Информатика программирование : Курсовая работа: Кэш-память
Курсовая работа: Кэш-память
Государственный университет информационно
коммуникационных технологий
Курсовая работа
на тему:
Кэш-память
практическое задание: Дефрагментация диска
по предмету:
Операционные системы
выполнил:
Волоха Алексей Владимирович
группа ИБД-32б
Киев-2006
План
Теоретическая часть
Кэш-память
Введение 3
Причины внедрения кэш-памяти 4
Раздел 1 4
Что такое кэш-память? 4
Уровень за уровнем 5
Внутренний кэш 6
Смешанная и разделенная кэш-память 9
Статическая и динамическая память
10
TLB как разновидность кэш-памяти
11
Раздел
2
11
Организация кэш-памяти 11
Стратегия размещения 15
Отображение
секторов ОП в кэш-памяти 15
Иерархическая модель кэш-памяти 16
Ассоциативность кэш-памяти 16
Размер строки и тега кэш-памяти 17
Типы подключения кэш-памяти 18
Сегментирование кэш-памяти и
быстродействие жестких дисков 19
Увеличение производительности
кэш-памяти 21
Зачем увеличивать кэш? 21
Выводы 23
Практическая
часть
Дефрагментация
диска 24
Литература 27
Введение
В качестве элементной базы основной памяти в большинстве
ЭВМ используются микросхемы динамических ОЗУ, на порядок уступающие по
быстродействию центральному процессору. В результате, процессор вынужден
простаивать несколько периодов тактовой частоты, пока информация из ИМС памяти
установится на шине данных ЭВМ. Если же ОП выполнить на быстрых микросхемах
статической памяти, стоимость ЭВМ возрастет весьма существенно.
Экономически
приемлемое решение этой проблемы возможно при использовании двухуровневой
памяти, когда между основной памятью и процессором размещается небольшая, но
быстродействующая буферная память или кэш-память. Вместе с основной памятью она
входит в иерархическую структуру и ее действие эквивалентно быстрому доступу к
основной памяти. Использование кэш-памяти позволяет избежать полного
заполнения всей машины быстрой RAM памятью. Обычно
программа использует память какой либо ограниченной области, храня нужную
информацию в кэш-памяти, работа с которой позволяет процессору обходиться без
всяких циклов ожидания. В больших универсальных ЭВМ, основная память которых
имеет емкость порядка 1-32 Гбайт, обычно используется кэш-память емкость 1-12
Мбайт, т.е. емкость кэш-память составляет порядка 1/100-1/500 емкости основной
памяти, а быстродействие в 5-10 раз выше быстродействия основной памяти. Выбор
объема кэш-памяти – всегда компромисс между стоимостными показателями ( в
сравнении с ОП ) и ее емкостью, которая должна быть достаточно большой, чтобы
среднее время доступа в системе, состоящей из основной и кэш-памяти,
определялось временем доступа к последней. Реальная эффективность использования
кэш-памяти зависит от характера решаемых задач и невозможно определить заранее,
какой объем ее будет действительно
оптимальным.
Не всякая
кэш-память равнозначна. Большое значение имеет тот факт, как много
информации может содержать кэш-память. Чем больше кэш-память, тем больше
информации может быть в ней размещено, а следовательно, тем больше вероятность,
что нужный байт будет содержаться в этой быстрой памяти. Очевидно, что самый
лучший вариант - это когда объём кэш-памяти соответствует объёму всей
оперативной памяти. В этом случае вся остальная память становится не
нужной. Крайне противоположная ситуация - 1 байт кэш-памяти - тоже не имеет
практического значения, так как вероятность того, что нужная информация
окажется в этом байте, стремится к нулю.
В процессе работы такой системы в буферную память
копируются те участки ОП, к которым производится обращение со стороны
процессора. Выигрыш достигается за счет свойства локальности, ввиду большой
вероятности обращения процессором к командам, лежащим в соседних ячейках
памяти.
Кэш-память, состоящая из m слов, сохраняет копии не менее, чем m-слов
из всех слов основной памяти. Если копия, к адресу которой был выполнен доступ
ЦП, существует в кэш-памяти, то считывание завершается уже при доступе
к кэш-памяти. Отметим, что использование кэш-памяти основывается на принципах
пространственной и временной локальности. В случае пространственной локальности
основная память разбивается на блоки с фиксированным числом слов и обмен
данными между основной памятью и кэш-памятью выполняется блоками. При доступе к
некоторому адресу центральный процессор должен сначала определить содержит ли
кэш-память копию блока с указанным адресом, и если имеется, то определить, с
какого адреса кэш-памяти начинается этот блок. Эту информацию ЦП получает с
помощью механизма преобразования адресов.
Причины внедрения
кэш-памяти
Явная необходимость в кэш-памяти
при проектировании массовых ЦП проявилась в начале 1990-х гг., когда тактовые
частоты ЦП значительно превысили частоты системных шин, и, в частности, шины
памяти. В настоящее время частоты серверных ЦП достигают почти 4 ГГц, а
оперативной памяти, массово применяемой в серверах, - только 400 МГц (200 МГц с
удвоением благодаря передаче по обоим фронтам сигнала). В этой ситуации при
прямом обращении к памяти функциональные устройства ЦП значительную часть
времени простаивают, ожидая доставки данных. В какой-то мере проблемы
быстродействия оперативной памяти могут быть решены увеличением разрядности
шины памяти, но даже в серверах младшего уровня нередко встречается 8-16 гнезд
для модулей памяти, поэтому такое решение усложняет дизайн системной платы.
Проложить же 256- или даже 512-бит шину к расположенной внутри кристалла ЦП
кэш-памяти сравнительно несложно. Таким образом, эффективной альтернативы
кэш-памяти в современных высокопроизводительных системах не существует.
Раздел 1
Что такое кэш-память?
Кэш-память — это
высокоскоростная память произвольного доступа, используемая процессором
компьютера для временного хранения информации. Она увеличивает
производительность, поскольку хранит наиболее часто используемые данные и
команды «ближе» к процессору, откуда их можно быстрее получить
Кэш-память напрямую
влияет на скорость вычислений и помогает процессору работать с более
равномерной загрузкой. Представьте себе массив информации, используемой в вашем
офисе. Небольшие объемы информации, необходимой в первую очередь, скажем список
телефонов подразделений, висят на стене над вашим столом. Точно так же вы
храните под рукой информацию по текущим проектам. Реже используемые
справочники, к примеру, городская телефонная книга, лежат на полке, рядом с
рабочим столом. Литература, к которой вы обращаетесь совсем редко, занимает
полки книжного шкафа.
Компьютеры хранят
данные в аналогичной иерархии. Когда приложение начинает работать, данные и
команды переносятся с медленного жесткого диска в оперативную память
произвольного доступа (Dynamic Random Access Memory — DRAM), откуда процессор
может быстро их получить. Оперативная память выполняет роль кэша для жесткого
диска.
Для достаточно быстрых компьютеров (например, на основе intel-80386 с тактовой частотой более 25 мгц или
intel-80486) необходимо обеспечить быстрый доступ к оперативной памяти, иначе
микропроцессор будет простаивать и быстродействие компьютера уменьшится. Для
этого такие компьютеры могут оснащаться кэш-памятью, т.е.
"сверхоперативной" памятью относительно небольшого объема (обычно
от 64 до 256 кбайт), в которой хранятся наиболее часто используемые участки
оперативной памяти. Кэш-память располагается "между" микропроцессором
и оперативной памятью, и при обращении микропроцессора к памяти сначала
производится поиск нужных данных в кэш-памяти. Поскольку время доступа к
кэш-памяти в несколько раз меньше, чем к обычной памяти, а в большинстве
случаев необходимые микропроцессору данные содержаться в кэш-памяти,
среднее время доступа к памяти уменьшается. Для компьютеров на основе
intel-80386dx или 80486sx размер кэш-памяти в 64 кбайт является
удовлетворительным, 128 кбайт - вполне достаточным. Компьютеры на основе
intel-80486dx и dx2 обычно оснащаются кэш-памятью емкостью 256 кбайт.
Уровень
за уровнем
Хотя оперативная
память намного быстрее диска, тем не менее и она не успевает за потребностями
процессора. Поэтому данные, которые требуются часто, переносятся на следующий
уровень быстрой памяти, называемой кэш-памятью второго уровня. Она может располагаться
на отдельной высокоскоростной микросхеме статической памяти (SRAM),
установленной в непосредственной близости от процессора (в новых процессорах
кэш-память второго уровня интегрирована непосредственно в микросхему
процессора.
На более высоком
уровне информация, используемая чаще всего (скажем, команды в многократно
выполняемом цикле), хранится в специальной секции процессора, называемой
кэш-памятью первого уровня. Это самая быстрая память.
Процессор Pentium
III компании Intel имеет кэш-память первого уровня емкостью 32 Кбайт на
микросхеме процессора и либо кэш-память второго уровня емкостью 256 Кбайт на
микросхеме, либо кэш-память второго уровня емкостью 512 Кбайт, не
интегрированную с процессором.
Когда процессору
нужно выполнить команду, он сначала анализирует состояние своих регистров
данных. Если необходимых данных в регистрах нет, он обращается к кэш-памяти
первого уровня, а затем — к кэш-памяти второго уровня. Если данных нет ни в
одной кэш-памяти, процессор обращается к оперативной памяти. И только в том
случае, если нужных данных нет и там, он считывает данные с жесткого диска.
Когда процессор
обнаруживает данные в одном из кэшей, это называют «попаданием»; неудачу
называют «промахом». Каждый промах вызывает задержку, поскольку процессор будет
пытаться обнаружить данные на другом, более медленном уровне. В хорошо
спроектированных системах с программными алгоритмами, которые выполняют
предварительную выборку данных до того, как они потребуются, процент
«попаданий» может достигать 90.
