является стимулом для поиска алгоритмов, наилучшим образом
соответствующих возможным формам параллелизма на уровне аппаратуры. А так как
для написания программ используются языки высокого уровня, необходимы
определенные средства автоматизации процессов распараллеливания и оптимизации
программ.
1. КРАТКАЯ ИСТОРИЯ
ПОЯВЛЕНИЯ ПАРАЛЛЕЛЕЛИЗМА В ЭВМ
Идеи параллельной
обработки появились очень давно. Изначально они внедрялись в самых передовых, а
потому единичных, компьютерах своего времени. Затем после должной отработки
технологии и удешевления производства они спускались в компьютеры среднего
класса, и наконец, сегодня, все это в полном объеме воплощается в рабочих
станциях и персональных компьютерах.
Для того чтобы убедиться,
что все основные нововведения в архитектуре современных процессоров на самом
деле используются еще со времен, когда ни микропроцессоров, ни понятия
суперкомпьютеров еще не было, совершим маленький экскурс в историю, начав
практически с момента рождения первых ЭВМ.
IBM 701
(1953), IBM 704 (1955): разрядно-параллельная память, разрядно-параллельная арифметика.
Все самые первые компьютеры (EDSAC, EDVAC, UNIVAC) имели
разрядно-последовательную память, из которой слова считывались последовательно
бит за битом. Первым коммерчески доступным компьютером, использующим
разрядно-параллельную память (на CRT) и разрядно-параллельную арифметику, стал
IBM 701, а наибольшую популярность получила модель IBM 704 (продано 150 экз.),
в которой, помимо сказанного, была впервые применена память на ферритовых
сердечниках и аппаратное АУ с плавающей точкой.
IBM 709 (1958):
независимые процессоры ввода/вывода. Процессоры первых компьютеров сами
управляли вводом/выводом. Однако скорость работы самого быстрого внешнего
устройства, а по тем временам это магнитная лента, была в 1000 раз меньше
скорости процессора, поэтому во время операций ввода/вывода процессор
фактически простаивал. В 1958г. к компьютеру IBM 704 присоединили 6 независимых
процессоров ввода/вывода, которые после получения команд могли работать
параллельно с основным процессором, а сам компьютер переименовали в IBM 709.
Данная модель получилась удивительно удачной, так как вместе с модификациями
было продано около 400 экземпляров, причем последний был выключен в 1975 году -
20 лет существования!
IBM
STRETCH (1961): опережающий просмотр вперед, расслоение памяти. В 1956 году IBM
подписывает контракт с Лос-Аламосской научной лабораторией на разработку
компьютера STRETCH, имеющего две принципиально важные особенности: опережающий
просмотр вперед для выборки команд и расслоение памяти на два банка для согласования
низкой скорости выборки из памяти и скорости выполнения операций.
ATLAS
(1963): конвейер команд. Впервые конвейерный принцип выполнения команд был
использован в машине ATLAS, разработанной в Манчестерском университете.
Выполнение команд разбито на 4 стадии: выборка команды, вычисление адреса
операнда, выборка операнда и выполнение операции. Конвейеризация позволила
уменьшить время выполнения команд с 6 мкс до 1,6 мкс. Данный компьютер оказал
огромное влияние, как на архитектуру ЭВМ, так и на программное обеспечение: в
нем впервые использована мультипрограммная ОС, основанная на использовании
виртуальной памяти и системы прерываний.
CDC 6600
(1964): независимые функциональные устройства.
Фирма Control Data Corporation (CDC) при непосредственном участии одного из ее
основателей, Сеймура Р.Крэя (Seymour R.Cray) выпускает компьютер CDC-6600 -
первый компьютер, в котором использовалось несколько независимых функциональных
устройств. Для сравнения с сегодняшним днем приведем некоторые параметры
компьютера:
- время такта 100нс;
- производительность 2-3 млн. операций
в секунду;
- оперативная память разбита на 32
банка по 4096 60-ти разрядных слов;
- цикл памяти 1мкс;
- 10 независимых функциональных
устройств.
Машина имела громадный
успех на научном рынке, активно вытесняя машины фирмы IBM.
CDC 7600
(1969): конвейерные независимые функциональные устройства.
CDC выпускает компьютер
CDC-7600 с восемью независимыми конвейерными функциональными устройствами -
сочетание параллельной и конвейерной обработки. Основные параметры:
- такт 27,5 нс;
- 10-15 млн. опер/сек;
- 8 конвейерных ФУ;
- 2-х уровневая память.
ILLIAC
IV (1974): матричные процессоры.
- Проект: 256 процессорных элементов
(ПЭ) = 4 квадранта по 64ПЭ, возможность реконфигурации: 2 квадранта по 128ПЭ
или 1 квадрант из 256ПЭ, такт 40нс, производительность 1Гфлоп;
- работы начаты в 1967 году, к концу
1971 изготовлена система из 1 квадранта, в 1974г. она введена в эксплуатацию,
доводка велась до 1975 года;
- центральная часть: устройство
управления (УУ) + матрица из 64 ПЭ;
- УУ это простая ЭВМ с небольшой
производительностью, управляющая матрицей ПЭ; все ПЭ матрицы работали в
синхронном режиме, выполняя в каждый момент времени одну и ту же команду,
поступившую от УУ, но над своими данными;
- ПЭ имел собственное АЛУ с полным
набором команд, ОП - 2Кслова по 64 разряда, цикл памяти 350нс, каждый ПЭ имел
непосредственный доступ только к своей ОП;
- сеть пересылки данных: двумерный тор
со сдвигом на 1 по границе по горизонтали.
Несмотря на результат в
сравнении с проектом: стоимость в 4 раза выше, сделан лишь 1 квадрант, такт
80нс, реальная производительность до 50Мфлоп - данный проект оказал огромное
влияние на архитектуру последующих машин, построенных по схожему принципу, в
частности: PEPE, BSP, ICL DAP.
CRAY 1 (1976): векторно-конвейерные процессоры.
В 1972 году С. Крэй
покидает CDC и основывает свою компанию Cray Research, которая в 1976г.
выпускает первый векторно-конвейерный компьютер CRAY-1: время такта 12.5нс, 12
конвейерных функциональных устройств, пиковая производительность 160 миллионов
операций в секунду, оперативная память до 1Мслова (слово - 64 разряда), цикл
памяти 50нс. Главным новшеством является введение векторных команд, работающих
с целыми массивами независимых данных и позволяющих эффективно использовать
конвейерные функциональные устройства.
2. КЛАССИФИКАЦИЯ ПАРАЛЛЕЛЬНЫХ
ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
Основным параметром
классификации паралелльных компьютеров является наличие общей (SMP) или
распределенной памяти (MPP). Нечто среднее между SMP и MPP представляют собой
NUMA-архитектуры, где память физически распределена, но логически общедоступна.
Кластерные системы являются более дешевым вариантом MPP. При поддержке команд
обработки векторных данных говорят о векторно-конвейерных процессорах, которые,
в свою очередь могут объединяться в PVP-системы с использованием общей или
распределенной памяти. Все большую популярность приобретают идеи комбинирования
различных архитектур в одной системе и построения неоднородных систем.
При организациях
распределенных вычислений в глобальных сетях (Интернет) говорят о
мета-компьютерах, которые, строго говоря, не представляют из себя параллельных
архитектур.
