Информатика программирование : Реферат: История систем распознавания образов
Реферат: История систем распознавания образов
Содержание
Введение
1. Что такое распознавание образов?
2. Определения
3. Методы распознавания образов
4. История распознавания образов.
5. Общая характеристика задач
распознавания образов и их типы
Заключение
Список литературы
Введение
С задачей распознавания образов живые системы, в том
числе и человек, сталкиваются постоянно с момента своего появления. В
частности, информация, поступающая с органов чувств, обрабатывается мозгом,
который в свою очередь сортирует информацию, обеспечивает принятие решения, а
далее с помощью электрохимических импульсов передает необходимый сигнал далее,
например, органам движения, которые реализуют необходимые действия. Затем
происходит изменение окружающей обстановки, и вышеуказанные явления происходят
заново. И если разобраться, то каждый этап сопровождается распознаванием.
С развитием вычислительной техники стало возможным
решить ряд задач, возникающих в процессе жизнедеятельности, облегчить,
ускорить, повысить качество результата. К примеру, работа различных систем
жизнеобеспечения, взаимодействие человека с компьютером, появление
роботизированных систем и др. Тем не менее, отметим, что обеспечить
удовлетворительный результат в некоторых задачах (распознавание
быстродвижущихся подобных объектов, рукописного текста) в настоящее время не
удается.
Цель работы: изучить
историю систем распознавания образов.
Задачи:
- указать качественные изменения произошедшие в
области распознавания образов как теоретические, так и технические, с указанием
причин;
- обсудить методы и принципы, применяемые в
вычислительной технике;
- привести примеры перспектив, которые ожидаются в
ближайшем будущем.
1. Что
такое распознавание образов?
Первые
исследования с вычислительной техникой в основном следовали классической схеме
математического моделирования - математическая модель, алгоритм и расчет.
Таковыми были задачи моделирования процессов происходящих при взрывах атомных
бомб, расчета баллистических траекторий, экономических и прочих приложений.
Однако помимо классических идей этого ряда возникали и методы основанные на
совершенно иной природе, и как показывала практика решения некоторых задач, они
зачастую давали лучший результат нежели решения, основанные на переусложненных
математических моделях. Их идея заключалась в отказе от стремления создать
исчерпывающую математическую модель изучаемого объекта (причем зачастую
адекватные модели было практически невозможно построить), а вместо этого
удовлетвориться ответом лишь на конкретные интересующие нас вопросы, причем эти
ответы искать из общих для широкого класса задач соображений. К исследованиям
такого рода относились распознавание зрительных образов, прогнозирование
урожайности, уровня рек, задача различения нефтеносных и водоносных пластов по
косвенным геофизическим данным и т. д. Конкретный ответ в этих задачах
требовался в довольно простой форме, как например, принадлежность объекта
одному из заранее фиксированных классов. А исходные данные этих задач, как
правило, задавались в виде обрывочных сведений об изучаемых объектах, например
в виде набора заранее расклассифицированных объектов. С математической точки зрения
это означает, что распознавание образов (а так и был назван в нашей стране этот
класс задач) представляет собой далеко идущее обобщение идеи экстраполяции
функции.
Важность
такой постановки для технических наук не вызывает никаких сомнений и уже это само
по себе оправдывает многочисленные исследования в этой области. Однако задача
распознавания образов имеет и более широкий аспект для естествознания (впрочем,
было бы странно если нечто столь важное для искусственных кибернетических
систем не u1080 имело бы значения для естественных). В контекст данной науки
органично вошли и поставленные еще древними философами вопросы о природе нашего
познания, нашей способности распознавать образы, закономерности, ситуации
окружающего мира. В действительности, можно практически не сомневаться в том,
что механизмы распознавания простейших образов, типа образов приближающегося
опасного хищника или еды, сформировались значительно ранее, чем возник
элементарный язык и формально-логический аппарат. И не вызывает никаких сомнений,
что такие механизмы достаточно развиты и у высших животных, которым так же в
жизнедеятельности крайне необходима способность различения достаточно сложной
системы знаков природы. Таким образом, в природе мы видим, что феномен мышления
и сознания явно базируется на способностях к распознаванию образов и дальнейший
прогресс науки об интеллекте непосредственно связан с глубиной понимания
фундаментальных законов распознавания. Понимая тот факт, что вышеперечисленные
вопросы выходят далеко за рамки стандартного определения распознавания образов (в
англоязычной литературе более распространен термин supervised learning ),
необходимо так же понимать, что они имеют глубокие связи с этим относительно
узким(но все еще далеко неисчерпанным) направлением [9, c. 53].