Для процессоров
старшего класса на получение информации из кэш-памяти первого уровня может уйти
от одного до трех тактов, а процессор в это время ждет и ничего полезного не
делает. Скорость доступа к данным из кэш-памяти второго уровня, размещаемой на
процессорной плате, составляет от 6 до 12 циклов, а в случае с внешней
кэш-памятью второго уровня — десятки или даже сотни циклов.
Кэш-память для
серверов даже более важна, чем для настольных ПК, поскольку серверы
поддерживают между процессором и памятью весьма высокий уровень трафика,
генерируемого клиентскими транзакциями. В 1991 году Intel превратила ПК на базе
процессора 80486 с тактовой частотой 50 МГц в сервер, добавив на процессорную
плату кэш с тактовой частотой 50 МГц. Хотя шина, связывающая процессор и память,
работала с частотой всего 25 МГц, такая кэш-память позволила многие программы
во время работы полностью размещать в процессоре 486 с тактовой частотой 50
МГц.
Иерархическая
организация памяти помогает компенсировать разрыв между скоростями процессоров,
ежегодно увеличивающимися примерно на 50% в год, и скоростями доступа к DRAM,
которые растут лишь на 5%. Как считает Джон Шен, профессор Университета
Карнеги–Меллона, по мере усиления этого диссонанса производители аппаратного
обеспечения добавят третий, а возможно и четвертый уровень кэш-памяти.
Действительно, уже
в этом году Intel намерена представить кэш-память третьего уровня в своих
64-разрядных процессорах Itanium. Кэш емкостью 2 или 4 Мбайт будет связан с
процессором специальной шиной, тактовая частота которой совпадает с частотой
процессора.
IBM также
разработала собственную кэш-память третьего уровня для 32- и 64-разрядных
ПК-серверов Netfinity. По словам Тома Бредикича, директора по вопросам
архитектуры и технологий Netfinity, сначала кэш будет размещаться на микросхеме
контроллера памяти, выпуск которой начнется к концу следующего года.
Кэш-память третьего
уровня корпорации IBM станет общесистемным кэшем, куда смогут обращаться от 4
до 16 процессоров сервера. С кэш-памятью третьего уровня Intel сможет работать
только тот процессор, к которому она подключена, но представители IBM
подчеркнули, что их кэш третьего уровня способен увеличить пропускную
способность всей системы. Бредикич отметил, что новая кэш-память производства
IBM также поможет реализовать компьютерные системы высокой готовности,
необходимые для электронной коммерции, поскольку с ее помощью можно будет
менять модули основной памяти и выполнять модернизацию, не прерывая работу
системы.
Внутренний
кэш
Внутренне кэширование обращений
к памяти применяется в процессорах, начиная с 486-го. С кэшированием связаны
новые функции процессоров, биты регистров и внешние сигналы.
Процессоры
486 и Pentium имеют внутренний кэш первого уровня, в Pentium Pro и Pentium II имеется и вторичный кэш. Процессоры могут
иметь как единый кэш инструкций и данных, так и общий. Выделенный кэш
инструкций обычно используется только для чтения. Для внутреннего кэша обычно
используется наборно-ассоциативная архитектура.
Строки
в кэш-памяти выделяются только при чтении, политика записи первых процессоров
486 – только Write Through (сквозная запись) – полностью
программно-прозрачная. Более поздние модификации 486-го и все старшие
процессоры позволяют переключаться на политику Write Back (обратная
запись).
Работу
кэша рассмотрим на примере четырехканального наборно-ассоциативного кэша
процессора 486, его физическая структура приведена на рис.1. Кэш является несекторированным – каждый бит достоверности (Valid bit) относится к целой строке, так что стока не может являться “частично достоверной”.
Работу
внутренней кэш-памяти характеризуют следующие процессы: обслуживание запросов
процессора на обращение к памяти, выделение и замещение строк для кэширования
областей физической памяти, обеспечение согласованности данных внутреннего кэша
и оперативной памяти, управление кэшированием.
Любой
внутренний запрос процессора на обращение к памяти направляется на
внутренний кэш. Теги четырех строк набора, который обслуживает данный адрес,
сравниваются со старшими битами запрошенного физического адреса. Если
адресуемая область представлена в строке кэш-памяти (случая попадания –cache hit), запрос на чтение обслуживается только кэш-памятью, не выходя на внешнюю
шину. Запрос на запись модифицирует данную строку, и в зависимости от политики
записи либо сразу выходит на внешнюю шину (при сквозной записи), либо несколько
позже (при использовании алгоритма обратной записи).
Рис 1. Структура
первичного кэша процессора 486
В
случае промаха (Cache Miss) запрос на запись направляется только на
внешнюю шину, а запрос на чтение обслуживается сложнее. Если этот зарос
относится к кэшируемой области памяти, выполняется цикл заполнения целой строки
кэша – все 16 байт (32 для Pentium) читаются из оперативной памяти и помещаются в одну из строк кэша, обслуживающего
данный адрес. Если затребованные данные не укладываются в одной строке,
заполняется и соседняя. Заполнение строки процессор старается выполнить самым
быстрым способом – пакетным циклом с 32-битными передачами (64-битными для Pentium и старше).
Внутренний
запрос процессора на данные удовлетворяется сразу, как только затребованные
данные считываются из ОЗУ – заполнение строки до конца может происходить
параллельно с обработкой полученных данных. Если в наборе, который обслуживает
данный адрес памяти, имеется свободная строка (с нулевым битом достоверности),
заполнена будет она и для нее установится бит достоверности. Если свободных
строк в наборе нет, будет замещена строка, к которой дольше всех не было
обращений. Выбор строки для замещения выполняется на основе анализа бит LRU (Least Recently Used)
по алгоритму “псевдо-LRU”. Эти биты (по три на каждый из наборов)
модифицируются при каждом обращении к строке данного набора (кэш-попадании или
замещении).
Таким
образом, выделение и замещение строк выполнятся только
кэш-промахов чтения, при промахах записи заполнение строк не производится. Если
затребованная область памяти присутствует в строке внутреннего кэша, то он
обслужит этот запрос. Управлять кэшированием можно только на этапе заполнения
строк; кроме того, существует возможность их аннулирования – объявления
недостоверными и очистка всей кэш-памяти.
Очистка внутренней кэш-памяти при сквозной
записи (обнуление бит достоверности всех строк) осуществляется внешним сигналом
FLUSH# за один такт системной шины
(и, конечно же, по сигналу RESET).
Кроме того, имеются инструкции аннулирования INVD и WBINVD. Инструкция INVD аннулирует строки внутреннего кэша без
выгрузки модифицированных строк, поэтому ее неосторожное использование при
включенной политике обратной записи может привести к нарушению целостности
данных в иерархической памяти. Инструкция WBINVD предварительно выгружает модифицированные
строки в основную память (при сквозной записи ее действие совпадает с INVD). При обратной записи очистка кэша подразумевает
и выгрузку всех модифицированных строк в основную память. Для этого,
естественно, может потребоваться и значительное число тактов системной
шины, необходимых для проведения всех операций записи.
Аннулирование строк выполняется внешними
схемами – оно необходимо в системах, у которых в оперативную память запись
может производить не только один процессор, а и другие контроллеры шины
процессор или периферийные контроллеры. В этом случае требуются специальные
средства для поддержания согласованности данных во всех ступенях памяти – в
первичной и вторичной кэш-памяти и динамического ОЗУ. Если внешний (по
отношению к рассматриваемому процессору) контроллер выполняет запись в память,
процессору должен быть подан сигнал AHOLD. По этому сигналу процессор немедленно отдает управление шиной адреса A[31:4], на которой внешним контроллером
устанавливается адрес памяти, сопровождаемый стробом EADS#. Если адресованная память присутствует в первичном кэше, процессор
аннулирует строку – сбрасывает бит достоверности этой строки (она
освобождается). Аннулирование строки процессор выполняет в любом состоянии.
Управление
заполнением кэша возможно и на аппаратном и на программном уровнях. Процессор
позволяет кэшировать любую область физической памяти. Внешние схемы могут
запрещать процессору кэшировать определенные области памяти установкой высокого
уровня сигнала KEN# во время
циклов доступа к этим областям памяти. Этот сигнал управляет только
возможностью заполнения строк кэша из адресованной области памяти. Программно
можно управлять кэшируемостью каждой страницы памяти – запрещать
единичным значением бита PCD (Page Cache Disable)
в таблице или каталоге страниц. Для процессоров с WB-кэшем бит PWT (Page Write Through) позволяет постранично управлять и
алгоритмом записи. Общее программное управление кэшированием осуществляется
посредством бит управляющего регистра CR0:CD (Cache Disable) и NW (No Write Through). Возможны следующие сочетания бит
регистра:
·
CD=1, NW=1 – если после установки такого значения выполнить очистку кэша, кэш
будет полностью отключен. Если же перед установкой этого сочетания бит кэша был
заполнен, а очистка не производилась, кэш превращается в “замороженную
область статической памяти;
·
CD=1, CW=0 – заполнение кэша запрещено, но сквозная запись разрешена. Эффект
аналогичен временному переводу сигнала KEN# в высокое (пассивное) состояние. Этот режим может использоваться для
временного отключения кэша, после которого возможно его включение без очистки;
·
CD=0, NW=1 – запрещенная комбинация (вызывает отказ общей защиты);
·
CD=0, NW=0 – нормальный режим работы со сквозной записью.
Для
полного запрета кэша необходимо установить CD=1 и NW=1, после чего
выполнить очистку (Flush). Без
очистки кэш будет обслуживать запросы в случае попаданий.