Более подробно
особенности всех перечисленных архитектур будут рассмотрены далее на этой
странице, а также в описаниях конкретных компьютеров - представителей этих
классов. Для каждого класса приводится следующая информация:
- краткое описание особенностей
архитектуры;
- примеры конкретных компьютеров;
- перспективы масштабируемости;
- типичные особенности построения
операционных систем;
- наиболее характерная модель
программирования (хотя возможны и другие).
Таблица 2.1
Массивно-параллельные системы (MPP)
| Архитектура |
Система
состоит из однородных вычислительных узлов, включающих:
- один
или несколько центральных процессоров (обычно RISC);
- локальную
память (прямой доступ к памяти других узлов невозможен);
- коммуникационный
процессор или сетевой адаптер;
- иногда
- жесткие диски (как в SP) и/или другие устройства В/В.
К системе
могут быть добавлены специальные узлы ввода-вывода и управляющие узлы. Узлы
связаны через некоторую коммуникационную среду (высокоскоростная сеть,
коммутатор и т.п.)
|
| Примеры |
IBM RS/6000 SP2, Intel PARAGON/ASCI Red, CRAY T3E, Hitachi SR8000,
транспьютерные системы Parsytec. |
| Масштабируемость |
Общее число
процессоров в реальных системах достигает нескольких тысяч (ASCI Red, Blue
Mountain). |
| Операционная
система |
Существуют два
основных варианта:
Полноценная ОС
работает только на управляющей машине (front-end), на каждом узле работает
сильно урезанный вариант ОС, обеспечивающие только работу расположенной в нем
ветви параллельного приложения. Пример: Cray T3E.
На каждом узле
работает полноценная UNIX-подобная ОС (вариант, близкий к кластерному
подходу). Пример: IBM RS/6000 SP + ОС AIX, устанавливаемая отдельно на каждом
узле.
|
| Модель
программирования |
Программирование
в рамках модели передачи сообщений ( MPI, PVM, BSPlib) |
Таблица 2.2
Симметричные мультипроцессорные системы (SMP)
| Архитектура |
Система
состоит из нескольких однородных процессоров и массива общей памяти (обычно
из нескольких независимых блоков). Все процессоры имеют доступ к любой точке
памяти с одинаковой скоростью. Процессоры подключены к памяти либо с помощью
общей шины (базовые 2-4 процессорные SMP-сервера), либо с помощью
crossbar-коммутатора (HP 9000). Аппаратно поддерживается когерентность кэшей. |
| Примеры |
HP 9000
V-class, N-class; SMP-cервера и рабочие станции на базе процессоров Intel
(IBM, HP, Compaq, Dell, ALR, Unisys, DG, Fujitsu и др.). |
| Масштабируемость |
Наличие общей
памяти сильно упрощает взаимодействие процессоров между собой, однако
накладывает сильные ограничения на их число - не более 32 в реальных
системах. Для построения масштабируемых систем на базе SMP используются
кластерные или NUMA-архитектуры. |
| Операционная
система |
Вся система
работает под управлением единой ОС (обычно UNIX-подобной, но для
Intel-платформ поддерживается Windows NT). ОС автоматически (в процессе
работы) распределяет процессы/нити по процессорам (scheduling), но иногда
возможна и явная привязка. |
| Модель
программирования |
Программирование
в модели общей памяти. (POSIX threads, OpenMP). Для SMP-систем существуют
сравнительно эффективные средства автоматического распараллеливания. |
Таблица 2.3
Системы с неоднородным доступом к памяти (NUMA)
| Архитектура |
Система
состоит из однородных базовых модулей (плат), состоящих из небольшого числа
процессоров и блока памяти. Модули объединены с помощью высокоскоростного
коммутатора. Поддерживается единое адресное пространство, аппаратно
поддерживается доступ к удаленной памяти, т.е. к памяти других модулей. При
этом доступ к локальной памяти в несколько раз быстрее, чем к удаленной.
В случае, если
аппаратно поддерживается когерентность кэшей во всей системе (обычно это
так), говорят об архитектуре cc-NUMA (cache-coherent NUMA)
|
| Примеры |
HP HP 9000
V-class в SCA-конфигурациях, SGI Origin2000, Sun HPC 10000, IBM/Sequent
NUMA-Q 2000, SNI RM600. |
| Масштабируемость |
Масштабируемость
NUMA-систем ограничивается объемом адресного пространства, возможностями
аппаратуры поддежки когерентности кэшей и возможностями операционной системы по
управлению большим числом процессоров. На настоящий момент, максимальное
число процессоров в NUMA-системах составляет 256 (Origin2000). |
| Операционная
система |
Обычно вся
система работает под управлением единой ОС, как в SMP. Но возможны также
варианты динамического "подразделения" системы, когда отдельные
"разделы" системы работают под управлением разных ОС (например,
Windows NT и UNIX в NUMA-Q 2000). |
| Модель
программирования |
Аналогично
SMP. |
Таблица 2.4 – Параллельные векторные системы (PVP)
| Архитектура |
Основным
признаком PVP-систем является наличие специальных векторно-конвейерных
процессоров, в которых предусмотрены команды однотипной обработки векторов
независимых данных, эффективно выполняющиеся на конвейерных функциональных устройствах.
Как правило,
несколько таких процессоров (1-16) работают одновременно над общей памятью
(аналогично SMP) в рамках многопроцессорных конфигураций. Несколько таких
узлов могут быть объединены с помощью коммутатора (аналогично MPP).
|
| Примеры |
NEC SX-4/SX-5,
линия векторно-конвейерных компьютеров CRAY: от CRAY-1, CRAY J90/T90, CRAY
SV1, CRAY X1, серия Fujitsu VPP. |
| Модель
программирования |
Эффективное
программирование подразумевает векторизацию циклов (для достижения разумной
производительности одного процессора) и их распараллеливание (для
одновременной загрузки нескольких процессоров одним приложением). |
|
|
|
Таблица 2.5 – Кластерные системы
| Архитектура |
Набор рабочих
станций (или даже ПК) общего назначения, используется в качестве дешевого
варианта массивно-параллельного компьютера. Для связи узлов используется одна
из стандартных сетевых технологий (Fast/Gigabit Ethernet, Myrinet) на базе
шинной архитектуры или коммутатора.
При
объединении в кластер компьютеров разной мощности или разной архитектуры,
говорят о гетерогенных (неоднородных) кластерах.
Узлы кластера
могут одновременно использоваться в качестве пользовательских рабочих
станций. В случае, когда это не нужно, узлы могут быть существенно облегчены
и/или установлены в стойку.
|
| Примеры |
NT-кластер в
NCSA, Beowulf-кластеры. |
| Операционная
система |
Используются
стандартные для рабочих станций ОС, чаще всего, свободно распространяемые -
Linux/FreeBSD, вместе со специальными средствами поддержки параллельного программирования
и распределения нагрузки. |
| Модель
программирования |
Программирование,
как правило, в рамках модели передачи сообщений (чаще всего - MPI). Дешевизна
подобных систем оборачивается большими накладными расходами на взаимодействие
параллельных процессов между собой, что сильно сужает потенциальный класс
решаемых задач. |
Классификация
параллельных вычислительных систем, предложенная Т.Джоном, основана на
разделении МВС по двум критериям: способу построения памяти (общая или
распределенная) и способу передачи информации. Основные типы машин по
классификации Т.Джона представлены в таблице 2.6. Здесь приняты следующие
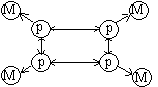
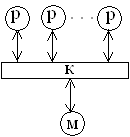
обозначения: p - элементарный процессор, M - элемент памяти, K - коммутатор, С
- кэш-память.