Уже
сейчас распознавание образов плотно вошло в повседневную жизнь и является одним
из самых насущных знаний современного инженера. В медицине распознавание
образов помогает врачам ставить более точные диагнозы, на заводах оно
используется для прогноза брака в партиях товаров. Системы биометрической
идентификации личности в качестве своего алгоритмического ядра так же основаны
на результатах этой дисциплины. Дальнейшее развитие искусственного интеллекта,
в частности проектирование компьютеров пятого поколения, способных к более
непосредственному общению с человеком на естественных для людей языках и
посредством речи, немыслимы без распознавания. Здесь рукой подать и до
робототехники, искусственных систем управления, содержащих в качестве жизненно
важных подсистем системы распознавания .
Именно
поэтому к развитию распознавания образов с самого начала было приковано немало
внимания со стороны специалистов самого различного профиля - кибернетиков,
нейрофизиологов, психологов, математиков, экономистов и т.д. Во многом именно
по этой причине современное распознавание образов само питается идеями этих
дисциплин. Не претендуя на полноту (а на нее в небольшом эссе претендовать
невозможно) опишем историю распознавания образов, ключевые идеи [5, c. 107].
2. Определения
Прежде, чем приступить к основным
методам распознавания образов, приведем несколько необходимых определений.
Распознавание образов (объектов,
сигналов, ситуаций, явлений или процессов) - задача идентификации объекта или
определения каких-либо его свойств по его изображению (оптическое
распознавание) или аудиозаписи (акустическое распознавание) и другим
характеристикам.
Одним из базовых является не имеющее
конкретной формулировки понятие множества. В компьютере множество представляется
набором неповторяющихся однотипных элементов. Слово "неповторяющихся"
означает, что какой-то элемент в множестве либо есть, либо его там нет.
Универсальное множество включает все возможные для решаемой задачи элементы,
пустое не содержит ни одного.
Образ -
классификационная группировка в системе классификации, объединяющая
(выделяющая) определенную группу объектов по некоторому признаку. Образы
обладают характерным свойством, проявляющимся в том, что ознакомление с
конечным числом явлений из одного и того же множества дает возможность узнавать
сколь угодно большое число его представителей. Образы обладают характерными
объективными свойствами в том смысле, что разные люди, обучающиеся на различном
материале наблюдений, большей частью одинаково и независимо друг от друга
классифицируют одни и те же объекты. В классической постановке задачи
распознавания универсальное множество разбивается на части-образы. Каждое
отображение какого-либо объекта на воспринимающие органы распознающей системы,
независимо от его положения относительно этих органов, принято называть
изображением объекта, а множества таких изображений, объединенные какими-либо
общими свойствами, представляют собой образы.
Методика отнесения элемента к
какому-либо образу называется решающим правилом. Еще одно важное понятие -
метрика, способ определения расстояния между элементами универсального
множества. Чем меньше это расстояние, тем более похожими являются объекты
(символы, звуки и др.) - то, что мы распознаем. Обычно элементы задаются в виде
набора чисел, а метрика - в виде функции. От выбора представления образов и
реализации метрики зависит эффективность программы, один алгоритм распознавания
с разными метриками будет ошибаться с разной частотой.
Обучением обычно называют процесс выработки
в некоторой системе той или иной реакции на группы внешних идентичных сигналов
путем многократного воздействия на систему внешней корректировки. Такую внешнюю
корректировку в обучении принято называть "поощрениями" и
"наказаниями". Механизм генерации этой корректировки практически
полностью определяет алгоритм обучения. Самообучение отличается от обучения
тем, что здесь дополнительная информация о верности реакции системе не
сообщается.