Процессоры
486 и старше имеют выходные сигналы PCD и PWT, управляющие работой вторичного (внешнего) кэша (они же управляют и
внутренним кэшем). В циклах обращения к памяти, когда страничные преобразования
не используются (например, при обращении к таблице каталогов страниц),
источником сигналов являются биты PCD и PWT регистра CR3, при
обращении к каталогу страниц – биты PCD и PWT из дескриптора соответствующего вхождения
каталога, при обращении к самим данным – биты PCD и PWT из дескриптора страницы. Кроме того, оба этих сигнала могут
принудительно устанавливаться общими битами управления кэшированием CD и NW регистра CRO.
Режим
обратной записи может разрешаться только аппаратно сигналом WB/WT#, вырабатываемым
внешними схемами.
В
пространстве памяти РС имеются области, для которых кэширование принципиально
недопустимо (например, разделяемая память адаптеров) или непригодна политика
обратной записи. Кроме того, кэширование иногда полезно отключать при
выполнении однократно исполняемых участков программы (например, инициализации)
с тем, чтобы из кэша не вытиснялись более часто используемые фрагменты.
Напомним, что запретить можно только заполнение строк, а обращение к памяти,
уже представленной действительными строками кэша, все равно будет обслуживаться
из кэша. Для полного запрета работы кэша строки должны быть аннулированы.
Программно
при включенном режиме страничного преобразования кэшированием управляют биты
атрибутов страниц (на уровне таблицы страниц и их каталога), биты PCD и PWT регистра CR3, и, наконец, глобально кэшированием
управляют биты CD и NW регистра CR0.
Аппаратно
(сигналом KEN#) внешние схемы
могут управлять кэшированием (разрешать заполнение строк) для каждого
конкретного адреса обращения к физической памяти.
Смешанная и разделенная кэш-память.
Внутренняя
кэш-память использовалась ранее как для инструкций(команд), так и для данных.
Такая память называлась смешанной, а ее архитектура – Принстонской, в которой в
единой кэш-памяти, в соответствии с классическими принципами фон Неймана,
хранились и команды и данные.
Сравнительно
недавно стало обычным разделять кэш-память на две – отдельно для инструкций и
отдельно для данных.
Преимуществом
смешанной кэш-памяти является то, что при заданном объеме, ей свойственна более
высокая вероятность попаданий, по сравнению с разделенной, поскольку в ней
автоматически устанавливается оптимальный баланс между инструкциями и данными.
Если в выполняемом фрагменте программы обращения к памяти связаны, в основном,
с выборкой инструкций, а доля обращений к данным относительно мала, кэш-память
имеет тенденцию заполнения инструкциями и наоборот.
С другой
стороны, при раздельной кэш-памяти, выборка инструкций и данных может
производиться одновременно, при этом исключаются возможные конфликты. Последнее
особенно существенно в системах, использующих конвейеризацию команд, где
процессор извлекает команды с опережением и заполняет ими буфер или конвейер.
Так,например,
в процессоре Intel® 486 DX2
применялась смешанная кэш-память,
В Intel® Pentium®
и в AMD Athlon
с их суперскалярной организацией – раздельная. Более того, в этих процессорах
помимо кэш-памяти инструкций и кэш-памяти данных используется также и адресная
кэш-память. Этот вид кэша используется в устройствах управления памятью, в том
числе для преобразования виртуальных адресов в физические.
Благодаря использованию нанотехнологий, для
снижения потребляемой мощности, увеличения быстродействия ЭВМ( что достигается
сокращением времени обмена данными между процессором и кэш-памятью) существует
возможность, а более того имеются реальные примеры того, что кэш-память
реализуют в одном кристале с процессором. Такая внутренняя кэш-память
реализуется по технологии статического ОЗУ и является наиболее
быстродействующей. Объем ее обычно составляет 64-128 Кбайт, причем дальнейшее увеличение
ее объема приводит обычно к снижению быстродействия из-за усложнения схем
управления и дешифрации адреса.
Альтернативой,
широко применяемой в настоящее время, является вторая (внешняя) кэш-память
большего объема, расположенная между внутренней кэш-памятью и ОП. В этой
двухуровневой системе кэш-памяти, внутренней памяти отводится роль первого
уровня L1, а внешней - второго L2.
емкость L2 обычно на порядок и более выше, чем L1, а быстродействие и стоимость ниже. Память второго уровня
также строится обычно как статическое ОЗУ. Емкость ее может составлять от 256
Кбайт до 1 Мбайта и технически реализуется как в виде отдельной микросхемы,
однако может размещаться и на одном кристалле с
процессором.
Самые
современные процессоры от крупнейших производителей оснащаются сегодня
кэш-памятью емкостью у Intel Pentium
4 на ядре Northwood - 512 Кбайт кэш-памяти L2,
а процессоры Prescott будут выпускаться по 0,09-микронной
технологии и получат кэш-память второго уровня удвоенного объема, который
составит 1 Мбайт. Intel продолжает широко рекламировать
свой "экстремальный" игровой процессор Pentium 4
Extreme Edition
на основе модифицированного серверного ядра Gallatin с
тактовой частотой 3,40 ГГц и кэш-памятью третьего уровня объемом 2 Мбайта. Она
дополняет стандартный нортвудовский кэш L2 512 Кбайт и
тоже работает на частоте ядра процессора (правда, с большей раза в два
латентностью). Таким образом, в сумме новый Pentium 4 Extreme Edition имеет
кэш-память объемом 2,5
Мбайт.
Дополнительная
кэш-память третьего уровня ведет начало от серверных процессоров Xeon MP на 0,13-микронном ядре Gallatin
и не имеет ничего общего с грядущим 90-нанометровым Prescott,
однако этот кристалл (ядро) все же немного переработали с целью поддержки
системной шины 800 МГц, уменьшения энергопотребления и др. и упаковали в
стандартный корпус от текущих Pentium
4. В
свою очередь AMD Athlon
64 и AMD Opteron
работающие на более высокой частоте 2200 МГц, производятся по 0,13-микронной
технологии (SOI) и содержат 105,9 млн. транзисторов и
отличаются от предшествующих Athlon XP новым ядром с 64-битными возможностями вычислений (наряду с
улучшенными 32-битными на базе прежнего ядра Athlon XP), кэш-памятью второго уровня объемом 1
Мбайт (причем кэш у Атлонов инклюзивный, то есть полный объем с учетом 128
Кбайт L1 составляет 1152 Кбайт).
При доступе к
памяти, ЦП сначала обращается к кэш-памяти первого уровня. При промахе
производится обращение к кэш-памяти второго уровня. Если информация отсутствует
и в L2, производится обращение к ОП, и соответствующий блок
заносится сначала в L2, а затем и в L1.
Благодаря такой процедуре, часто запрашиваемая информация может быть легко
восстановлена из кэш-памяти второго уровня.
Потенциальная
экономия за счет применения L2 зависит от вероятности
попаданий как в L1, так и L2. Однако,
опыт Intel и AMD показывает, что
использование кэш-памяти второго уровня существенно улучшает
производительность. Именно поэтому во всех проанонсированых производителями
новейших версиях процессоров применяется двухуровневая и даже трехуровневая
организация кэш-памяти.
Статическая и
динамическая память
В каждом современном ЦП
предусмотрено некоторое количество статической памяти, работающей на частоте
ядра. Именно статической, поскольку использование динамической памяти в этих
целях представляется крайне нерациональным.
Одна ячейка статической памяти
состоит из шести транзисторов и двух резисторов (для техпроцессов с проектными
нормами до 0,5 мкм могли быть использованы только четыре транзистора на одну
ячейку, с дополнительным слоем поликремния и с более жесткими ограничениями по
максимальной тактовой частоте), в то время как аналогичная структура
динамической памяти состоит из одного транзистора и одного конденсатора.
Быстродействие статической памяти
намного выше (емкость, используемая в динамической памяти, имеет определенную
скорость зарядки до требуемого уровня, определяющую "частотный
потолок"), но из-за большего количества составляющих элементов она
существенно дороже в производстве и отличается более высоким энергопотреблением.
Битовое значение ячейки статической памяти характеризуется состоянием затворов
транзисторов, а динамической - уровнем заряда конденсатора. Так как
конденсаторы имеют свойство с течением времени разряжаться, то для поддержания
их состояния требуется регулярная перезарядка (для современных микросхем
динамической памяти - приблизительно 15 раз в секунду). Кроме того, при
операции чтения из ячейки динамической памяти конденсатор разряжается, т. е.
ячейка утрачивает свой первоначальный заряд, а следовательно должна быть
перезаряжена.
Очевидно, что статическая память
используется там, где требуется максимальное быстродействие (регистры ЦП,
кэш-память, локальная память сигнального процессора), а динамическая - там, где
приоритетом является объем, а не скорость чтения-записи (оперативная память,
буферы периферийных устройств).
TLB
как разновидность кэш-памяти
Почти все современные ЦП обладают
TLB (Translation Look-aside Buffers, вспомогательные буфера
преобразования). Своим существованием они обязаны тому факту, что ЦП в работе
используют преимущественно виртуальные адреса оперативной памяти, в то время
как контроллеры оперативной и кэш-памяти работают преимущественно с реальными
адресами. Для того чтобы не вычислять при каждом обращении к памяти реальный
адрес из виртуального, в ЦП присутствуют таблицы соответствия виртуальных
адресов страниц памяти реальным. Как правило, их объем невелик (от единиц до
сотен записей), но этого вполне достаточно, поскольку часто запрашиваемые
данные или команды обычно хорошо локализуются в пределах страницы памяти
размером 4 или 8 Кбайт.
Что же происходит, если
запрашиваемого реального адреса какой-либо страницы не находится в TLB? A-box ЦП
отрабатывает специальный вызов (exception trap), на который ОС должна
адекватно отреагировать, т. е. произвести поиск нужной страницы в своих
таблицах подсистемы виртуальной памяти. Если в процессе поиска окажется, что
указанная страница находится в файле или разделе подкачки, то она должна
незамедлительно быть оттуда считана в оперативную память. В итоге А-box ЦП получит реальный адрес нужной страницы памяти и
процесс пойдет своим путем.