Параллельная
вычислительная система с общей памятью и шинной организацией обмена (машина 1)
позволяет каждому процессору системы видеть", как решается задача в целом,
а не только те части, над
| Типы передачи
Сообщений |
Типы памяти |
| Общая память |
Общая и
распределенная |
Распределенная
память |
| Шинные
соединения |
1.
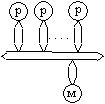
|
2.

|
3.
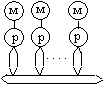
|
| Фиксирован-ные
перекрест-ные соедине-ния |
4.
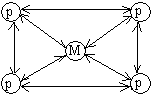
|
5.
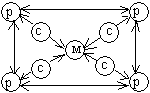
|
6.
|
| Коммутацион-ные
структуры |
7.
|
8.

|
9.

|
Таблица 2.6
Классификация МВС по типам памяти и передачи сообщений которыми он работает. Общая шина,
связанная с памятью, вызывает серьезные проблемы для обеспечения высокой
пропускной способности каналов обмена. Одним из способов обойти эту ситуацию
является использование кэш-памяти (машина 2). В этом случае возникает проблема
когерентности содержимого кэш-памяти и основной. Другим способом повышения
производительности систем является отказ от центральной памяти (машина 3).
Идеальной машиной
является вычислительная система, у которой каждый процессор имеет прямые каналы
связи с другими процессорами, но в этом случае требуется чрезвычайно большой
объем оборудования для организации межпроцессорных обменов. Определенный
компромисс представляет сеть с фиксированной топологией, в которой каждый
процессор соединен с некоторым подмножеством процессоров системы. Если
процессорам, не имеющим непосредственного канала обмена, необходимо
взаимодействовать, они передают сообщения через промежуточные процессоры. Одно
из преимуществ такого подхода - не ограничивается рост числа процессоров в системе.
Недостаток - требуется оптимизация прикладных программ, чтобы обеспечить
выполнение параллельных процессов, для которых необходимо активное воздействие
на соседние процессоры.
Наиболее интересным
вариантом для перспективных параллельных вычислительных комплексов является
сочетание достоинства архитектур с распределенной памятью и каналами
межпроцессорного обмена. Один из возможных методов построения таких
комбинированных архитектур - конфигурация с коммутацией, когда процессор имеет
локальную память, а соединяются процессоры между собой с помощью коммутатора
(машина 9). Коммутатор может оказаться весьма полезным для группы процессоров с
распределяемой памятью (машина 8). Данная конфигурация похожа на машину с общей
памятью (машина 7), но здесь исключены проблемы пропускной способности шины.
Недостатками
классификации Т.Джона является скрытие уровня параллелизма в системе.
Параллелизм любого рода
требует одновременной работы, по крайней мере, двух устройств. Такими
устройствами могут быть: арифметико-логические устройства (АЛУ), устройства
управления (УУ). В ЭВМ классической архитектуры УУ и АЛУ образуют процессор.
Увеличение числа процессоров или числа АЛУ в каждом из них приводит к
соответствующему росту параллелизма. Наличие в ЭВМ нескольких процессоров
означает, что одновременно (параллельно) могут выполняться несколько программ
или несколько фрагментов одной программы. Работа нескольких АЛУ под
управлением одного УУ означает, что множество данных может обрабатываться
параллельно по одной программе. В соответствии с этим описание структур
параллельных систем можно представить в виде упорядоченной тройки:
<k,d,w>,
где k - количество
устройств управления, т.е. наибольшее количество независимо и одновременно
выполняемых программ в системе;
d - количество АЛУ,
приходящихся на одно устройство управления;
w - количество разрядов,
содержимое которых обрабатывается одновременно (параллельно) одним
арифметико-логическим устройством.
Другая форма
распараллеливания - конвейеризация, также требует наличия нескольких ЦП или
АЛУ. В то время, как множество данных обрабатывается на одном устройстве,
другое множество данных может обрабатываться на следующем устройстве и т.д.,
при этом в процессе обработки возникает поток данных от одного устройства (ЦП
или АЛУ) к следующему. В течение всего процесса над одним множеством данных
выполняется одно за другим n действий. Одновременно в конвейере на разных
стадиях обработки могут находиться от 1 до n данных.
Параллелизм и
конвейеризацию можно рассматривать на трех различных уровнях, представленных в
таблице 2.7. Шесть основных форм параллелизма, в широком смысле этого слова,
позволяют построить схему классификации, в рамках которой можно описать
разнообразие высокопроизводительных вычислительных систем и отразить их
эволюцию.
Таблица 2.7 – Классификация
МВС по типу распараллеливания
|
Уровень
параллелизма
|
Параллелизм |
Конвейеризация |
| Программы |
Мультипроцессор
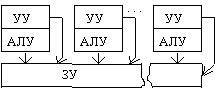
|
Макроконвейер
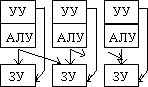
|
| Команды |
Матричный
процессор
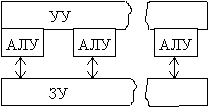
|
Конвейер
команд
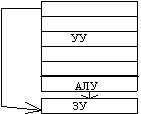
|
| Данные |
Множество
разрядов
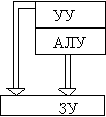
|
Арифметический
конвейер
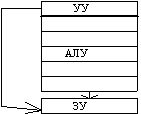
|
3. ОСНОВНЫЕ КОНЦЕПЦИИ ПРОЕКТИРОВАНИЯ
СУПЕРЭВМ
В векторных суперЭВМ
обеспечена предельная производительность для процессов скалярной и векторной
обработки, которая присутствует в большинстве задач. Задачи, содержащие высокую
степень внутреннего параллелизма, могут быть хорошо адаптированы к системам
массового параллелизма. Реальные задачи и, тем более, пакеты задач содержат
целый ряд алгоритмов, имеющих различные уровни параллелизма.
Все это говорит о том,
что вместо попыток приспособить все типы алгоритмов к одной архитектуре, что
отражается на конфигурации архитектур и сопровождается не всегда корректными
сравнениями пиковой производительности, более продуктивным является
взаимодополнение архитектур в единой системе. Одним из первых примеров такой
системы является объединение векторной системы Cray Y-XM с системой Cray T3D.
Однако, это объединение с помощью высокоскоростного канала приводит к
необходимости разбиения задач на крупные блоки и к потерям времени и памяти на
обмен информацией.
Ситуация в данном случае
подобна той, которая существовала до появления векторных машин. Для решения
задач, содержащих большое число операций над векторами и матрицами,
использовались так называемые матричные процессоры, например, фирмы FSP,
которые подключались к универсальной машине с помощью канала ввода/вывода.
Интеграция скалярной и векторной обработки в одном процессоре наряду с
обеспечением высокой скорости работы синхронного конвейера обеспечила успех
векторных машин.
Следующим логическим
шагом является интеграция скалярной, векторной и параллельной обработки. Благодаря
этому, может быть достигнута высокая реальная производительность за счет
распределения отдельных частей программы по подсистемам с различной
архитектурой. Естественно, это распределение работы должно быть поддержано
аппаратно-программными средствами автоматизации программирования. Эти средства
должны содержать возможность интерактивного вмешательства программиста на этапе
анализа задачи и возможность моделирования или пробного запуска программы с
измерением параметров эффективности. Следует подчеркнуть, что формы
параллелизма в алгоритмах достаточно разнообразны, поэтому и их аппаратное
отражение может быть различным. К наиболее простым можно отнести системы с
одним потоком команд и множественными потоками данных, системы с множественными
потоками команд и данных, систолические системы.
