Информатика программирование : Дипломная работа: Исследование архитектуры современных микропроцессоров и вычислительных систем
Дипломная работа: Исследование архитектуры современных микропроцессоров и вычислительных систем
РЕФЕРАТ
Отчет о НИРС: 53 c., 28
рис., 5 источников
Объект исследования
архитектура современных микропроцессоров и вычислительных систем.
Цель работы – исследовать
архитектуру современных микропроцессоров и вычислительных систем, а также
сделать вывод о перспективах их развития.
В данной работе
рассмотрено множество различных классификаций архитектур вычислительных систем
по различным признакам, оценено нынешнее состояние исследований в области
архитектуры процессоров, а также дан прогноз этих исследований и достижений на
ближайшее время.
Основное внимание уделено
вопросам классификации архитектур вычислительных систем, признакам, по которым
эта классификация осуществляется, раскрытию понятий «микроархитектурный
уровень» и «мультитредовые системы».
В качестве примера
рассматриваются вычислительные системы таких производителей, как IBM, AMD, Sun
Microsystems, CRAY и других.
СОДЕРЖАНИЕ
Введение
1 Классификации
архитектур вычислительных систем
1.1 Классификация Флинна
1.2 Дополнения Ванга и
Бриггса к классификации Флинна
1.3 Классификация Фенга
1.4 Классификация Шора
1.5 Классификация
Хендлера
1.6 Классификация Хокни
1.7 Классификация
Шнайдера
1.8 Классификация
Джонсона
1.9 Классификация Базу
1.10 Классификация
Кришнамарфи
1.11 Классификация
Скилликорна
1.12 Классификация Дазгупты
1.13 Классификация
Дункана
2 Организация
компьютерных систем
2.1 Общие сведения
2.2 Устройство
центрального процессора
2.3 Выполнение команд
2.4 RISCи CISC
2.5 Принципы разработки
современных компьютеров
2.6 Параллелизм на уровне
команд
2.7 Параллелизм на уровне
процессоров
3 Эволюция
микропроцессорных систем
3.1 Основные направления
развития
3.2 Увеличение объема
внутрикристальной памяти
3.3 Увеличение числа и
состава функциональных устройств
3.4 Интеграция функций
3.5 Однокристальные
мультискалярные и мультитредовые системы
3.6 Направление эволюции
архитектуры микропроцессоров
Выводы
Список использованных
источников
ВВЕДЕНИЕ
Стремительное
развитие науки и проникновение человеческой мысли во все новые области вместе с
решением поставленных прежде проблем постоянно порождает поток вопросов и
ставит новые, как правило более сложные, задачи. Во времена первых компьютеров
казалось, что увеличение их быстродействия в 100 раз позволит решить
большинство проблем, однако гигафлопная производительность современных суперЭВМ
сегодня является явно недостаточной для многих ученых. Электро- и
гидродинамика, сейсморазведка и прогноз погоды, моделирование химических
соединений, исследование виртуальной реальности - вот далеко не полный список
областей науки, исследователи которых используют каждую возможность ускорить
выполнение своих программ.
Наиболее
перспективным и динамичным направлением увеличения скорости решения прикладных
задач является широкое внедрение идей параллелизма в работу вычислительных
систем. К настоящему времени спроектированы и опробованы сотни различных
компьютеров, использующих в своей архитектуре тот или иной вид параллельной
обработки данных. В научной литературе и технической документации можно найти
более десятка различных названий, характеризующих лишь общие принципы
функционирования параллельных машин: векторно-конвейерные,
массивно-параллельные, компьютеры с широким командным словом, систолические
массивы, гиперкубы, спецпроцессоры и мультипроцессоры, иерархические и
кластерные компьютеры, dataflow, матричные ЭВМ и многие другие. Если же к
подобным названиям для полноты описания добавить еще и данные о таких важных
параметрах, как, например, организация памяти, топология связи между
процессорами, синхронность работы отдельных устройств или способ исполнения
арифметических операций, то число различных архитектур станет и вовсе
необозримым.