Стоит также заметить, что единой
схемы адресации записей кэш-памяти не существует. Поэтому в зависимости от
иерархического расположения и целевого назначения данной структуры кэш-памяти,
а также идей построения определенного ЦП может использоваться выборочно как
реальная, так и виртуальная адресация записей, или даже гибридная схема
(реальное тегирование с виртуальной индексацией), что предполагает и
соответствующую организацию структуры TLB.
Раздел 2
Организация
кэш-памяти
Концепция кэш-памяти возникла
раньше чем архитектура IBM/360, и сегодня кэш-память
имеется практически в любом классе компьютеров, а в некоторых компьютерах - во
множественном числе.
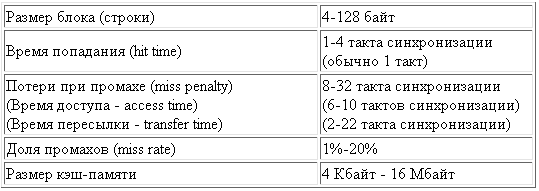
Рис. 2. Типовые значения ключевых параметров для кэш-памяти
рабочих станций и серверов
Все термины, которые были
определены раньше могут быть использованы и для кэш-памяти, хотя слово "строка"
(line) часто употребляется вместо слова
"блок" (block).
На рисунке 2 представлен типичный
набор параметров, который используется для описания кэш-памяти.
Рассмотрим организацию кэш-памяти
более детально, отвечая на четыре вопроса об иерархии памяти.
1. Где может размещаться блок в кэш-памяти?
Принципы размещения блоков в
кэш-памяти определяют три основных типа их организации:
Если каждый блок основной памяти имеет только одно
фиксированное место, на котором он может появиться в кэш-памяти, то такая
кэш-память называется кэшем с прямым отображением (direct mapped). Это наиболее простая
организация кэш-памяти, при которой для отображение адресов блоков основной
памяти на адреса кэш-памяти просто используются младшие разряды адреса блока.
Таким образом, все блоки основной памяти, имеющие одинаковые младшие разряды в
своем адресе, попадают в один блок кэш-памяти, т.е.
(адрес блока кэш-памяти) =
(адрес блока основной памяти) mod
(число блоков в кэш-памяти)
Если некоторый блок основной
памяти может располагаться на любом месте кэш-памяти, то кэш называется
полностью ассоциативным (fully associative).
Если некоторый блок основной памяти может располагаться на
ограниченном множестве мест в кэш-памяти, то кэш называется
множественно-ассоциативным (set associative). Обычно множество представляет собой группу из
двух или большего числа блоков в кэше. Если множество состоит из n блоков, то такое размещение называется
множественно-ассоциативным с n каналами (n-way set associative).
Для размещения блока прежде всего необходимо определить множество. Множество
определяется младшими разрядами адреса блока памяти (индексом):
(адрес множества кэш-памяти) =
(адрес блока основной памяти) mod
(число множеств в кэш-памяти)
Далее, блок может размещаться на любом месте данного
множества.
Диапазон возможных организаций
кэш-памяти очень широк: кэш-память с прямым отображением есть просто
одноканальная множественно-ассоциативная кэш-память, а полностью ассоциативная
кэш-память с m блоками может быть названа m-канальной множественно-ассоциативной. В современных
процессорах как правило используется либо кэш-память с прямым отображением,
либо двух- (четырех-) канальная множественно-ассоциативная кэш-память.
2. Как найти блок, находящийся в кэш-памяти?
У каждого блока в кэш-памяти
имеется адресный тег, указывающий, какой блок в основной памяти данный блок
кэш-памяти представляет. Эти теги обычно одновременно сравниваются с
выработанным процессором адресом блока памяти.
Кроме того, необходим способ
определения того, что блок кэш-памяти содержит достоверную или пригодную для
использования информацию. Наиболее общим способом решения этой проблемы
является добавление к тегу так называемого бита достоверности (valid bit).
Адресация
множественно-ассоциативной кэш-памяти осуществляется путем деления адреса,
поступающего из процессора, на три части: поле смещения используется для выбора
байта внутри блока кэш-памяти, поле индекса определяет номер множества, а поле
тега используется для сравнения. Если общий размер кэш-памяти зафиксировать, то
увеличение степени ассоциативности приводит к увеличению количества блоков в
множестве, при этом уменьшается размер индекса и увеличивается размер тега.
3. Какой блок кэш-памяти должен быть замещен при промахе?
При возникновении промаха,
контроллер кэш-памяти должен выбрать подлежащий замещению блок. Польза от
использования организации с прямым отображением заключается в том, что
аппаратные решения здесь наиболее простые. Выбирать просто нечего: на попадание
проверяется только один блок и только этот блок может быть замещен. При
полностью ассоциативной или множественно-ассоциативной организации кэш-памяти
имеются несколько блоков, из которых надо выбрать кандидата в случае промаха.
Как правило для замещения блоков применяются две основных стратегии: случайная
и LRU.
В первом случае, чтобы иметь
равномерное распределение, блоки-кандидаты выбираются случайно. В некоторых
системах, чтобы получить воспроизводимое поведение, которое особенно полезно во
время отладки аппаратуры, используют псевдослучайный алгоритм замещения.
Во втором случае, чтобы уменьшить
вероятность выбрасывания информации, которая скоро может потребоваться, все
обращения к блокам фиксируются. Заменяется тот блок, который не использовался
дольше всех (LRU - Least-Recently Used).
Достоинство случайного способа
заключается в том, что его проще реализовать в аппаратуре. Когда количество
блоков для поддержания трассы увеличивается, алгоритм LRU
становится все более дорогим и часто только приближенным. На рисунке 3 показаны
различия в долях промахов при использовании алгоритма замещения LRU и случайного алгоритма.

Рис. 3. Сравнение долей промахов для алгоритма LRU и случайного алгоритма замещения
при нескольких размерах кэша и разных ассоциативностях при
размере блока 16 байт
4. Что происходит во время записи?
При обращениях к кэш-памяти на
реальных программах преобладают обращения по чтению. Все обращения за командами
являются обращениями по чтению и большинство команд не пишут в память. Обычно
операции записи составляют менее 10% общего трафика памяти. Желание сделать
общий случай более быстрым означает оптимизацию кэш-памяти для выполнения
операций чтения, однако при реализации высокопроизводительной обработки данных
нельзя пренебрегать и скоростью операций записи.
К счастью, общий случай является
и более простым. Блок из кэш-памяти может быть прочитан в то же самое время,
когда читается и сравнивается его тег. Таким образом, чтение блока начинается
сразу как только становится доступным адрес блока. Если чтение происходит с
попаданием, то блок немедленно направляется в процессор. Если же происходит
промах, то от заранее считанного блока нет никакой пользы, правда нет и
никакого вреда.
Однако при выполнении операции
записи ситуация коренным образом меняется. Именно процессор определяет размер
записи (обычно от 1 до 8 байтов) и только эта часть блока может быть изменена.
В общем случае это подразумевает выполнение над блоком последовательности
операций чтение-модификация-запись: чтение оригинала блока, модификацию его
части и запись нового значения блока. Более того, модификация блока не может
начинаться до тех пор, пока проверяется тег, чтобы убедиться в том, что
обращение является попаданием. Поскольку проверка тегов не может выполняться
параллельно с другой работой, то операции записи отнимают больше времени, чем
операции чтения.
Очень часто организация
кэш-памяти в разных машинах отличается именно стратегией выполнения записи.
Когда выполняется запись в кэш-память имеются две базовые возможности:
- сквозная запись (write through, store through) - информация
записывается в два места: в блок кэш-памяти и в блок более низкого уровня
памяти.
- запись с обратным копированием (write back, copy back, store in) - информация записывается
только в блок кэш-памяти. Модифицированный блок кэш-памяти записывается в
основную память только когда он замещается. Для сокращения частоты
копирования блоков при замещении обычно с каждым блоком кэш-памяти
связывается так называемый бит модификации (dirty bit). Этот бит состояния
показывает был ли модифицирован блок, находящийся в кэш-памяти. Если он не
модифицировался, то обратное копирование отменяется, поскольку более
низкий уровень содержит ту же самую информацию, что и кэш-память.
Оба подхода к организации записи
имеют свои преимущества и недостатки. При записи с обратным копированием
операции записи выполняются со скоростью кэш-памяти, и несколько записей в один
и тот же блок требуют только одной записи в память более низкого уровня.
Поскольку в этом случае обращения к основной памяти происходят реже, вообще
говоря требуется меньшая полоса пропускания памяти, что очень привлекательно
для мультипроцессорных систем. При сквозной записи промахи по чтению не влияют
на записи в более высокий уровень, и, кроме того, сквозная запись проще для
реализации, чем запись с обратным копированием. Сквозная запись имеет также
преимущество в том, что основная память имеет наиболее свежую копию данных. Это
важно в мультипроцессорных системах, а также для организации ввода/вывода.
Когда процессор ожидает
завершения записи при выполнении сквозной записи, то говорят, что он
приостанавливается для записи (write stall). Общий прием минимизации остановов по записи связан с
использованием буфера записи (write buffer), который позволяет процессору продолжить выполнение
команд во время обновления содержимого памяти. Следует отметить, что остановы
по записи могут возникать и при наличии буфера записи.
При промахе во время записи
имеются две дополнительные возможности:
- разместить запись в кэш-памяти (write allocate) (называется также
выборкой при записи (fetch on write)).
Блок загружается в кэш-память, вслед за чем выполняются действия
аналогичные выполняющимся при выполнении записи с попаданием. Это похоже
на промах при чтении.