Одним из многообещающих
подходов, обеспечивающих автоматическое распараллеливание, является принцип
потока данных, при котором последовательность или одновременность вычислений
определяется не командами, а готовностью операндов и наличием свободного
функционального арифметического устройства. Однако, и в этом случае степень
реального распараллеливания зависит от внутреннего параллелизма алгоритма и,
очевидно, нужны эффективные способы подготовки задач. Кроме того, для реализации
таких систем необходимо создание ассоциативной памяти для поиска готовых к
работе пар операндов и систем распределения вычислений по большому числу
функциональных устройств.
Аппаратная реализация
параллельных подсистем полностью зависит от выбранных микропроцессоров, БИС
памяти и других компонентов. В настоящее время по экономическим причинам
целесообразно использовать наиболее высокопроизводительные микропроцессоры,
разработанные для унипроцессорных машин.
Вместе с тем, существуют
подходы, связанные с применением специализированных микропроцессоров,
ориентированных на использование в параллельных системах. Типичным примером
является серия транспьютеров фирмы Inmos. Однако, из-за ограниченного рынка эта
серия по производительности резко отстала от универсальных микропроцессоров,
таких, как Alpha, Power PC, Pentium. Специализированные микропроцессоры смогут
быть конкурентноспособными только при условии сокращения расходов на
проектирование и освоение в производстве, что в большой степени зависит от производительности
инструментальных вычислительных средств, используемых в системах
автоматизированного проектирования.
В различных
вычислительных машинах использовались различные подходы, направленные на
достижение, в первую очередь, одной из следующих целей:
- максимальная арифметическая
производительность процессора;
- эффективность работы операционной
системы и удобство общения с ней для программиста;
- эффективность трансляции с языков
высокого уровня и исключение написания программ на автокоде;
- эффективность распараллеливания
алгоритмов для параллельных архитектур.
Однако, в любой машине
необходимо в той или иной форме решать все указанные задачи. Отметим, что
сначала этого пытались достичь с помощью одного или нескольких одинаковых
процессоров.
Дифференциация функций и
специализация отдельных подсистем начала развиваться с появления отдельных
подсистем и процессоров для обслуживания ввода/вывода, коммуникационных сетей,
внешней памяти и т.п.
В суперЭВМ кроме
основного процессора (машины) включались внешние машины. В различных системах
можно наблюдать элементы специализации в направлениях автономного выполнения
функций операционной системы, системы программирования и подготовки заданий.
Во-первых, эти
вспомогательные функции могут выполняться параллельно с основными вычислениями.
Во-вторых, для реализации не требуются многие из тех средств, которые
обеспечивают высокую производительность основного процессора, например,
возможность выполнения операций с плавающей запятой и векторных операций. В
дальнейшем, при интеграции скалярной, векторной и параллельной обработки в
рамках единой вычислительной подсистемы состав этих вспомогательных функций
должен быть дополнен функциями анализа программ с целью обеспечения требуемого
уровня параллелизма и распределения отдельных частей программы по различным
ветвям вычислительной подсистемы.
Появление суперЭВМ
сопровождалось повышением их общей мощности потребления (выше 100 кВт) и
увеличением плотности тепловых потоков на различных уровнях конструкции. Их
создание не в последнюю очередь оказалось возможным, благодаря использованию
эффективных жидкостных и фреоновых систем охлаждения. Является ли значительная
мощность существенным признаком суперЭВМ? Ответ на этот вопрос зависит от
того, что вкладывается в понятие суперЭВМ.
Если считать, что
суперЭВМ или, точнее, суперсистема - это система с наивысшей возможной
производительностью, то энергетический фактор остается одним из определяющих
эту производительность. По мере развития технологии мощность одного вентиля в
микропроцессорах уменьшается, но при повышении производительности процессора за
счет параллелизма общая мощность в ряде случаев растет. При объединении
большого числа микропроцессоров в системе с массовым параллелизмом интегральная
мощность и тепловыделение становятся соизмеримыми с аналогичными показателями
для векторно-конвейерных систем. Однако, иногда в рекламных целях параллельные
системы с небольшим числом процессоров сравниваются с суперкомпьютерами
предыдущего или более раннего поколений, чтобы показать их преимущества в
смысле простоты и удобства эксплуатации. Естественно, из такого некорректного
сравнения нельзя сделать вывод о целесообразности создания современных
суперсистем.
Основным стимулом
создания суперсистем являются потребности решения больших задач. В свою
очередь, исследования и разработки по суперсистемам стимулируют целый комплекс
фундаментальных и прикладных исследований, результаты которых используются в
дальнейшем в других областях. Прежде всего, это касается архитектуры и
схемотехники вычислительных машин, высокочастотных интегральных схем и средств
межсоединений, эффективных систем отвода тепла. Не менее важны результаты по
методам распараллеливания при выполнении отдельных операций и участков программ
на аппаратном уровне, методам построения параллельных алгоритмов, языков и
программных систем для эффективного решения больших задач.
В развитии вычислительных
средств можно выделить три основные проблемы:
- повышение производительности;
- повышение надежности;
- покрытие семантического разрыва.
Этапы развития
вычислительных средств принято различать по поколениям машин. Характеристика
поколения определяется конкретными показателями, отражающими достигнутый
уровень в решении трех перечисленных проблем. Поскольку подавляющий вклад в
развитие вычислительных средств всегда принадлежал технологическим решениям,
основополагающей характеристикой поколения машин считалась элементная база. И
действительно, переход на новую элементную базу хорошо коррелируется с новым
уровнем показателей производительности, надежности и сокращения семантического
разрыва.
В настоящее время
актуальным является переход к новым поколениям вычислительных средств. По
сложившейся традиции решающая роль отводится технологии производства элементной
базы. В то же время становится очевидным, что технологические решения утратили
монопольное положение. Так, например, в ближайшей перспективе заметно
возрастает значение проблемы покрытия семантического разрыва, что отражается в
необходимости создания высокосложных программных продуктов и требует
кардинального снижения трудоемкотси программирования. Эта проблема решается
преимущественно архитектурными средствами. Роль технологии здесь может быть
только косвенной: высокая степень интеграции создает условия для реализации
архитектурных решений.
В настоящее время одним
из доминируюших направлений развития суперЭВМ являются вычислительные системы c
MIMD-параллелизмом на основе матрицы микропроцессоров. Для создания подобных
вычислительных систем, состоящих из сотен и тысяч связанных процессоров,
потребовалось преодолеть ряд сложных проблем как в программном обеспечении
(языки Parallel Pascal, Modula-2, Ada), так и в аппаратных средствах
(эффективная коммутационная среда, высокоскоростные средства обмена, мощные
микропроцессоры). Элементная база современных выcокопроизводительных систем
характеризуется выcокой степенью интеграции (до 3,5 млн. транзисторов на
кристалле) и высокими тактовыми частотами (до 600 МГц).
В настоящее время все фирмы и
все университеты США, Западной Европы и Японии, разрабатывающие суперЭВМ, ведут
интенсивные исследования в области многопроцессорных суперЭВМ с массовым
параллелизмом, создают множество их типов, организуют их производство и
ускоренными темпами осваивают мировой рынок в этой области. Многопроцессорные
ЭВМ с массовым параллелизмом уже сейчас существенно опережают по
производительности традиционные суперЭВМ с векторно-конвейерной архитектурой.