Адаптация -
это процесс изменения параметров и структуры системы, а возможно - и
управляющих воздействий, на основе текущей информации с целью достижения
определенного состояния системы при начальной неопределенности и изменяющихся
условиях работы.
Обучение -
это процесс, в результате которого система постепенно приобретает способность
отвечать нужными реакциями на определенные совокупности внешних воздействий, а
адаптация - это подстройка параметров и структуры системы с целью достижения
требуемого качества управления в условиях непрерывных изменений внешних условий.
Примеры задач распознавания образов: - Распознавание
букв;
- Распознавание штрих-кодов;
- Распознавание автомобильных номеров;
-Распознавание лиц и других
биометрических данных;
- Распознавание речи [7, c. 26].
3. Методы
распознавания образов
В целом, можно выделить три метода
распознавания образов: Метод перебора. В этом случае производится сравнение с
базой данных, где для каждого вида объектов представлены всевозможные
модификации отображения. Например, для оптического распознавания образов можно
применить метод перебора вида объекта под различными углами, масштабами,
смещениями, деформациями и т. д. Для букв нужно перебирать шрифт, свойства
шрифта и т. д. В случае распознавания звуковых образов, соответственно,
происходит сравнение с некоторыми известными шаблонами (например, слово,
произнесенное несколькими людьми).
Второй подход - производится более
глубокий анализ характеристик образа. В случае оптического распознавания это
может быть определение различных геометрических характеристик. Звуковой образец
в этом случае подвергается частотному, амплитудному анализу и т. д.
Следующий метод - использование
искусственных нейронных сетей (ИНС). Этот метод требует либо большого
количества примеров задачи распознавания при обучении, либо специальной
структуры нейронной сети, учитывающей специфику данной задачи. Тем не менее,
его отличает более высокая эффективность и производительность. Подробно
нейронные сети мы рассматривали в "КИ" N 15, 16, 17 за 2005 г [9, c. 84].
4. История распознавания образов
Рассмотрим
кратко математический формализм распознавания образов. Объект в распознавании
образов описывается совокупностью основных характеристик (признаков, свойств).
Основные характеристики могут иметь различную природу: они могут браться из
упорядоченного множества типа вещественной прямой, либо из дискретного
множества (которое, впрочем, так же может быть наделено структурой). Такое
понимание объекта согласуется как потребностью практических приложений распознавания
образов, так и с нашим пониманием механизма восприятия объекта человеком.
Действительно, мы полагаем, что при наблюдении (измерении) объекта человеком,
сведения о нем поступают по конечному числу сенсоров (анализируемых каналов) в
мозг, и каждому сенсору можно сопоставить соответствующую характеристику
объекта. Помимо признаков, соответствующих нашим измерениям объекта, существует
так же выделенный признак, либо группа признаков, которые мы называем
классифицирующими признаками, и в выяснении их значений при заданном векторе Х
и состоит задача, которую выполняют естественные и искусственные распознающие
системы.
Понятно,
что для того, чтобы установить значения этих признаков, необходимо иметь
информацию о том, как связаны известные признаки с классифицирующими.
Информация об этой связи задается в форме прецедентов, то есть множества
описаний объектов с известными значениями классифицирующих признаков. И по этой
прецедентной информации и требуется построить решающее правило, которое будет
ставить произвольному описанию объекта значения его классифицирующих признаков.
Такое
понимание задачи распознавания образов утвердилось в науке начиная с 50-х годов
прошлого века. И тогда же было замечено что такая постановка вовсе не является
новой. С подобной формулировкой сталкивались и уже существовали вполне не плохо
зарекомендовавшие себя методы статистического анализа данных, которые активно
использовались для многих практических задач, таких как например, техническая
диагностика. Поэтому первые шаги распознавания образов прошли под знаком
статистического подхода, который и диктовал основную проблематику [8, c. 176].