- не размещать запись в кэш-памяти (называется также записью
в окружение (write around)). Блок модифицируется на более низком уровне и
не загружается в кэш-память.
Обычно в кэш-памяти, реализующей
запись с обратным копированием, используется размещение записи в кэш-памяти (в
надежде, что последующая запись в этот блок будет перехвачена), а в кэш-памяти
со сквозной записью размещение записи в кэш-памяти часто не используется
(поскольку последующая запись в этот блок все равно пойдет в память).
Стратегия
размещения.
На сложность этого механизма
существенное влияние оказывает
стратегия размещения, определяющая, в какое место кэш-памяти
следует поместить каждый блок из основной памяти.
В зависимости от способа размещения данных основной памяти в кэш-памяти
существует три типа кэш-памяти:
-
кэш с прямым отображением (размещением);
-
полностью ассоциативный кэш;
-
множественный ассоциативный кэш или частично-ассоциативный.
Кэш с прямым
отображением (размещением) является самым
простым типом буфера. Адрес памяти однозначно определяет строку
кэша, в которую будет помещен блок информации. При этом предпо-
лагается, что оперативная память разбита на блоки и каждому та-
кому блоку в буфере отводится всего одна строка. Это простой и недорогой в
реализации способ отображения. Основной его недостаток – жесткое закрепление за
определенными блоками ОП одной строки в кэше. Поэтому, если программа
поочередно обращается к словам из двух различных блоков, отображаемых на одну и
ту же строку кэш-памяти, постоянно будет происходить обновление данной строки и
вероятность попадания будет
низкой.
Кэш с полностью
ассоциативным отображением позволяет преодолеть недостаток прямого,
разрешая загрузку любого блока ОП в любую строку кэш-памяти. Логика управления
выделяет в адресе ОП два поля: поле тега и поле слова. Поле тега совпадает с
адресом блока ОП. Для проверки наличия копии блока в кэш-памяти, логика
управления кэша должна одновременно проверить теги всех строк на совпадение с
полем тега адреса. Ассоциативное отображение обеспечивает гибкость при выборе
строки для вновь записываемого блока. Принципиальный недостаток этого способа
в необходимости использования дорогой ассоциативной
памяти.
Множественно-ассоциативный
тип или частично-ассоциативный тип отображения – это один из возможных
компромиссов, сочетающий достоинства прямого и ассоциативного способов.
Кэш-память ( и тегов и данных) разбивается на некоторое количество модулей.
Зависимость между модулем и блоками ОП такая же жесткая, как и при прямом
отображении. А вот размещение блоков по строкам модуля произвольное и для
поиска нужной строки в пределах модуля используется ассоциативный принцип. Этот
способ отображения наиболее широко распространен в современных
микропроцессорах.
Отображение секторов ОП в кэш-памяти.
Данный тип отображения применяется во всех современных ЭВМ
и состоит в том, что вся ОП разбивается на секторы, состоящие из фиксированного
числа последовательных блоков. Кэш-память также разбивается на секторы,
содержащие такое же количество строк. Расположение блоков в секторе ОП и
секторе кэша полностью совпадает. Отображение сектора на кэш-память
осуществляется ассоциативно, те любой сектор из ОП может быть помещен в любой
сектор кэша. Таким образом, в процессе работы АЛУ обращается в поисках
очередной команды к ОП, в результате чего, в кэш загружается( в случае
отсутствия там блока, содержащего эту команду), целый сектор информации из ОП,
причем по принципу локальности, за счет этого достигается значительное
увеличение быстродействия системы.
Иерархическая модель
кэш-памяти
Как правило, кэш-память имеет
многоуровневую архитектуру. Например, в компьютере с 32 Кбайт внутренней (в
ядре ЦП) и 1 Мбайт внешней (в корпусе ЦП или на системной плате) кэш-памяти
первая будет считаться кэш-памятью 1-го уровня (L1), а
вторая - кэш-памятью 2-го уровня (L2). В современных
серверных системах количество уровней кэш-памяти может доходить до четырех,
хотя наиболее часто используется двух- или трехуровневая схема.
В некоторых процессорных
архитектурах кэш-память 1-го уровня разделена на кэш команд (Instruction Cache, I-cache) и кэш данных (Data Cache, D-cache), причем необязательно одинаковых размеров. С точки
зрения схемотехники проще и дешевле проектировать раздельные I-cache и D-cache:
выборку команд проводит I-box,
а выборку данных - Е-box и F-box, хотя в обоих случаях задействуются А-box
и С-box. Все эти блоки велики, и обеспечить им
одновременный и быстрый доступ к одному кэшу проблематично. Кроме того, это
неизбежно потребовало бы увеличения количества портов доступа, что также
усложняет задачу проектирования.
Так как I-cache и D-cache
должны обеспечивать очень низкие задержки при доступе (это справедливо для
любого кэша L1), приходится жертвовать их объемом -
обычно он составляет от 16 до 32 Кбайт. Ведь чем меньше размер кэша, тем легче
добиться низких задержек при доступе.
Кэш-память 2-го уровня, как
правило, унифицирована, т. е. может содержать как команды, так и данные. Если
она встроена в ядро ЦП, то говорят о S-cache (Secondary Cache, вторичный кэш), в противном случае - о B-cache (Backup Cache, резервный кэш). В современных
серверных ЦП объем S-cache
составляет от одного до нескольких мегабайт, a B-cache - до
64 Мбайт. Если дизайн ЦП предусматривает наличие встроенной кэш-памяти 3-го
уровня, то ее именуют T-cache (Ternary Cache,
третичный кэш). Как правило, каждый последующий уровень кэш-памяти медленнее,
но больше предыдущего по объему. Если в системе присутствует B-cache (как последний уровень модели кэш-памяти), то он может
контролироваться как ЦП, так и набором системной логики.
Если в момент выполнения
некоторой команды в регистрах не окажется данных для нее, то они будут
затребованы из ближайшего уровня кэш-памяти, т. е. из D-cache. В случае их отсутствия в D-Cache запрос направляется в S-cache и т. д. В худшем случае данные будут доставлены
непосредственно из памяти. Впрочем, возможен и еще более печальный вариант,
когда подсистема управления виртуальной памятью операционной системы (ОС)
успевает вытеснить их в файл подкачки на жесткий диск. В случае доставки из
оперативной памяти потери времени на получение нужных данных могут составлять
от десятков до сотен тактов ЦП, а в случае нахождения данных на жестком диске
речь уже может идти о миллионах тактов.
Ассоциативность
кэш-памяти
Одна из фундаментальных
характеристик кэш-памяти - уровень ассоциативности - отображает ее логическую
сегментацию. Дело в том, что последовательный перебор всех строк кэша в поисках
необходимых данных потребовал бы десятков тактов и свел бы на нет весь выигрыш
от использования встроенной в ЦП памяти. Поэтому ячейки ОЗУ жестко
привязываются к строкам кэш-памяти (в каждой строке могут быть данные из
фиксированного набора адресов), что значительно сокращает время поиска. С
каждой ячейкой ОЗУ может быть связано более одной строки кэш-памяти: например, n-канальная ассоциативность (n-way set associative) обозначает, что
информация по некоторому адресу оперативной памяти может храниться в п мест
кэш-памяти.
Выбор места может проводиться по
различным алгоритмам, среди которых чаще всего используются принципы замещения LRU (Least Recently Used,
замещается запись, запрошенная в последний раз наиболее давно) и LFU (Least Frequently Used,
запись, наименее часто запрашиваемая), хотя существуют и модификации этих
принципов. Например, полностью ассоциативная кэшпамять (fully associative), в которой информация,
находящаяся по произвольному адресу в оперативной памяти, может быть размещена
в произвольной строке. Другой вариант - прямое отображение (direct mapping), при котором информация,
которая находится по произвольному адресу в оперативной памяти, может быть размещена
только в одном месте кэш-памяти. Естественно, этот вариант обеспечивает
наибольшее быстродействие, так как при проверке наличия информации контроллеру
придется "заглянуть" лишь в одну строку кэша, но и наименее
эффективен, поскольку при записи контроллер не будет выбирать
"оптимальное" место. При одинаковом объеме кэша схема с полной
ассоциативностью будет наименее быстрой, но наиболее эффективной.
Полностью ассоциативный кэш
встречается на практике, но, как правило, у него очень небольшой объем. Например,
в ЦП Cyrix 6x86 использовалось
256 байт такого кэша для команд перед унифицированным 16-или 64-Кбайт кэшем L1. Часто полноассоциативную схему применяют при
проектировании TLB (о них будет рассказано ниже), кэшей
адресов переходов, буферов чтения-записи и т. д. Как правило, уровни
ассоциативности I-cache и D-cache довольно низки (до четырех
каналов) - их увеличение нецелесообразно, поскольку приводит к увеличению
задержек доступа и в итоге негативно отражается на производительности. В
качестве некоторой компенсации увеличивают ассоциативность S-cache (обычно до 16 каналов), так как задержки при доступе к
этому кэшу неважны. Например, согласно результатам исследований часто
используемых целочисленных задач, у Intel Pentium III 16 Кбайт четырехканального D-cache было достаточно для покрытия около 93% запросов, а
16-Кбайт четырехканального I-cache
- 99% запросов.