Попытки
систематизировать все множество архитектур начались после опубликования
М.Флинном первого варианта классификации вычислительных систем в конце 60-х
годов и непрерывно продолжаются по сей день. Ясно, что навести порядок в хаосе
очень важно для лучшего понимания исследуемой предметной области, однако
нахождение удачной классификации может иметь целый ряд существенных следствий.
В самом деле,
вспомним открытый в 1869 году Д.И.Менделеевым периодический закон. Выписав на
карточках названия химических элементов и указав их важнейшие свойства, он
сумел найти такое расположение, при котором четко прослеживалась закономерность
в изменении свойств элементов, расположенных в каждом столбце и в каждой
строке. Теперь, зная положение какого-либо элемента в таблице, он мог с большой
степенью точности описывать его свойства, не проводя с ним никаких
непосредственных экспериментов. Другим, поистине фантастическим следствием,
явилось то, что данный закон сразу указал на несколько "белых пятен"
в таблице и позволил предсказать существование (!) и свойства (!!) неизвестных
до тех пор элементов. В 1875 году французский ученый Буабодран, изучая спектры
минералов, открыл предсказанный Менделеевым галлий и впервые подробно описал
его свойства. В свою очередь Менделеев, никогда прежде не видевший данного
химического элемента, не только смог указать на ошибку в определении плотности,
но и вычислил ее правильное значение.
Существующая
классификация растительного и животного мира, в отличие от периодического
закона, носит скорее описательный характер. С ее помощью намного сложнее
предсказывать существование нового вида, однако знание того, что исследуемый
экземпляр принадлежит такому-то роду/семейству/отряду/классу позволяет
оправданно предположить наличие у него вполне определенных свойств.
Подобную
классификацию хотелось бы найти и для архитектур параллельных вычислительных
систем. Основной вопрос - что заложить в основу классификации, может решаться
по-разному, в зависимости от того, для кого данная классификация создается и на
решение какой задачи направлена. Так, часто используемое деление компьютеров на
персональные ЭВМ, рабочие станции, мини--ЭВМ, большие универсальные ЭВМ,
минисупер-ЭВМ и супер-ЭВМ, позволяет, быть может, примерно прикинуть стоимость
компьютера. Однако она не приближает пользователя к пониманию того, что от него
потребуется для написания программы, работающий на пределе производительности
параллельного компьютера, т.е. того, ради чего он и решился его использовать.
Как это ни странно, но от обилия разных параллельных компьютеров страдает,
прежде всего, конечный пользователь, для которого, вроде бы, они и создавались:
он вынужден каждый раз подбирать наиболее эффективный алгоритм, он испытывает
на себе "прелести" параллельного программирования и отладки, решает
проблемы переносимости и затем все повторяется заново.
Хотелось бы,
чтобы такая классификация помогла ему разобраться с тем, что представляет собой
каждая архитектура, как они взаимосвязаны между собой, что он должен учитывать
для написания действительно эффективных программ или же на какой класс
архитектур ему следует ориентироваться для решения требуемого класса задач.
Одновременно удачная классификация могла бы подсказать возможные пути
совершенствования компьютеров и в этом смысле она должна быть достаточно
содержательной. Трудно рассчитывать на нахождение нетривиальных "белых
пятен", например, в классификации по стоимости, однако размышления о возможной
систематике с точки зрения простоты и технологичности программирования могут
оказаться чрезвычайно полезными для определения направлений поиска новых
архитектур.
В данной
работе не ставилась задача сразу предложить что-то конкретное. Она носит скорее
обзорный характер и ее основная задача - это собрать в одном месте накопленый к
настоящему времени материал. В работу включены не все найденные классификации,
а описаны лишь те, в которых впервые введены какие-либо новые существенные
понятия.