Системы с массовым параллелизмом предъявляют меньшие требования к
микропроцессорам и элементной базе и имеют значительно меньшую стоимость при
любом уровне производительности, чем векторно-конвейерные суперЭВМ.
На
ежегодной конференции в Чепел-Хилл (Сев.Каролина) представлен проект фирмы IBM,
целью которого является создание гиперкубического параллельного процесора в
одном корпусе. Конструкция, названная Execube, имеет 8 16-разрядных
микропроцесоров, встроенных в кристалл 4Мбит динамического ЗУ (ДЗУ). При этом
степень интеграци составляет 5 млн. транзисторов. Микросхема изготовлена по
КМОП-технологии с тремя уровнями металлизации на заводе IBM Microelectronic
(Ясу, Япония). Execube представляет собой попытку повышения степени интеграции
процессора с памятью путем более эффективного доступа к информации ДЗУ. По
существу, память превращается в расширенные регистры процессоров.
Производительность микросхемы составляет 50 млн оп/с.
Фирма
CRAY Research обёявила о начале выпуска суперкопьютеров CRAY T3/E. Основная
характеристика, на которой акцентировали внимание разработчики -
масштабируемость. Минимальная конфигурация составляет 8 микропроцессоров,
максимальная - 2048. По сравнению с предыдущей моделью T3/D соотношение
цена/производительность снижена в 4 раза и составляет 60 долл/Мфлопс, чему
способствовало применение недорогих процессоров DEC Alpha EVC, изготовленных по
КМОП-технологии. Предполагаемая стоимость модели Т3/Е на основе 16 процессоров
с 1-Гбайт ЗУ составит 900 тыс. долларов, а цена наиболее мощной конфигурации
(1024 процессора, ЗУ 64 Гбайт) -39,7 млн. долларов при пиковой
производительности 600 Гфлопс.
Одним
из способов дальнейшего повышения производительности вычислительной системы
является объединение суперкомпьютеров в кластеры при помощи оптоволоконных
соединений. С этой целью компьютеры CRAY T3/E снабжены каналами ввода/вывода с
пропускной способностью 128 Гбайт/с. Потенциальные заказчики проявляют
повышенный интерес к новой разработке фирмы. Желание приобрести компьютер
изъявили такие организации как Pittsburgh Supercomputer Center, Mobile Oil,
Департамент по океанографии и атмосферным исследованиям США. При этом подписано
несколько контрактов на изготовление нескольких компьютеров 512-процессорной
конфигурации.
Среди
японских компаний следует выделить фирму Hitachi, которая выпустила
суперкомпьютер SR2201 с массовым параллелизмом, содержащий до 2048 процесоров.
В основе системы переработанная компанией процессорная архитектура RA-RISC от
фирмы Hewlett-Paccard. Псевдовекторный процессор функционирует под управлением
ОС HP-UX/MPP Mash 3.0. В компьютере, кроме того, использована система поддержки
параллельного режима работы Express, созданная корпорацией Parasoft и
получившая название ParallelWare. Производительность нового компьютера
составляет 600 Гфлопс.
4. КРАТКИЕ ХАРАКТЕРИСТИКИ НАИБОЛЕЕ
РАСПРОСТРАНЕННЫХ СУПЕРКОМПЬЮТЕРОВ
IBM RS/6000 SP
| Производитель |
International Business Machines (IBM), подразделение RS/6000. |
| Класс
архитектуры |
Масштабируемая
массивно-параллельная вычислительная система (MPP). |
| Узлы |
Узлы имеют
архитектуру рабочих станций RS/6000. Существуют несколько типов SP-узлов,
которые комплектуются различными процессорами: PowerPC 604e/332MHz,
POWER3/200 и 222 MHz (более ранние системы комплектовались процессорами
POWER2). High-узлы на базе POWER3 включают до 8 процессоров и до 16 GB
памяти. |
| Масштабируе-мость |
До 512 узлов.
Возможно совмещение узлов различых типов. Узлы устанавливаются в стойки (до
16 узлов в каждой). |
| Коммутатор |
Узлы связаны
между собой высокопроизводительных коммутатором (IBM high-performance
switch), который имеет многостадийную структуру и работает с коммутацией
пакетов. |
| Cистемное ПО |
OC AIX
(устанавливается на каждом узле), система пакетной обработки LoadLeveler,
параллельная файловая система GPFS, параллельная СУБД INFORMIX-OnLine XPS.
Параллельные приложения исполняются под управлением Parallel Operating
Environment (POE). |
|
Средства
программирова-ния
|
Оптимизированная
реализация интерфейса MPI, библиотеки параллельных математических подпрограмм
- ESSL, OSL. |
| Обзор |
Обзор
архитектуры суперкомпьютеров серии RS/6000 SP корпорации IBM. |
HP 9000 (Exemplar)
| Производитель |
Hewlett-Packard,
подразделение высокопроизводительных систем. |
| Класс |
Многопроцессорные
сервера с общей памятью (SMP). |
| Предшествен-ники |
SMP/NUMA-системы
Convex SPP-1200, SPP-1600, SPP-2000. |
| Модификации |
В настоящее время
доступны несколько "классов" систем семейства HP 9000: сервера
начального уровня (D, K-class), среднего уровня (N-class) и наиболее мощные
системы (V-class). |
| Процессоры |
64-битные
процессоры c архитектурой PA-RISC 2.0 (PA-8200, PA-8500). |
| Число процессоров |
N-class - до 8
процессоров. V-class - до 32 процессоров. В дальнейшем ожидается увеличение
числа процессоров до 64, а затем до 128. |
| Масштабируе-мость |
SCA-конфигурации
(Scalable Computing Architecture) - до 4 узлов V-class, т.е. до 128 процессоров. |
| Системное ПО |
Устанавливается
операционная система HP-UX (совместима на уровне двоичного кода с ОС SPP-UX
компьютеров Convex SPP). |
| Средства
программирова-ния |
HP MPI -
реализация MPI 1.2, оптимизированная к архитектуре Exemplar.
Распараллеливающие компиляторы Fortran/C, математическая библиотека HP MLIB.