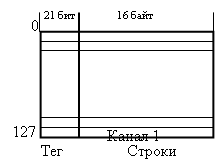
Размер строки и тега
кэш-памяти
Немаловажная характеристика
кэш-памяти - размер строки. Как правило, на одну строку полагается одна запись
адреса (так называемый тег), которая указывает, какому адресу в оперативной
памяти соответствует данная линия. Очевидно, что нумерация отдельных байтов
нецелесообразна, поскольку в этом случае объем служебной информации в кэше в
несколько раз превысит объем самих данных. Поэтому один тег обычно полагается
на одну строку, размер которой обычно 32 или 64 байта (реально существующий
максимум 1024 байта), и эквивалентен четырем (иногда восьми) разрядностям
системной шины данных. Кроме того, каждая строка кэш-памяти сопровождается
некоторой информацией для обеспечения отказоустойчивости: одним или несколькими
битами контроля четности (parity) или восемью и более
байтами обнаружения и коррекции ошибок (ЕСС, Error Checking and Correcting),
хотя в массовых решениях часто не используют ни того, ни другого.
Размер тега кэш-памяти зависит от
трех основных факторов: объема кэш-памяти, максимального кэшируемого объема
оперативной памяти, а также ассоциативности кэш-памяти. Математически этот
размер рассчитывается по формуле:
Stag=log2(Smem*A/Scache),
где Stag - размер одного тега
кэш-памяти, в битах; Smem - максимальный кэшируемый
объем оперативной памяти, в байтах; Scache - объем
кэш-памяти, в байтах; А - ассоциативность кэш-памяти, в каналах.
Отсюда следует, что для системы с
1-Гбайт оперативной памятью и 1-Мбайт кэш-памятью с двухканальной
ассоциативностью потребуется 11 бит для каждого тега. Примечательно, что
собственно размер строки кэш-памяти никак не влияет на размер тега, но обратно
пропорционально влияет на количество тегов. Следует понимать, что размер строки
кэш-памяти не имеет смысла делать меньше разрядности системной шины данных, но
многократное увеличение размера приведет к чрезмерному засорению кэш-памяти
ненужной информацией и излишней нагрузке на системную шину и шину памяти. Кроме
того, максимально кэшируемый объем кэш-памяти не обязан соответствовать
максимально возможному устанавливаемому объему оперативной памяти в системе.
Если возникнет ситуация, когда оперативной памяти окажется больше, чем может
быть кэшировано, то в кэш-памяти будет присутствовать информация только из
нижнего сегмента оперативной памяти. Именно такой была ситуация с платформой Socket7/Super7. Наборы микросхем для
этой платформы позволяли использовать большие объемы оперативной памяти (от 256
Мбайт до 1 Гбайт), в то время как кэшируемый объем часто был ограничен первыми
64 Мбайт (речь идет о B-cache,
находящемся на системной плате) по причине использования дешевых 8-бит
микросхем теговой SRAM (2 бита из которых
резервировалось под указатели действительности и измененности строки). Это
приводило к ощутимому падению производительности.
Какая информация содержится в
тегах кэш-памяти? Это информация об адресах, но как можно точно отобразить
расположение строки кэш-памяти на всем пространстве кэшируемого объема
оперативной памяти, используя столь незначительное количество адресных битов?
Это понятие является фундаментальным в понимании принципов функционирования
кэш-памяти. Рассмотрим предыдущий пример, с 11-бит тегами. Учитывая логическое
сегментирование благодаря двухканальной ассоциативности, можно рассматривать
данную кэш-память как состоящую из двух независимых сегментов по 512 Кбайт
каждый. Представим оперативную память как состоящую из "страниц" по
512 Кбайт каждая - их будет соответственно 2048 штук. Далее, Iog2
(2048) = 11 (основание логарифма равно 2, так как возможны только два
логических состояния каждого бита). Это означает, что фактически тег - не номер
отдельной строки кэш-памяти, а номер "страницы" памяти, на которую
отображается та или иная строка. Другими словами, в пределах
"страницы" сохраняется прямое соответствие ее "строк" с
соответствующими строками кэш-памяти, т. е. п-я строка кэш-памяти соответствует
n-й "строке" данной "страницы"
оперативной памяти.
Рассмотрим механизм работы
кэш-памяти разных видов ассоциативности. Допустим, имеется абстрактная модель с
восемью строками кэш-памяти и 64 эквивалентными строками оперативной памяти.
Требуется поместить в кэш строку 9 оперативной памяти (заметим, что все строки
нумеруются от нуля и по возрастающей). В модели с прямым отображением эта
строка может занять только одно место: 9 mod 8=1
(вычисление остатка от деления нацело), т. е. место строки 1. Если взять модель
с двухканальной ассоциативностью, то эта строка может занять одно из двух мест:
9 mod 4=1, т. е. строку 1 любого канала (сегмента).
Полноассоциативная модель предоставляет свободу для размещения, и данная строка
может занять место любой из восьми имеющихся. Другими словами, фактически
имеется 8 каналов, каждый из которых состоит из 1 строки.
Ни одна из вышеуказанных моделей
не позволит, разумеется, поместить в кэш больше строк, чем он физически в
состоянии разместить, они лишь предлагают различные варианты, различающиеся
балансом эффективности использования кэша и скорости доступа к нему.
Типы подключения
кэш-памяти
Количество портов чтения-записи
кэш-памяти - показатель того, сколько одновременных операций чтения-записи
может быть обработано. Хотя жестких требований и нет, определенное соответствие
набору функциональных устройств ЦП должно прослеживаться, так как отсутствие
свободного порта во время исполнения команды приведет к вынужденному простою.
Существует два основных способа
подключения кэшпамяти к ЦП для чтения: сквозной и побочный (Look-Through и Look-Aside).
Суть первого в том, что при необходимости данные сначала запрашиваются у
контроллера кэш-памяти самого высокого уровня, который проверяет состояние
подключенных тегов и возвращает либо нужную информацию, либо отрицательный
ответ, и в этом случае запрос перенаправляется в более низкий уровень иерархии
кэш-памяти или в оперативную память. При реализации второго способа чтения
запрос одновременно направляется как кэш-контроллеру самого высокого уровня,
так и остальным кэш-контроллерам и контроллеру оперативной памяти. Недостаток
первого способа очевиден: при отсутствии информации в кэше высокого уровня
приходится повторять запрос, и время простоя ЦП увеличивается. Недостаток
второго подхода - высокая избыточность операций и, как следствие, "засорение"
внутренних шин ЦП и системной шины ненужной информацией. Логично предположить,
что если для кэшей L1 оптимальна сквозная схема, то для
T-cache или B-cache побочная схема может оказаться более выгодной. Для S-cache выбор неоднозначен.
Различают также локальный и
удаленный кэш. Локальным называют кэш, находящийся либо в ядре ЦП, либо на той
же кремниевой подложке или в корпусе ЦП, удаленным - размещенный на системной
плате. Соответственно локальным кэшем управляет контроллер в ядре ЦП, а
удаленным - НМС системной платы. Локальный кэш с точки зрения быстродействия
предпочтительнее, так как интерфейс к удаленному кэшу обычно мультиплексируется
с системной шиной. С одной стороны, когда другой ЦП захватывает общую системную
шину или какой-либо периферийный контроллер обращается к памяти напрямую,
удаленный кэш может оказаться временно недоступным. С другой - такой кэш легче
использовать в многопроцессорных системах.
Существуют два распространенных
способа записи в кэш: сквозной (Write-Through)
и обратной (Write-Back) записи.
В первом случае информация одновременно сохраняется как в текущий, так и в
более низкий уровень иерархии кэш-памяти (или прямо в оперативную память при
отсутствии такового). Во втором - данные сохраняются только в текущем уровне
кэш-памяти, при этом возникает ситуация, когда информация в кэше и оперативной
памяти различается, причем последняя становится устаревшей. Для того чтобы при
сбросе кэша информация не была необратимо потеряна, к каждой строке кэша
добавляется "грязный" бит (dirty bit, иначе известный как modified). Он нужен для обозначения того, соответствует ли
информация в кэше информации в оперативной памяти, и следует ли ее записать в
память при сбросе кэша.
Также следует упомянуть способ
резервирования записи (write allocation). При записи данных в оперативную память часто
возникает ситуация, когда записываемые данные могут скоро понадобиться, и тогда
их придется довольно долго подгружать. Резервирование записи позволяет частично
решить эту проблему: данные записываются не в оперативную память, а в кэш.
Строка кэша, вместо которой записываются данные, полностью выгружается в
оперативную память. Так как вновь записанных данных обычно недостаточно для
формирования полной строки кэша, из оперативной памяти запрашивается
недостающая информация. Когда она получена, новая строка записывается, и тег
обновляется. Определенных преимуществ или недостатков такой подход не имеет -
иногда это может дать незначительный прирост производительности, но также и
привести к засорению кэша ненужной информацией.
Сегментирование
кэш-памяти и быстродействие жестких дисков
В первой части данного обзора мы
познакомились с режимом Performance Mode у SCSI-дисков Seagate Cheetah со скоростью вращения 10 000
и 15 000 об./мин — Cheetah 10K.7
и Cheetah 15K.4. Напомню, что
утилита Seagate SeaTools Enterprise
позволяет пользователю управлять политикой кэширования и, в частности,
переключать новейшие SCSI-диски Seagate
между двумя разными моделями кэширования — Desktop Mode и Server Mode. Этот пункт в меню SeaTools носит название Performance Mode (PM) и
может принимать два значения — On (Desktop Mode) и Off
(Server Mode).
Отличия между этими двумя режимами чисто программные — в случае Desktop Mode
кэш-память жесткого диска разбивается на фиксированное число сегментов
постоянного (одинакового) объема и далее они используются для кэширования
обращений при чтении и записи. Причем, в отдельном пункте меню пользователь
даже может сам назначать количество сегментов (управлять сегментированием
кэша): например, вместо дефолтных 32-х сегментов проставить другое значение
(при этом объем каждого сегмента пропорционально уменьшится).
В случае же Server Mode сегменты буфера (кэша диска)
могут динамически (пере)назначаться, меняя при этом свой размер и количество.
Микропроцессор (и микропрограмма) диска сами динамически оптимизируют
количество (и емкость) сегментов кэш-памяти в зависимости от поступающих для
исполнения на диск команд.