1 КЛАССИФИКАЦИИ
АРХИТЕКТУР ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
1.1 Классификация Флинна
По-видимому,
самой ранней и наиболее известной является классификация архитектур
вычислительных систем, предложенная в 1966 году М.Флинном. Классификация
базируется на понятии потока, под которым понимается последовательность
элементов, команд или данных, обрабатываемая процессором. На основе числа
потоков команд и потоков данных Флинн выделяет четыре класса архитектур:
SISD,MISD,SIMD,MIMD.
SISD (single instruction stream / single data stream) (рис. 1.1) -
одиночный поток команд и одиночный поток данных. К этому классу относятся,
прежде всего, классические последовательные машины, или иначе, машины
фон-неймановского типа. В таких машинах есть только один поток команд, все
команды обрабатываются последовательно друг за другом и каждая команда
инициирует одну операцию с одним потоком данных. Не имеет значения тот факт,
что для увеличения скорости обработки команд и скорости выполнения
арифметических операций может применяться конвейерная обработка.
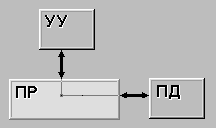
Рисунок 1.1
Архитектура SISD
SIMD (single instruction stream / multiple data stream) (рис.
1.2) - одиночный поток команд и множественный поток данных. В архитектурах
подобного рода сохраняется один поток команд, включающий, в отличие от
предыдущего класса, векторные команды. Это позволяет выполнять одну
арифметическую операцию сразу над многими данными - элементами вектора. Способ
выполнения векторных операций не оговаривается, поэтому обработка элементов
вектора может производится либо процессорной матрицей, как в ILLIAC IV, либо с
помощью конвейера, как, например, в машине CRAY-1.
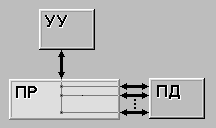
Рисунок 1.2
Архитектура SIMD
MISD (multiple instruction stream /
single data stream) (рис. 1.3) - множественный поток команд и одиночный поток
данных. Определение подразумевает наличие в архитектуре многих процессоров,
обрабатывающих один и тот же поток данных. Однако ни Флинн, ни другие
специалисты в области архитектуры компьютеров до сих пор не смогли представить
убедительный пример реально существующей вычислительной системы, построенной на
данном принципе. Ряд исследователей относят конвейерные машины к данному
классу, однако это не нашло окончательного признания в научном сообществе.
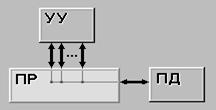
Рисунок 1.3 – Архитектура
MISD
MIMD (multiple instruction stream /
multiple data stream) (рис. 1.4) - множественный поток команд и множественный
поток данных. Этот класс предполагает, что в вычислительной системе есть
несколько устройств обработки команд, объединенных в единый комплекс и работающих
каждое со своим потоком команд и данных.
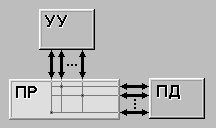
Рисунок 1.4 – Архитектура
MIMD
Итак, что же
собой представляет каждый класс? В SISD, как уже говорилось, входят
однопроцессорные последовательные компьютеры типа VAX 11/780. Однако, многими
критиками подмечено, что в этот класс можно включить и векторно-конвейерные
машины, если рассматривать вектор как одно неделимое данное для соответствующей
команды. В таком случае в этот класс попадут и такие системы, как CRAY-1, CYBER
205, машины семейства FACOM VP и многие другие.
Бесспорными
представителями класса SIMD считаются матрицы процессоров: ILLIAC IV, ICL DAP,
Goodyear Aerospace MPP, Connection Machine 1 и т.п. В таких системах единое
управляющее устройство контролирует множество процессорных элементов. Каждый
процессорный элемент получает от устройства управления в каждый фиксированный
момент времени одинаковую команду и выполняет ее над своими локальными данными.