CXperf - с редство анализа производительности программ. |
| Обзор |
Обзор
архитектуры серверов HP 9000 класса V корпорации Hewlett-Packard |
Cray
T3E
| Производитель |
Cray Inc. |
| Класс архитектуры |
Масштабируемая
массивно-параллельная система, состоит из процессорных элементов (PE). |
| Предшествен-ники |
Cray T3D |
| Модификации |
T3E-900,
T3E-1200, T3E-1350 |
| Процессорный
элемент |
PE состоит из
процессора, блока памяти и устройства сопряжения с сетью. Используются
процессоры Alpha 21164 (EV5) с тактовой частотой 450 MHz (T3E-900), 600 MHz
(T3E-1200), 675 MHz (T3E-1350) пиковая производительность которых составляет
900, 1200, 1350 MFLOP/sec соответственно. Процессорный элемент располагает своей
локальной памятью (DRAM) объемом от 256MB до 2GB. |
| Число
процессоров |
Системы T3E
масштабируются до 2048 PE. |
| Коммутатор |
Процессорные
элементы связаны высокопроизводительной сетью GigaRing с топологией
трехмерного тора и двунаправленными каналами. Скорость обменов по сети
достигает 500MB/sec в каждом направлении. |
| Системное ПО |
Используется
операционная система UNICOS/mk. |
| Средства
программирова-ния |
Поддерживается
явное параллельное программирование c помощью пакета Message Passing Toolkit
(MPT) - реализации интерфейсов передачи сообщений MPI, MPI-2 и PVM,
библиотека Shmem. Для Фортран-программ возможно также неявное
распараллеливание в моделях CRAFT и HPF. Среда разработки включает также
набор визуальных средств для анализа и отладки параллельных программ. |
Cray T90
| Производитель |
Cray Inc.,
Cray Research. |
| Класс
архитектуры |
Многопроцессорная
векторная система (несколько векторных процессоров работают на общей памяти). |
| Предшествен-ники |
CRAY Y-MP C90, CRAY X-MP. |
| Модели |
Серия T90
включает модели T94, T916 и T932. |
| Процессор |
Системы серии
T90 базируются на векторно-конвейерном процессоре Cray Research с пиковой
производительностью 2GFlop/s. |
| Число
процессоров |
Система T932
может включать до 32 векторных процессоров (до 4-х в модели T94, до 16 модели
T916), обеспечивая пиковую производительность более 60GFlop/s. |
| Масштабируе-мость |
Возможно
объединение нескольких T90 в MPP-системы. |
| Память |
Система T932
содержит от 1GB до 8GB (до 1 GB в модели T94 и до 4GB в модели T916) оперативной
памяти и обеспечивает скорость обменов с памятью до 800MB/sec. |
| Системное ПО |
Используется
операционная система UNICOS. |
Cray SV1
| Производитель |
Cray Inc. |
| Класс
архитектуры |
Масштабируемый
векторный суперкомпьютер. |
| Процессор |
Используются
8-конвейерные векторные процессоры MSP (Multi-Streaming Processor) с пиковой
производительностью 4.8 GFLOP/sec; каждый MSP может быть подразделен на 4
стандартных 2-конвейерных процессора с пиковой производительностью 1.2
GFLOP/sec. Тактовая частота процессоров - 250MHz. |
| Число
процессоров |
Процессоры
объединяются в SMP-узлы, каждый из которых может содержать 6 MSP и 8
стандартных процессоров. Система (кластер) может содержать до 32 таких узлов. |
| Память |
SMP-узел может
содержать от 2 до 16GB памяти. Система может содержать до 1TB памяти. Вся
память глобально адресуема (архитектура DSM). |
| Системное ПО |
Используется
операционная система UNICOS. |
| Средства
программирова-ния |
Поставляется
векторизующий и распараллеливающий компилятор CF90. Поддерживается также
явное параллельное программирование с использованием интерфейсов MPI, OpenMP
или Shmem. |
Cray X1
| Производитель |
Cray Inc. |
| Класс
архитектуры |
Масштабируемый
векторный суперкомпьютер. |
| Процессор |
Используются
16-конвейерные векторные процессоры с пиковой производительностью 12.8
GFLOP/sec. Тактовая частота процессоров - 800MHz. |
| Число
процессоров |
В максимальной
конфигурации - до 4096. |
| Память |
Каждый
процессор может содержать до 16GB памяти. В максимальной конфигурации система
может содержать до 64TB памяти. Вся память глобально адресуема (архитектура
DSM). Максимальная скорость обмена с оперативной памятью составляет 34.1
Гбайт/сек. на процессор, скорость обмена с кэш-памятью 76.8 Гбайт/сек. на
процессор. |
| Системное ПО |
Используется
операционная система UNICOS/mp. |
| Средства
программирова-ния |
Реализованы
компиляторы с языков Фортран и Си++, включающие возможности автоматической
векторизации и распараллеливания, специальные оптимизированные библиотеки,
интерактивный отладчик и средства для анализа производительности. Приложения
могут писаться с использованием MPI, OpenMP, Co-array Fortran и Unified
Parallel C (UPC). |
Cray XT3
| Производитель |
Cray Inc. |
| Класс
архитектуры |
Массивно-параллельный
суперкомпьютер. |
| Процессор |
Используются
процессоры AMD Opteron. |
| Число
процессоров |
В максимальной
конфигурации - до 30508. |
| Память |
Каждый
процессор может содержать от 1 до 8 Гбайт оперативной памяти. В максимальной
конфигурации система может содержать до 239 Тбайт памяти. |
| Системное ПО |
Используется
операционная система UNICOS/lc. |
| Средства
программирова-ния |
На компьютере
устанавливаются компиляторы Fortran 77, 90, 95, C/C++, коммуникационные
библиотеки MPI (с поддержкой стандарта MPI 2.0) и SHMEM, а также
оптимизированные версии библиотек BLAS, FFTs, LAPACK, ScaLAPACK и SuperLU.
Для анализа производительности системы устанавливается система Cray
Apprentice2 performance analysis tools. |
SGI Origin2000
| Производитель |
Silicon
Graphics |
| Класс
архитектуры |
Модульная
система с общей памятью (cc-NUMA). |
| Процессор |
64-разрядные
RISC-процессоры MIPS R10000, R12000/300MHz |
| Модуль |
Основной
компонент системы - модуль Origin, включающий от 2 до 8 процессоров MIPS
R10000 и до 16GB оперативной памяти. |
| Масштабируе-мость |
Поставляются
системы Origin2000, содержащие до 256 процессоров (т.е. до 512 модулей). Вся
память системы (до 256GB) глобально адресуема, аппаратно поддерживается
когерентность кэшей. |
| Коммутатор |
Модули системы
соединены с помощью сети CrayLink, построенной на маршрутизаторах MetaRouter. |
| Системное ПО |
Используется
операционная система SGI IRIX. |
| Средства
программирова-ния |
Поставляется
распараллеливающий компилятор Cray Fortran 90. Поддерживается стандарт
OpenMP. |
SGI Altix3000
| Производитель |
Silicon
Graphics |
| Класс
архитектуры |
Модульная
система с общей памятью (cc-NUMA). |
| Процессор |
Intel Itanium II 1.3GHz/1.5GHz |
| Модули |
Вся система
строится из модулей (вычислительных, коммутационных, проч.) Вычислительный
компонент системы - модуль C-brick, состоящий из 2-х блоков, включающий 4
процессора (по 2 на блок), 4 слота памяти по 8DIMM (от 4 до 16Gb на C-brick). |
| Масштабируе-мость |
Поставляются
системы Origin2000, содержащие до 256 процессоров (т.е. до 512 модулей). Вся