Статистический
подход основывается на идее, что исходное пространство объектов представляет
собой вероятностное пространство, а признаки (характеристики) объектов являют
собой случайные величины заданные на нем. Тогда задача исследователя данных
состояла в том, чтобы из некоторых соображений выдвинуть статистическую
гипотезу о распределении признаков, а точнее о зависимости классифицирующих
признаков от остальных. Статистическая гипотеза, как правило, представляла
собой параметрически заданное множество функций распределения признаков.
Типичной и классической статистической гипотезой является гипотеза о
нормальности этого распределения (разновидностей таких гипотез статистики
придумали великое множество). После формулировки гипотезы оставалось проверить
эту гипотезу на прецедентных данных. Это проверка состояла в выборе некоторого
распределения из первоначально заданного множества распределений (параметра
гипотезы о распределении) и оценки надежности(доверительного интервала) этого
выбора. Собственно эта функция распределения и была ответом к задаче, только
объект классифицировался уже не однозначно, но с некоторыми вероятностями
принадлежности к классам. Статистиками были разработано так же и
ассимптотическое обоснование таких методов. Такие обоснования делались по
следующей схеме: устанавливался некоторый функционал качества выбора
распределения (доверительный интервал) и показывалось, что при увеличении числа
прецедентов, наш выбор с вероятностью стремящейся к 1 становился верным в
смысле этого функционала (доверительный интервал стремился к 0). Забегая вперед
скажем, что статистический взгляд на проблему распознавания оказался весьма
плодотворным не только в смысле разработанных алгоритмов (в число которых
входят методы кластерного, дискриминантного анализов, непараметрическая
регрессия и т.д.), но и привел впоследствии Вапника к созданию глубокой
статистической теории распознавания [2, c. 7].
Тем не
менее существует серьезная аргументация в пользу того, что задачи распознавания
образов не сводятся к статистике. Любую такую задачу, в принципе, можно
рассматривать со статистической точки зрения и результаты ее решения могут
интерпретироваться статистически. Для этого необходимо лишь предположить, что
пространство объектов задачи является вероятностным. Но с точки зрения
инструментализма, критерием удачности статистической интерпретации некоторого
метода распознавания может служить лишь наличие обоснавания этого метода на
языке статистики как раздела математики. Под обоснаванием здесь понимается
выработка основных требований к задаче которые обеспечивают успех в применении
этого метода. Однако на данный момент для большей части методов распознавания,
в том числе и для тех, которые напрямую возникли в рамках статистического
подхода, подобных удовлетворительных обоснований не найдено. Кроме этого,
наиболее часто применяемые на данный момент статистические алгоритмы, типа
линейного дискриминанта Фишера, парзеновского окна, EM-алгоритма, метода
ближайших соседей, не говоря уже о байесовских сетях доверия, имеют сильно
выраженный эвристический характер и могут иметь интерпретации отличные от
статистических. И наконец, ко всему вышесказанному следует добавить, что помимо
асимптотического поведения методов распознавания, которое и является основным
вопросом статистики, практика распознавания ставит вопросы вычислительной и
структурной сложности методов, которые выводят далеко за рамки одной лишь
теории вероятностей.
Итого,
вопреки стремлениям статистиков рассматривать распознавание образов как раздел
статистики, в практику и идеологию распознавания входили совершенно другие
идеи. Одна из них была вызвана исследованиями в области распознавания
зрительных образов и основана на следующей аналогии [2, c. 20].
Как
уже отмечалось, в повседневной жизни люди постоянно решают (зачастую
бессознательно) проблемы распознавания различных ситуаций, слуховых и
зрительных образов. Подобная способность для ЭВМ
представляет собой в лучшем случае дело будущего. Отсюда некоторыми пионерами
распознавания образов был сделан вывод, что решение этих проблем на ЭВМ должно
в общих чертах моделировать процессы человеческого мышления. Наиболее известной
попыткой подойти к проблеме с этой стороны было знаменитое исследование Ф. Розенблатта
по перцептронам [8, c. 183].