Для классических процессорных матриц никаких вопросов не возникает, однако в
этот же класс можно включить и векторно-конвейерные машины, например, CRAY-1. В
этом случае каждый элемент вектора надо рассматривать как отдельный элемент
потока данных.
Класс MIMD
чрезвычайно широк, поскольку включает в себя всевозможные мультипроцессорные
системы: Cm*, C.mmp, CRAY Y-MP, Denelcor HEP, BBN Butterfly, Intel Paragon, CRAY T3D и многие другие. Интересно то, что
если конвейерную обработку рассматривать как выполнение множества команд
(операций ступеней конвейера) не над одиночным векторным потоком данных, а над
множественным скалярным потоком, то все рассмотренные выше векторно-конвейерные
компьютеры можно расположить и в данном классе.
Предложенная
схема классификации вплоть до настоящего времени является самой применяемой при
начальной характеристике того или иного компьютера. Если говорится, что
компьютер принадлежит классу SIMD или MIMD, то сразу становится понятным
базовый принцип его работы, и в некоторых случаях этого бывает достаточно.
Однако видны и явные недостатки. В частности, некоторые заслуживающие внимания
архитектуры, например dataflow и векторно-конвейерные машины, четко не вписываются
в данную классификацию. Другой недостаток - это чрезмерная заполненность класса
MIMD. Необходимо средство, более избирательно систематизирующее архитектуры,
которые по Флинну попадают в один класс, но совершенно различны по числу
процессоров, природе и топологии связи между ними, по способу организации
памяти и, конечно же, по технологии программирования.
Наличие
пустого класса (MISD) не стоит считать недостатком схемы. Такие классы, по
мнению некоторых исследователей в области классификации архитектур, могут стать
чрезвычайно полезными для разработки принципиально новых концепций в теории и
практике построения вычислительных систем.
1.2 Дополнения Ванга и Бриггса к классификации Флинна
В книге
К.Ванга и Ф.Бриггса сделаны некоторые дополнения к классификации Флинна.
Оставляя четыре ранее введенных базовых класса (SISD, SIMD, MISD, MIMD), авторы
внесли следующие изменения.
Класс SISD
разбивается на два подкласса:
-
архитектуры с
единственным функциональным устройством, например, PDP-11;
-
архитектуры,
имеющие в своем составе несколько функциональных устройств - CDC 6600, CRAY-1,
FPS AP-120B, CDC Cyber 205, FACOM VP-200.
В класс SIMD
также вводится два подкласса:
-
архитектуры с
пословно-последовательной обработкой информации - ILLIAC IV, PEPE, BSP;
-
архитектуры с
разрядно-последовательной обработкой - STARAN, ICL DAP.
В классе MIMD
авторы различают
-
вычислительные
системы со слабой связью между процессорами, к которым они относят все системы
с распределенной памятью, например, Cosmic Cube,
-
и вычислительные
системы с сильной связью (системы с общей памятью), куда попадают такие
компьютеры, как C.mmp, BBN Butterfly, CRAY Y-MP, Denelcor HEP.
1.3 Классификация Фенга
В 1972 году
Т.Фенг предложил классифицировать вычислительные системы на основе двух простых
характеристик. Первая - число бит n в машинном слове, обрабатываемых
параллельно при выполнении машинных инструкций. Практически во всех современных
компьютерах это число совпадает с длиной машинного слова. Вторая характеристика
равна числу слов m, обрабатываемых одновременно данной вычислительной системой.
Немного изменив терминологию, функционирование любого компьютера можно
представить как параллельную обработку n битовых слоев, на каждом из которых
независимо преобразуются m бит. Опираясь на такую интерпретацию, вторую
характеристику обычно называют шириной битового слоя.