память системы (до 256GB) глобально адресуема, аппаратно поддерживается
когерентность кэшей. |
| Коммутатор |
Модули системы
соединены с помощью сети NUMAlink, построенной на собственных маршрутизаторах
R-bricks. |
| Системное ПО |
Используется
доработанная ("открытые" доработки) операционная система Linux. |
Onyx2
InfiniteReality2
| Производитель |
Silicon
Graphics |
| Класс
архитектуры |
Многопроцессорная
система визуализации; по аппаратной архитектуре очень похожа на Origin2000. |
| Число
процессоров |
Система может
включать до 128 процессоров MIPS R10000. |
| Визуализация |
Графические
возможности системы обеспечивают специальные устройства трех типов:
геометрические (векторные) процессоры, растровые процессоры, генераторы
аналоговых сигналов. Система может быть оборудована 16 независимыми каналами
графического вывода (visualization pipelines). На аппаратном уровне
поддерживается графический интерфейс OpenGL. |
| Системное ПО |
Используется
операционная система SGI IRIX. |
Sun HPC 10000 (StarFire)
| Производитель |
Sun Microsystems, серия Sun HPC. |
| Класс
архитектуры |
Многопроцессорный
SMP-сервер. |
| Процессор |
UltraSPARC
II/336MHz |
| Число
процессоров |
Система
StarFire объединяет от 16 до 64 процессоров. |
| Память |
Система
включает от 2GB до 64GB памяти. |
| Системное ПО |
ОС Solaris, ПО
распределения ресурсов Load Sharing Facility (LSF). |
| Средства
разработки |
Поставляется
пакет поддержки параллельных приложений Sun HPC 2.0, включающий такие
средства как HPF, MPI, PVM, PFS (параллельная файловая система), Prism
(визуальная среда разработки), S3L (библиотека математических подпрограмм), и
др. |
Sun Fire 15K
| Производитель |
Sun
Microsystems. |
| Класс
архитектуры |
Многопроцессорный
SMP-сервер. |
| Процессор |
UltraSPARC
III/900MHz |
| Число
процессоров |
Система Sun
Fire 15K объединяет до 106 процессоров. |
| Память |
Система
включает до 576GB памяти. |
| Системное ПО |
ОС Solaris 8. |
NEC SX-5
| Производитель |
NEC, серия SX. |
| Класс
архитектуры |
Параллельный
векторный суперкомпьютер (PVP). |
| Предшествен-ники |
NEC SX-4. |
| Узел |
Каждый узел
системы является векторно-конвейерным SMP-суперкомпьютером, объединяющим до
16 индивидуальных векторных процессоров (каждый с пиковой векторной
производительностью 8 Gflop/s и скалярной производительностью 500 MFlop/s). |
| Память |
Объем памяти
каждого узла - до 128GB, производительность обменов с памятью достигает
1TB/sec. |
| Масштабируе-мость |
Система может
включать до 32 узлов, обеспечивая совокупную пиковую производительность до 4
TFlop/s. |
| Коммутатор |
Для связи
узлов используется высокоскоростной коммутатор (IXS Internode Crossbar
Switch). |
| Системное ПО |
Используется
операционная система SUPER-UX. |
| Средства
программирова-ния |
поставляются
компилятор языка HPF, реализация интерфейса MPI, компиляторы Фортран 77/90 с
автоматической векторизацией и поддержкой OpenMP 1.1, а также интегрированная
среда разработки и оптимизации PSUITE. |
NEC SX-6
| Производитель |
NEC, серия SX. |
| Класс
архитектуры |
Параллельный
векторный суперкомпьютер (PVP). |
| Предшествен-ники |
NEC SX-5. |
| Узел |
Каждый узел
системы является векторно-конвейерным SMP-суперкомпьютером, объединяющим от 2
до 8 индивидуальных векторных процессоров (каждый с пиковой векторной
производительностью 8 Gflop/s и скалярной производительностью 500 MFlop/s). |
| Память |
Объем памяти
каждого узла - до 64GB, производительность обменов с памятью достигает
1TB/sec. |
| Масштабируе-мость |
Система может
включать до 128 узлов, обеспечивая совокупную пиковую производительность до 8
TFlop/s. |
| Коммутатор |
Для связи
узлов используется высокоскоростной коммутатор (IXS Internode Crossbar
Switch). |
| Системное ПО |
Используется
операционная система SUPER-UX с улучшенной поддержкой SSI (Single System
Image). |
| Средства
программирова-ния |
поставляются
компилятор языка HPF 2.0, реализация интерфейса MPI, компиляторы Фортран
77/90 с автоматической векторизацией, интегрированная среда разработки и
оптимизации PSUITE, поддерживается OpenMP 1.1 (в конце 2002 года
предполагается поддержка OpenMP 2.0). |
Fujitsu VPP
| Производитель |
Fujitsu |
| Класс
архитектуры |
Параллельный
векторный суперкомпьютер (PVP). |
| Модификации |
VPP300,
VPP700, VPP5000 |
| Процессорный
элемент |
Каждый
процессорный элемент (PE) системы VPP700E состоит скалярного устройства (SU),
векторного устройства (VU), блока памяти и устройства сопряжения.
Для VPP700: VU состоит из 7 конвейеров и обеспечивает пиковую
производительность до 2.4 GFLOP/sec. Объем памяти - до 2GB.
Для VPP5000: VU состоит из 4 конвейеров, пиковая производительность - 9.6
GFLOP/sec. Объем памяти - до 16GB.
|
| Масштабируе-мость |
Для VPP700:
cистема может включать от 8 до 256 PE, суммарная пиковая производительность
до 14.4 GFLOP/sec
Для VPP5000: до 512 PE, суммарная пиковая производительность до 4.9
TFLOP/sec.
|
| Коммутатор |
Процессорные
элементы связаны коммутатором (crossbar network), который производит
двухсторонние обмены, не прерывая вычислений. Пропускная способность каналов
коммутатора: для VPP700 - 615MB/sec, для VPP5000 - 1.6GB/sec. |
| Системное ПО |
Используется
операционная система UXP/V, основанная на UNIX System VR4. |
| Средства
программирова-ния |
Среди средств
разработки поставляются: распараллеливающий и векторизующий компилятор
Fortran90/VPP, оптимизированная для VPP библиотека математических подпрограмм
SSLII/VPP, библиотеки передачи сообшений MPI-2 и PVM 3.3. |
Fujitsu PrimePower 2000
| Производитель |
Fujitsu |
| Класс
архитектуры |
Многопроцессорные
сервера с общей памятью (SMP). |
| Назначение |
Сервер
масштаба предприятия(Enterprise Server) |
| Виртуальные
домены |
до 15 |
| Процессоры |
от 8 до 128
SPARC64-V, тактовая частота 675/788MHz, L1 кэш 128/128KB, L2 кэш 8MB |
| Пропускная
способность шины |
57.6 GB/sec |
| Память |
2GB - 512GB
ECC SDRAM |
| Дисковые
накопители |
внутренние
8,736GB, внешние 414 TB, поддерживается горячая замена |
| Слоты ввода-вывода |
PCI 12-192, из
них 6-96 64bit/66MHz/33MHz и 6-96 64bit/33MHz, встроенный SCSI контроллер
UltraWide |
| Операционная
система |
Solaris 2.6,
7, 8, 9 |
| Минимальная
конфигурация |
8*675MHz CPU,
4 GB память, 18.2 GB диски, стоимость 1004730 долларов США |
Fujitsu PrimePower 2500
| Производитель |
Fujitsu |
| Класс
архитектуры |
Многопроцессорные
сервера с общей памятью (SMP). |
| Назначение |
Сервер
масштаба предприятия(Enterprise Server) |
| Partitions
(разделы) |
до 15
независимых физических, до 15 дополнительных |
| Процессоры |
от 8 до 128
SPARC64-V, тактовая частота 1.35GHz, L1 кэш 256KB, L2 кэш 8MB |
| Пропускная
способность шины |