К середине 50-х годов казалось, что нейрофизиологами были поняты
физические принципы работы мозга (в книге "Новый Разум Короля"
знаменитый британский физик-теоретик Р. Пенроуз интересно ставит под сомнение
нейросетевую модель мозга, обосновывая существенную роль в его функционировании
квантово-механических эффектов; хотя, впрочем, эта модель подвергалась сомнению
с самого начала. Отталкиваясь от этих открытий Ф.Розенблатт разработал модель
обучения распознаванию зрительных образов, названную им персептроном. Персептрон Розенблатта представляет
собой следующую функцию (рис. 1) [6, c. 41]:
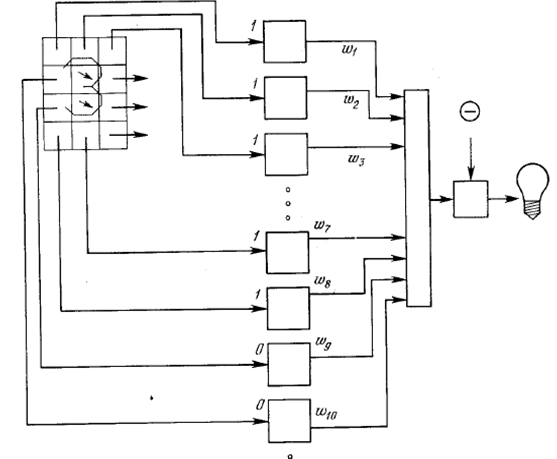
Рис 1. Схема Персептрона
На входе персептрон получает вектор объекта, который в работах
Розенблатта представлял собой бинарный вектор, показывавший какой из пикселов
экрана зачернен изображением а какой нет. Далее каждый из признаков подается на вход нейрона, действие
которого представляет собой простое умножение на некоторый вес нейрона.
Результаты подаются на последний нейрон, который их складывает и общую сумму
сравнивает с некоторым порогом. В зависимости от результатов сравнения входной
объект Х признается нужным образом либо нет. Тогда задача обучения
распознаванию образов состояла в таком подборе весов нейронов и значения порога,
чтобы персептрон давал на прецедентных зрительных образах правильные ответы.
Розенблатт полагал, что получившаяся функция будет неплохо распознавать нужный
зрительный образ даже если входного объекта и не было среди прецедентов. Из
бионических соображений им так же был придуман и метод подбора весов и порога,
на котором останавливаться мы не будем. Скажем лишь, что его подход оказался
успешным в ряде задач распознавания и породил собой целое направление
исследований алгоритмов обучения основанных на нейронных сетях, частным случаем
которых и является персептрон [6, c. 147].
Далее
были придуманы различные обобщения персептрона, функция нейронов была
усложнена: нейроны теперь могли не только умножать входные числа или складывать
их и сравнивать результат с порогами, но применять по отношению к ним более
сложные функции. На рисунке 2 изображено одно из подобных усложнений нейрона:
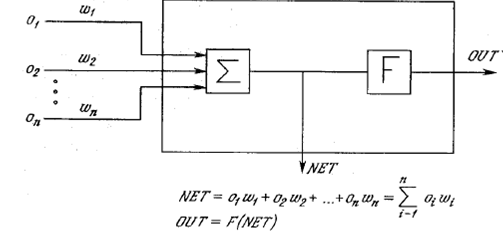
Рис.
2 Схема нейронной сети.
Кроме
того топология нейронной сети могла быть значительно сложнее той, что
рассматривал Розенблатт, например такой:
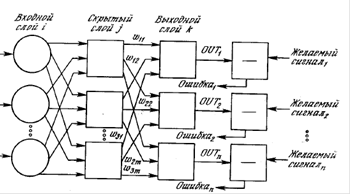
Рис.
3. Схема нейронной сети Розенблатта.
Усложнения
приводили к увеличению числа настраиваемых параметров при обучении, но при этом
увеличивали возможность настраиваться на очень сложные закономерности.
Исследования в этой области сейчас идут по двум тесно связанным направлениям -
изучаются и различные топологии сетей и различные методы настроек.