Тогда мы смогли выяснить, что
использование новых накопителей Seagate Cheetah в режиме «Desktop»
(при фиксированном сегментировании по умолчанию — на 32 сегмента) вместо
дефолтного «Server» с динамическим сегментированием
способно немного поднять производительность дисков в ряде задач, более
характерных для настольного компьютера или медиа-серверов. Причем, эта прибавка
порой может достигать 30-100% (!) в зависимости от типа задачи и модели диска,
хотя в среднем она оценивается величиной 30%, что, согласитесь, тоже неплохо.
Среди таких задач — рутинная работа настольного ПК (тесты WinBench,
PCmark, H2bench),
чтение и копирование файлов, дефрагментация. При этом в чисто серверных
приложениях производительность накопителей почти не падает (если и падает, то
незначительно). Впрочем, заметный выигрыш от использования Desktop Mode мы смогли наблюдать только на
диске Cheetah 10K.7, тогда как
ее старшей сестрице Cheetah 15K.4
оказалось почти все равно, в каком из режимов работать над настольными
приложениями.
Пытаясь разобраться дальше, как
влияет сегментирование кэш-памяти этих жестких дисков на производительность в
различных приложениях и какие режимы сегментирования (какое количество
сегментов памяти) более выгодно при выполнении тех или иных задач, я исследовал
влияние количества сегментов кэш-памяти на производительность диска Seagate Cheetah
15K.4 в широком диапазоне значений — от 4 до 128
сегментов (4, 8, 16, 32, 64 и 128). Результаты этих исследований и предлагаются
вашему вниманию в этой части обзора. Подчеркну, что данные результаты интересны
не только сугубо для этой модели дисков (или SCSI-дисков
Seagate в целом) — сегментирование кэш-памяти и выбор
количества сегментов — это одно из основных направлений оптимизации firmware, в том числе, настольных дисков с интерфейсом ATA, которые сейчас также оснащаются преимущественно буфером
8 Мбайт. Поэтому описанные в данной статье результаты производительности
накопителя в различных задачах в зависимости от сегментирования его кэш-памяти
имеют отношение и к индустрии настольных ATA-накопителей.
А поскольку методика испытаний была описана в первой части, переходим
непосредственно к самим результатам.
Впрочем, прежде, чем перейти к
обсуждению результатов, взглянем чуть подробнее на устройство и работу
сегментов кэш-памяти диска Seagate Cheetah 15K.4, чтобы лучше понимать,
о чем идет речь. Из восьми мегабайт для собственно кэш-памяти (то есть для
кэширующих операций) здесь доступно 7077 Кбайт (остальное — служебная область).
Эта область делится на логические сегменты (Mode Select Page 08h, byte
13), которые используются для чтения и записи данных (для осуществления функций
упреждающего чтения с пластин и отложенной записи на поверхность диска). Для
обращения к данным на магнитных пластинах сегменты используют именно логическую
адресацию блоков накопителя. Диски этой серии поддерживают максимум 64 сегмента
кэш-памяти, причем длина каждого сегмента равна целому числу секторов диска.
Объем доступной кэш-памяти, по всей видимости, распределяется поровну между
сегментами, то есть если сегментов, скажем, 32, то объем каждого сегмента равен
примерно 220 Кбайт. При динамической сегментации (в режиме PM=off) количество сегментов может меняться винчестером
автоматически в зависимости от потока команд от хоста.
Приложения для серверов и
настольных компьютеров требуют различных операций кэширования от дисков для
обеспечения оптимальной производительности, поэтому сложно обеспечить единую
конфигурацию для наилучшего выполнения этих задач. По мнению Seagate,
для «настольных» приложений требуется сконфигурировать кэш-память так, чтобы
быстро отвечать на повторяющиеся запросы большого количества небольших
сегментов данных без задержек на упреждающее чтение смежных сегментов. В
серверных задачах, напротив, требуется так сконфигурировать кэш, чтобы
обеспечить поступление больших объемов последовательных данных в
неповторяющихся запросах. В этом случае более важна способность кэш-памяти
хранить больше данных из смежных сегментов при упреждающем чтении. Поэтому для Desktop Mode
производитель рекомендует использовать 32 сегмента (в ранних версиях Cheetah использовались 16 сегментов), а для Server Mode адаптивное количество сегментов
стартует всего с трех на весь кэш, хотя в процессе работы может и
увеличиваться. Мы в своих экспериментах по поводу влияния количества сегментов
на производительность в различных приложениях ограничимся диапазоном от 4
сегментов до 64 сегментов, а в качестве проверки «прогоним» диск также при 128
сегментах, установленных в программе SeaTools Enterprise (программа при этом не
сообщает, что данное количество сегментов в этом диске недопустимо).
Увеличение
производительности кэш-памяти
Формула для среднего времени
доступа к памяти в системах с кэш-памятью выглядит следующим образом:
Среднее время доступа = Время обращения при попадании + Доля
промахов x Потери при промахе
Эта формула наглядно показывает
пути оптимизации работы кэш-памяти: сокращение доли промахов, сокращение потерь
при промахе, а также сокращение времени обращения к кэш-памяти при попадании.
На рисунке 5.38 кратко представлены различные методы, которые используются в
настоящее время для увеличения производительности кэш-памяти. Использование тех
или иных методов определяется прежде всего целью разработки, при этом
конструкторы современных компьютеров заботятся о том, чтобы система оказалась
сбалансированной по всем параметрам.
Зачем увеличивать кэш ?
Первичная
причина увеличения объема встроенного кэша может заключаться в том, что
кэш-память в современных процессорах работает на той же скорости, что и сам
процессор. Частота процессора в этом случае никак не меньше 3200 MГц.
Больший объем кэша позволяет процессору держать большие части кода готовыми к
выполнению. Такая архитектура процессоров сфокусирована на уменьшении задержек,
связанных с простоем процессора в ожидании данных. Современные программы, в том
числе игровые, используют большие части кода, который необходимо извлекать из
системной памяти по первому требованию процессора. Уменьшение промежутков
времени, уходящих на передачу данных от памяти к процессору, - это надежный
метод увеличения производительности приложений, требующих интенсивного взаимодействия
с памятью. Кэш L3 имеет немного более высокое время
ожидания, чем L 1 и 2, это вполне естественно. Хоть он и
медленнее, но все-таки он значительно более быстрый, чем обычная память. Не все
приложения выигрывают от увеличения объема или скорости кэш-памяти. Это сильно
зависит от природы приложения.
Если большой
объем встроенного кэша - это хорошо, тогда что же удерживало Intel
и AMD от этой стратегии ранее? Простым ответом является
высокая себестоимость такого решения. Резервирование пространства для кэша
очень дорого. Стандартный 3.2GHz Northwood содержит 55 миллионов транзисторов. Добавляя 2048 КБ
кэша L3, Intel идет на увеличение
количества транзисторов до 167 миллионов. Простой математический расчет покажет
нам, что EE - один из самых дорогих процессоров.
Сайт AnandTech провел сравнительное тестирование двух систем, каждая
из которых содержала два процессора – Intel Xeon 3,6 ГГц в одном случае и AMD Opteron 250 (2,4 ГГц) – в другом.
Тестирование проводилось для приложений ColdFusion MX 6.1, PHP 4.3.9, и Microsoft .NET 1.1. Конфигурации выглядели
следующим образом:
AMD
-
Dual Opteron 250;
-
2 ГБ DDR PC3200 (Kingston KRX3200AK2);
- системная плата Tyan K8W;
-
ОС Windows 2003 Server Web Edition (32 бит);
-
1 жесткий IDE 40 ГБ 7200 rpm, кэш 8 МБ
Intel
-
Dual Xeon 3.6 ГГц;
- 2 ГБ DDR2;
- материнская плата Intel SE7520AF2;
-
ОС Windows 2003 Server Web Edition (32 бит);
-
1 жесткий IDE 40 ГБ 7200 rpm, кэш 8 МБ
На приложениях
ColdFusion и PHP, не оптимизированных
под ту или иную архитектуру, чуть быстрее (2,5-3%) оказались Opteron’ы,
зато тест с .NET продемонстрировал последовательную
приверженность Microsoft платформе Intel,
что позволило паре Xeon’ов вырваться вперед на 8%. Вывод
вполне очевиден: используя ПО Microsoft для веб-приложений,
есть смысл выбрать процессоры Intel, в других случаях
несколько лучшим выбором будет AMD.
Больше
не всегда лучше
Частота промахов
при обращении к кэш-памяти может быть значительно снижена за счет увеличения
емкости кэша. Но большая кэш-память требует больше энергии, генерирует больше
тепла и увеличивает число бракованных микросхем при производстве.
Один из способов
обойти эти трудности — передача логики управления кэш-памятью от аппаратного
обеспечения к программному.
«Компилятор
потенциально в состоянии анализировать поведение программы и генерировать
команды по переносу данных между уровнями памяти», — отметил Шен.
Управляемая
программным образом кэш-память сейчас существует лишь в исследовательских
лабораториях. Возможные трудности связаны с тем, что придется переписывать
компиляторы и перекомпилировать унаследованный код для всех процессоров нового
поколения.
Выводы
Анализ
изложенного выше материала позволяет сделать заключение, что в соответствии с
каноническими теориями, современные производители широко используют кэш-память
при построении новейших процессоров. Во многом, их превосходные характеристики
по быстродействию достигаются именно благодаря применению кэш-памяти второго и
даже третьего уровня. Этот факт подтверждает теоретические выкладки
Гарвардского университета о том, что ввиду действия принципа локальности
информации в современных компьютерах применение кэш-памяти смешанного типа
позволяет добиться превосходных результатов в производительности процессоров и
снижает частоту необходимых обращений к основной памяти.