133 GB/sec |
| Память |
2GB - 512GB
ECC SDRAM |
| Дисковые
накопители |
внутренние
9,34TB (32 PCI/Disk box), внешние 147GB * 4 диска на PCI/Disk box,
поддерживается горячая замена |
| Слоты
ввода-вывода |
PCI до 320,
встроенный SCSI контроллер UltraWide |
| Операционная
система |
Solaris 8, 9 |
AlphaServer
| Производитель |
Compaq
(Digital). |
| Класс
архитектуры. |
AlphaServer
GS/ES - высокопроизводительный SMP-сервер, AlphaServer SC -
массивно-параллельная система, AlphaServer HPC - кластерные системы. |
| Модификации |
GS320, GS160,
HPC320, HPC160, GS140, GS60, ES40, DS20 и др. |
| Процессор |
Alpha 21264,
21264A (тактовая частота до 731 MHz в новых моделях) |
| Число
процессоров |
до 32 (модель
GS320) |
| Память |
до 256 GB
(модель GS320) |
| Масштабируе-мость |
Системы HPC320
включают до 4-х узлов AlphaServer ES40, т.е. до 16 процессоров. Системы
AlphaServer SC могут объединять до 128 узлов AlphaServer ES40, т.е. до 512
процессоров. Также Compaq предлагает разнообразные кластерные решения на базе
своих серверов. |
| Системное ПО |
На платформе
AlphaServer поддерживаются операционные системы Tru64 UNIX (это новое имя
Digital UNIX), OpenVMS и Linux. Поставляется ПО кластеризации TruCluster
Software. |
| Средства
программирова-ния |
Поддерживается
параллельное программирование в стандартах OpenMP и MPI. |
5. ДЕСЯТКА САМЫХ МОЩНЫХ КОМПЬЮТЕРОВ
Данный список был взят из
Top500 на ноябрь 2004 года. В списке
представлены следующие данные по каждому компьютеру:
- Rank – порядковый номер в списке
Top500;
- Site – организация, в которой
установлен компьютер;
- Country – страна - местоположение
системы;
- Year – год инсталляции или последнего
серьезного обновления системы;
- Computer – название (тип) компьютера,
указанное поставщиком;
- Processors – количество процессоров;
- Manufacturer – производитель или
поставщик компьютера;
- Computer Family – семейство
компьютеров;
- Model – модель компьютера или
вычислительного узла;
- Installation Type – вид установки
(исследовательская, академическая, правительственная, промышленная, закрытая);
- Installation Area – область
применения (погода, геофизика);
- Nmax – размер задачи, необходимый для
достижения Rmax;
- Nhalf – размер задачи, необходимый
для достижения половины Rmax;
- Rmax – максимальная полученная
производительность по LINPACK;
- Rpeak – теоретическая пиковая
производительность.
Таблица 5.1 – десятка
самых мощных компьютеров
| Rank |
Site Country/Year |
Computer
Processors Manufacturer |
Computer
Family Model |
Inst. type
Installation Area
|
Rmax Rpeak |
Nmax nhalf |
| 1 |
IBM/DOE United
States/2004 |
BlueGene/L beta-System BlueGene/L DD2 beta-System (0.7 GHz PowerPC
440) / 32768
IBM
|
IBM BlueGene/L BlueGene/L |
Research |
70720 91750 |
933887 |
| 2 |
NASA/Ames Research Center/NAS
United States/2004
|
Columbia SGI Altix 1.5 GHz, Voltaire Infiniband / 10160 SGI |
SGI Altix
SGI Altix 1.5 GHz
|
Research |
51870 60960 |
1.29024e+06 |
| 3 |
The Earth Simulator Center
Japan/2002
|
Earth-Simulator
/
5120 NEC
|
NEC Vector
SX6
|
Research |
35860
40960
|
1.0752e+06
266240
|
| 4 |
Barcelona
Supercomputer Center
Spain/2004
|
MareNostrum
eServer BladeCenter JS20 (PowerPC970 2.2 GHz), Myrinet / 3564
IBM
|
IBM Cluster
JS20 CLuster, Myrinet
|
Academic |
20530
31363
|
812592 |
| 5 |
Lawrence Livermore National Laboratory
United States/2004
|
Thunder
Intel Itanium2 Tiger4 1.4GHz - Quadrics / 4096
California Digital Corporation
|
NOW - Intel Itanium
Itanium2 Tiger4 Cluster - Quadrics
|
Research |
19940
22938
|
975000
110000
|
| 6 |
Los Alamos National Laboratory
United States/2002
|
ASCI Q
ASCI Q - AlphaServer SC45, 1.25 GHz / 8192
HP
|
HP AlphaServer
SC Alpha-Server-Cluster
|
Research |
13880
20480
|
633000
225000
|
| 7 |
Virginia Tech
United States/2004
|
System X
1100 Dual 2.3 GHz Apple XServe/Mellanox Infiniband 4X/Cisco GigE / 2200
Self-made
|
NOW - PowerPC
XServe Cluster
|
Academic |
12250
20240
|
620000 |
| 8 |
IBM -
Rochester
United States/2004
|
BlueGene/L DD1 Prototype (0.5GHz PowerPC 440 w/Custom) / 8192
IBM/ LLNL
|
IBM BlueGene/L
BlueGene/L
|
Vendor |
11680
16384
|
331775 |
| 9 |
Naval Oceanographic Office (NAVOCEANO)
United States/2004
|
eServer pSeries 655 (1.7 GHz Power4+) / 2944
IBM
|
IBM SP
SP Power4+, Federation
|
Research |
10310
20019.2
|
|
| 10 |
NCSA
United States/2003
|
Tungsten
PowerEdge 1750, P4 Xeon 3.06 GHz, Myrinet / 2500
Dell
|
Dell Cluster
PowerEdge 1750, Myrinet
|
Academic |
9819
15300
|
630000 |
ЗАКЛЮЧЕНИЕ
Бурное развитие индустрии
суперЭВМ послужило откликом на необходимость человечества в машинах,
моделирующих процессы в реальном времени и выполняющих ряд других сложных
задач. СуперЭВМ всегда являлись воплощением новейших научно-технических
достижений и задавали темп и тенденции развития других видов машин. Пока рост
производительности суперЭВМ отвечает увеличению сложности предстающих перед
человеком проблем. Однако, можно заметить, что современная концепция развития вычислительных
средств направлена, в основном, на количественное улучшение характеристик. Процесс
разработки в некоторой степени можно назвать “выжиманием” максимума из уже
созданного. Это подразумевает, что современный этап развития вычислительной
техники уже вошел в состояние относительной стабильности, и каких-либо качественных
измененний в пределах современной концепции едва ли придется ожидать. Очевидно,
что за этапом стабильности, который может продлиться неопределенное время (но
явно небольшое в масштабе постоянно ускоряющегося темпа жизни), последует “смутный
период”, когда уровень возможностей суперЭВМ уже не сможет идти в ногу с
потребностями человечества. Эта проблема породит необходимость в переходе на
качественно новый уровень вычислительной техники.
Еще одним большим
вопросительным знаком в развитии суперЭВМ остается проблема практического
отсутствия достаточно чётких и понятных стратегических направлений достижения
очевидной цели – создание искусственной интеллектуальной системы, максимально
соответствующей естественной, то есть Человеку. Внося существенную
неопределённость в саму стратегию развития суперЭВМ, эта проблема порождает
ситуацию, когда постоянно расширяющаяся в последнее время мозаика феноменальных
научных достижений в области создания ЭВМ, лишённая чёткой связующей системы
взглядов на описание и моделирование интеллектуальных систем, не только не
уменьшает эту неопределённость, но и в ряде случаев создаёт предпосылки к е
увеличению.
Поэтому очень важным
шагом, который следует сделать сейчас, является конкретизация стратегии
дальнейшего развития суперЭВМ.
СПИСОК
ИСТОЧНИКОВ
1.
Информационно-аналитический центр
по параллельным вычислениям
|