Нейронные
сети на данный момент являются не только инструментом решения задач
распознавания образов, но получили применение в исследованиях по ассоциативной
памяти, сжатию изображений. Хотя это направление исследований и пересекается
сильно с проблематикой распознавания образов, но представляет собой отдельный
раздел кибернетики. Для распознавателя на данный момент, нейронные сети не
более чем очень специфически определенное, параметрически заданное множество
отображений, которое в этом смысле не имеет каких-либо существенных преимуществ
над многими другим подобными моделями обучения которые далее будут кратко
перечислены.
В
связи с данной оценкой роли нейронных сетей для собственно распознавания (то
есть не для бионики, для которой они имеют первостепенное значение уже сейчас)
хотелось бы отметить следующее: нейронные сети, будучи чрезвычайно сложным
объектом для математического анализа, при грамотном их использовании, позволяют
находить весьма нетривиальные законы в данных. Их трудность для анализа, в
общем случае, объясняется их сложной структурой и как следствие, практически
неисчерпаемыми возможностями для обобщения самых различных закономерностей. Но
эти достоинства, как это часто и бывает, являются источником потенциальных
ошибок, возможности переобучения. Как будет рассказано далее, подобный двоякий
взгляд на перспективы всякой модели обучения является одним из принципов
машинного обучения [6, c.163].
Еще
одним популярным направлением в распознавании являются логические правила и
деревья решений. В сравнении с вышеупомянутыми методами распознавания эти
методы наиболее активно используют идею выражения наших знаний о предметной
области в виде, вероятно самых естественных (на сознательном уровне) структур -
логических правил. Под элементарным логическим правилом подразумевается
высказывание типа «если неклассифицируемые признаки находятся в соотношении X
то классифицируемые находятся в соотношении Y». Примером такого правила в
медицинской диагностике служит следующее: если возраст пациента выше 60 лет и
ранее он перенёс инфаркт, то операцию не делать - риск отрицательного исхода
велик [2, c. 43].
Для
поиска логических правил в данных необходимы 2 вещи: определить меру
«информативности» правила и пространство правил. И задача поиска правил после
этого превращается в задачу полного либо частичного перебора в пространстве
правил с целью нахождения наиболее информативных из них. Определение
информативности может быть введено самыми различными способами и мы не будем
останавливаться на этом, считая что это тоже некоторый параметр модели.
Пространство же поиска определяется стандартно.
После
нахождения достаточно информативных правил наступает фаза «сборки» правил в
конечный классификатор. Не обсуждая глубоко проблемы которые здесь возникают (а
их возникает немалое количество) перечислим 2 основных способа «сборки». Первый
тип - линейный список. Второй тип – взвешенное голосование, когда каждому
правилу ставится в соответствие некоторый вес, и объект относится
классификатором к тому классу за который проголосовало наибольшее количество
правил.
В
действительности, этап построения правил и этап «сборки» выполняются сообща и,
при построении взвешенного голосования либо списка, поиск правил на частях
прецедентных данных вызывается снова и снова, чтобы обеспечить лучшее
согласование данных и модели [4, c.
142].
5. Общая характеристика задач распознавания
образов и их типы
Общая структура системы распознавания и этапы в
процессе ее разработки показаны на рис. 4.
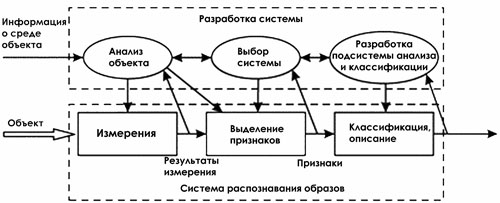
Рис. 4. Структура системы распознавания
Задачи распознавания имеют следующие характерные
черты.
Это информационные задачи, состоящие из двух этапов:
- преобразование исходных данных к виду, удобному для распознавания; -
собственно распознавание (указание принадлежности объекта определенному классу).
В этих задачах можно вводить понятие аналогии или
подобия объектов и формулировать правила, на основании которых объект
зачисляется в один и тот же класс или в разные классы.