Налицо широкие
перспективы дальнейшего применения кэш-памяти в машинах нового поколения,
однако существующая проблематика невозможности бесконечного увеличения кэша, а
также высокая себестоимость изготовления кэша на одном кристалле с процессором,
ставит перед конструкторами вопросы о некоем качественном, а не количественном
видоизменении или скачке в принципах, либо огранизации кэш-памяти в процессорах
будущего.
Дефрагментация
диска
Дефрагментатор
дисков выполняет поиск фрагментированных файлов и папок на локальных томах.
Фрагментированные файл или папка разделены на множество частей и разбрасаны по
всему тому.
Если
том содержит много фрагментированных файлов и папок, системе требуется большее
время для обращения к ним, поскольку приходится выполнять дополнительные
операции чтения с диска их отдельных частей. На создание файлов и папок также
уходит больше времени, поскольку свободное пространство на диске состоит из
разрозненных фрагментов. Системе приходится сохранять новые файлы и папки в
разных местах тома.
Дефрагментатор
дисков перемещает разрозненные части каждого файла или папки в одно место тома,
после чего файлы и папки занимают на диске единое последовательное
пространство. В результате доступ к файлам и папкам выполняется эффективнее.
Объединяя отдельные части файлов и папок, программа дефрагментации также
объединяет в единое целое свободное место на диске, что делает менее вероятной
фрагментацию новых файлов.
Процесс
поиска и объединения фрагментированных файлов и папок называется
дефрагментацией. Время, необходимое для дефрагментации тома, зависит от
нескольких факторов, в том числе от его размера, общего числа файлов, степени
фрагментации и доступных системных ресурсов. Перед выполнением дефрагментации
можно найти все фрагментированные файлы и папки, проанализировав том.
Полученные сведения позволят узнать, как много фрагментированных файлов и папок
содержит том, и решить, следует ли выполнять дефрагментацию.
С
помощью программы дефрагментации можно преобразовать тома, использующие
файловые системы FAT, FAT32 и NTFS.
Для запуска
программы дефрагментации диска необходимо через кнопки ПУСК, ПРОГРАММЫ,
СТАНДАРТНЫЕ выйти на панель СЛУЖЕБНЫЕ
и запустить ДЕФРАГМЕНТАЦИЯ ДИСКА.
Рис.
1.1. Общий вид панели дефрагментации.
Целями
дефрагментации дисков являются:
- анализ состояния каталогов и файлов на
диске;
- выполнение операций перезаписи информации в
интересах увеличения объема сплошных областей свободного пространства.
Для проведения
фрагментации следует выбрать любой из дисков кроме системного.
Непосредственно
перед дефрагментацией необходимо провести анализ выбранного диска и получить
отчет о работе программы анализа.
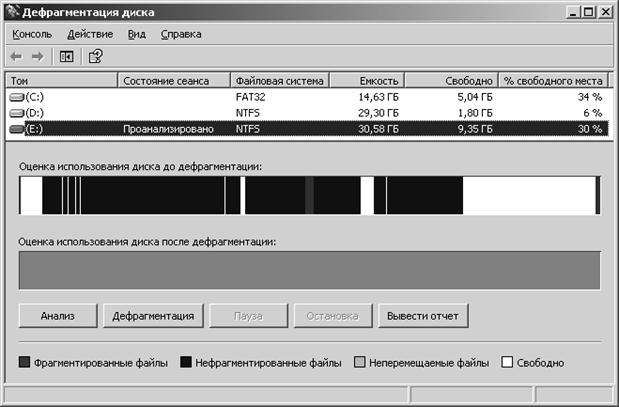
Рис.
1.2. Панель дефрагментации с результатами анализа диска.
В результате
анализа на панели дефрагментации отображается распределение:
- Фрагментированной
- Нефрагментированной
- Системной информации
- Свободных областей памяти.
Далее запускается программа дефрагментации и
выводится отчет о ее работе.
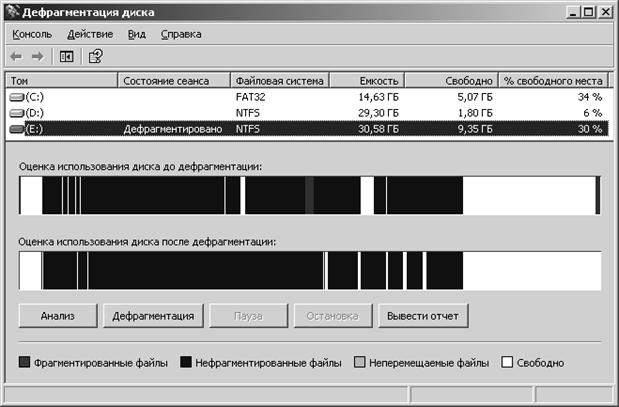
Рис.
1.3. Панель дефрагментации с отчетом
Далее следуют
отчеты результатов анализа и дефрагментации диска Е:
Том (E:) до дефрагментации:
Размер тома = 30,58 ГБ
Размер кластера = 4 КБ
Занято = 21,23 ГБ
Свободно = 9,35 ГБ
Процент свободного места = 30 %
Фрагментация тома
Всего фрагментировано = 1 %
Фрагментация файлов = 3 %
Фрагментация свободного места = 0 %
Фрагментация файлов
Всего файлов = 6 720
Средний размер файла = 4 МБ
Всего фрагментировано файлов = 23
Всего лишних фрагментов = 105
В среднем фрагментов на файл = 1,01
Фрагментация файла подкачки
Размер файла подкачки = 0 байт
Всего фрагментов = 0
Фрагментация папок
Всего папок = 307
Фрагментировано папок = 39
Лишних фрагментов папок = 317
Фрагментация MFT (Master File Table)
Общий размер MFT = 26 МБ
Счетчик записей MFT = 7 049
Процент использования MFT = 26 %
Всего фрагментов MFT = 2
--------------------------------------------------------------------------------
Фрагментов Размер файла Наиболее фрагментированные файлы
44 180 КБ \Need for Speed Most Wanted\SOUND\ENGINE
31 7 МБ \System Volume
Information\RP32\A0020244.exe
29 120 КБ \age of mythology\Eng\history\units
29 120 КБ \age of mythology\locale\history\units
28 116 КБ \age of mythology\Eng\history\techs
28 116 КБ \age of mythology\locale\history\techs
25 108 КБ \Need for Speed Most Wanted\TRACKS\L2RA
11 44 КБ \2\Katjuha 2005
10 625 КБ \System Volume
Information\RP32\A0020265.exe
10 69 КБ \Thumbs.db
9 548 КБ \System Volume
Information\RP32\A0020243.exe
9 40 КБ \Need for Speed Most Wanted\NIS
8 36 КБ \Need for Speed Most Wanted\European Help
Files\Sv
8 36 КБ \Need for Speed Most Wanted\European Help
Files\pt-br
8 36 КБ \Need for Speed Most Wanted\European Help
Files\pt
8 36 КБ \Need for Speed Most Wanted\European Help
Files\NL
8 126 КБ \System Volume
Information\RP34\change.log.2
8 36 КБ \Need for Speed Most Wanted\European Help
Files\Da
8 36 КБ \Need for Speed Most Wanted\European Help
Files\en-uk
8 36 КБ \Need for Speed Most Wanted\European Help
Files\De
8 36 КБ \Need for Speed Most Wanted\European Help
Files\fr-fr
8 36 КБ \Need for Speed Most Wanted\European Help
Files\Fi
8 36 КБ \Need for Speed Most Wanted\European Help
Files\es
7 32 КБ \Need for Speed Most Wanted\EA Help
7 28 КБ \Need for Speed Most Wanted\CARS
7 60 КБ \2\@1@
6 372 КБ \System Volume
Information\RP32\A0020250.dll
6 336 КБ \System Volume
Information\RP32\A0020247.exe
6 64 КБ \2\@@@@
5 316 КБ \System Volume
Information\RP32\A0020241.exe
Том (E:) после дефрагментации:
Размер тома = 30,58 ГБ
Размер кластера = 4 КБ
Занято = 21,23 ГБ
Свободно = 9,35 ГБ
Процент свободного места = 30 %
Фрагментация тома
Всего фрагментировано = 0 %
Фрагментация файлов = 0 %
Фрагментация свободного места = 0 %
Фрагментация файлов
Всего файлов = 6 720
Средний размер файла = 4 МБ
Всего фрагментировано файлов = 0
Всего лишних фрагментов = 0
В среднем фрагментов на файл = 1,00
Фрагментация файла подкачки
Размер файла подкачки = 0 байт
Всего фрагментов = 0
Фрагментация папок
Всего папок = 307
Фрагментировано папок = 1
Лишних фрагментов папок = 0
Фрагментация MFT (Master File Table)
Общий размер MFT = 26 МБ
Счетчик записей MFT = 7 049
Процент использования MFT = 26 %
Всего фрагментов MFT = 2
--------------------------------------------------------------------------------
Фрагментов Размер файла Файлы, которые не могут быть
дефрагментированы
отсутствует
Вывод
Из отчетов
видно, что после дефрагментации диска Е: фрагментированных файлов не осталось.
Произошла полная дефрагментация диска.
Литература
1.
Э.Танненбаум,Современные
операционные системы, СПб: Питер, 2002. - 1024 с.
2.
Р.Столлинз Операционные
системы. М.: Вильямз, 2002. – 600 с.
3.
В.Г.Олифер, Н.А.Олифер
Сетевые операционные системы. СПб: Питер, 2001.- 554 с.
- А. Шоу.
Логическое проектирование операционніх систем. М.: „МИР”, 1981.- 360 с.
- Казарин О.В. Безопасность программного
обеспечения компьютерных систем. : Москва, МГУЛ, 2003, 212 с.
- Конспект лекций.
- Справочная
система Windows XP.
|