В этих задачах можно оперировать набором
прецедентов-примеров, классификация которых известна и которые в виде
формализованных описаний могут быть предъявлены алгоритму распознавания для
настройки на задачу в процессе обучения.
Для этих задач трудно строить формальные теории и
применять классические математические методы (часто недоступна информация для
точной математической модели или выигрыш от использования модели и
математических методов несоизмерим с затратами).
Выделяют следующие типы задач распознавания: -
Задача распознавания - отнесение предъявленного объекта по его описанию к
одному из заданных классов (обучение с учителем); - Задача автоматической
классификации - разбиение множества объектов, ситуаций, явлений по их описаниям
на систему непересекающихся классов (таксономия, кластерный анализ,
самообучение);
- Задача выбора информативного набора признаков при
распознавании; - Задача приведения исходных данных к виду, удобному для
распознавания; - Динамическое распознавание и динамическая классификация -
задачи 1 и 2 для динамических объектов;
- Задача прогнозирования - суть предыдущий тип, в
котором решение должно относиться к некоторому моменту в будущем [5, c.
216].
Заключение
Распознавание образов (а часто
говорят - объектов, сигналов, ситуаций, явлений или процессов) - самая распространенная
задача, которую человеку приходится решать практически ежесекундно от первого
до последнего дня своего существования. Для этого он использует огромные
ресурсы своего мозга, которые мы оцениваем таким показателем как число
нейронов, равное 1010.
Можно даже не утруждая себя
примерами заметить, что похожие действия наблюдаются в биологии, в живой
природе, а иногда даже в неживой. Кроме того, распознавание постоянно
встречается в технике. А если это так, то, очевидно, следует считать механизм
распознавания всеобъемлющим [5, c. 347].
С более общих позиций можно
утверждать, и это вполне очевидно, что в повседневной деятельности человек
постоянно сталкивается с задачами, связанными с принятием решений, обусловленных
непрерывно меняющейся окружающей обстановкой. В этом процессе принимают участие:
органы чувств, с помощью которых человек воспринимает информацию извне;
центральная нервная система, осуществляющая отбор, переработку информации и
принятие решений; двигательные органы, реализующие принятое решение. Но в
основе решений этих задач лежит, в чем легко убедиться, распознавание образов
[8, c. 197].
В своей практике люди решают
разнообразные задачи по классификации и распознаванию объектов, явлений и
ситуаций (мгновенно узнают друг друга, с большой скоростью читают печатные и
рукописные тексты, безошибочно водят автомобили в сложном потоке уличного
движения, осуществляют отбраковку деталей на конвейере, разгадывают коды,
древнюю египетскую клинопись и т.д.) [7, c. 68].
Вычисления в сетях формальных нейронов, во многом
напоминают обработку информации мозгом. В последнее десятилетие нейрокомпьютинг
приобрел чрезвычайную популярность на Западе, где он уже успел превратиться в
инженерную дисциплину, тесно связанную с производством коммерческих продуктов.
Ежегодно выходят десятки книг, посвященных практическим аспектам
нейрокомпьютинга. Интенсивно ведутся работы по созданию новой – аналоговой
элементной базы для нейровычислений.
В России же, где в силу общего снижения тонуса
научных исследований структура науки оказалась «замороженной», до сих пор
бытует мнение, что традиционные математические методы в принципе достаточны для
решения любых задач распознавания образов. Нейрокомпьютинг
же воспринимается как излишество и дань кратковременной моде. Однако на фоне многочисленных
практических успехов нейротехнологий утверждения, что любая конкретная задача
может быть в принципе решена и без них выглядят несколько схоластично. Раз
нейрокомпьютинг на деле доказывает свою конкурентоспособность разумнее
повнимательнее приглядеться к этому феномену. Не рискуем ли мы со своим
скептицизмом просмотреть начало нового этапа компьютерной революции? Не
отстанет ли российская компьютерная наука от мировой, на сей раз окончательно,
в этой чрезвычайно быстро развивающейся и стратегически важной отрасли?
Перспективы в ближайшем будущем. Основной чертой,
отличающей нейрокомпьютеры от современных компьютеров и обеспечивающей будущее
этого направления, по мнению автора, является способность решать
неформализованные проблемы, для которых в силу тех или иных причин еще не
существует алгоритмов решения. Нейрокомпьютеры предлагают относительно простую
технологию порождения алгоритмов путем обучения. В этом их основное
преимущество, их «миссия» в компьютерном мире.
Возможность порождать алгоритмы оказывается особенно
полезной для задач распознавания образов, в которых зачастую не удается
выделить значимые признаки априори. Вот почему нейрокомпьютинг оказался
актуален именно сейчас, в период расцвета мультимедиа, когда развитие
глобальной сети Internet требует разработки новых технологий, тесно связанных с
распознаванием образов. Однако – обо всем по порядку [2, c.
115].
Одна из основных проблем развития и применения
искусственного интеллекта остаётся проблема распознавания звуковых и визуальных
образов. Однако интернет и развитые коммуникационные каналы уже позволяют
создавать системы, решающие эту проблему с помощью социальных сетей, готовых
прийти на помощь роботам 24 часа в сутки.
Профессия инженера систем распознавания образов на
базе социальных сетей будет востребована уже в ближайшем будущем и до тех пор,
пока системы ИИ не будут способны сами пройти тест Тьюринга.
Экстраполируя экспоненциальный рост уровня
технологии в течение нескольких десятилетий, футурист Рэймонд Курцвейл
предположил, что машины, способные пройти тест Тьюринга, будут изготовлены не
ранее 2029 года.
Однако системы ИИ не могут ждать так долго – все
остальные технологии уже готовы к тому, чтобы найти своё применение в медицине,
биологии, системах безопасности и т.д. Их глазами и ушами станут миллионы людей
по всему миру, готовые распознать фотографию террориста, надпись на пузырьке с
лекарством или слова о помощи.
Аудитория социальных сетей растёт гиганскими
темпами. Согласно результатам исследования ComScore, в мае 2009 года аудитория
пользователей одной только Facebook в США насчитывала 70,28 млн человек. И это
практически в два раза выше аналогичного показателя за май 2008 года.
Работа инженера будет заключаться в том, чтобы
организовать процесс передачи пользователям нераспознанных визуальных или
звуковых образов в виде MMS, поп-апов на сайтах, символов CAPTCHA на формах в
блогах и др., верификации полученных данных и отправке распознанного слова или
образа обратно системе ИИ [6, c.
487].
Список литературы
1.
Айзерман М.А.,
Браверман Э.М., Розоноэр Л.И. Метод потенциальных функций в теории обучения
машин. - М.: Наука, 2004. - 384 с.
2.
Горбань А.,
Россиев Д. Нейронные сети на персональном компьютере. //Новосибирск, Наука,
1996. – C 114 – 119.
3.
Журавлев Ю.И. Об
алгебраическом подходе к решению задач распознавания или классификации //
Проблемы кибернетики. М.: Наука, 2005. - Вып. 33. С. 5-68
4.
Журавлев Ю.И.
Избранные научные труды. – Изд. Магистр, 2002. - 420 с.
5.
Мазуров В.Д.
Комитеты систем неравенств и задача распознавания // Кибернетика, 2004, № 2. С.
140-146.
6.
Потапов А.С.
Распознавание образов и машинное восприятие. - С-Пб.:
Политехника, 2007. - 548 с
7.
Минский М.,
Пейперт С. Персептроны. - М.: Мир, 2007. - 261 с.
8.
Растригин Л. А.,
Эренштейн Р. Х. Метод коллективного распознавания. 79 с. ил. 20 см., М.
Энергоиздат, 2006. – 80 с.
9.
Рудаков К.В. Об
алгебраической теории универсальных и локальных ограничений для задач
классификации // Распознавание, классификация, прогноз. Математические методы и
их применение. Вып. 1. - М.: Наука, 2007. - С. 176-200.
10.
Фу К. Структурные
методы в распознавании образов. - М.: Мир, 2005. - 144
с.
|