Если
рассмотреть предельные верхние значения данных характеристик, то каждую
вычислительную систему C можно описать парой чисел (n,m) и представить точкой
на плоскости в системе координат длина слова - ширина битового слоя. Площадь
прямоугольника со сторонами n и m определяет интегральную характеристику
потенциала параллельности P архитектуры и носит название максимальной степени
параллелизма вычислительной системы: P(C)=mn. По существу, данное значение есть
ничто иное, как пиковая производительность, выраженная в других единицах. В
период появления данной классификации, а это начало 70-х годов, еще казалось
возможным перенести понятие пиковой производительности как универсального
средства сравнения и описания потенциальных возможностей компьютеров с
традиционных последовательных машин на параллельные. Понимание того факта, что
пиковая производительность сама по себе не столь важна, пришло позднее, и
данный подход отражает, естественно, степень осмысления специфики параллельных
вычислений того времени.
На основе
введенных понятий все вычислительные системы в зависимости от способа обработки
информации, заложенного в их архитектуру, можно разделить на четыре класса:
-
разрядно-последовательные
пословно-последовательные (n=m=1). В каждый момент времени такие компьютеры
обрабатывают только один двоичный разряд. Представителем данного класса служит
давняя система MINIMA с естественным описанием (1,1);
-
разрядно-параллельные
пословно-последовательные (n>1, m=1). Большинство классических
последовательных компьютеров, так же как и многие вычислительные системы,
эксплуатируемые до сих пор, принадлежит к данному классу: IBM 701 с описанием
(36,1), PDP-11 (16,1), IBM 360/50 и VAX 11/780 - обе с описанием (32,1);
-
разрядно-последовательные
пословно-параллельные (n=1, m>1). Как правило вычислительные системы данного
класса состоят из большого числа одноразрядных процессорных элементов, каждый
из которых может независимо от остальных обрабатывать свои данные. Типичными
примерами служат STARAN (1, 256) и MPP (1,16384) фирмы Goodyear Aerospace,
прототип известной системы ILLIAC IV компьютер SOLOMON (1, 1024) и ICL DAP (1,
4096);
-
разрядно-параллельные
пословно-параллельные (n>1, m>1). Большая часть существующих параллельных
вычислительных систем, обрабатывая одновременно mn двоичных разрядов,
принадлежит именно к этому классу: ILLIAC IV (64, 64), TI ASC (64, 32), C.mmp
(16, 16), CDC 6600 (60, 10), BBN Butterfly GP1000 (32, 256).
Недостатки
предложенной классификации достаточно очевидны и связаны со способом вычисления
ширины битового слоя m. По существу Фенг не делает никакого различия между
процессорными матрицами, векторно-конвейерными и многопроцессорными системами.
Не делается акцент на том, за счет чего компьютер может одновременно
обрабатывать более одного слова: множественности функциональных устройств, их
конвейерности или же какого-то числа независимых процессоров. Если в системе N
независимых процессоров имеют каждый по F конвейерных функциональных устройств
с длиной конвейера L, то для вычисления ширины битового слоя надо просто найти
произведение данных характеристик.
Конечно же,
опираясь на данную классификацию, достаточно трудно (а иногда и невозможно)
осознать специфику той или иной вычислительной системы. Однако достоинством
является введение единой числовой метрики для всех типов компьютеров, которая
вместе с описанием потенциала вычислительных возможностей конкретной
архитектуры позволяет сравнить любые два компьютера между собой.
1.4 Классификация Шора
Классификация Дж.Шора,
появившаяся в начале 70-х годов, интересна тем, что представляет собой попытку
выделения типичных способов компоновки вычислительных систем на основе
фиксированного числа базисных блоков: устройства управления,
арифметико-логического устройства, памяти команд и памяти данных. Дополнительно
предполагается, что выборка из памяти данных может осуществляться словами, то
есть выбираются все разряды одного слова, и/или битовым слоем - по одному разряду
из одной и той же позиции каждого слова (иногда эти два способа называют
горизонтальной и вертикальной выборками соответственно). Конечно же, при
анализе данной классификации надо делать скидку на время ее появления, так как
предусмотреть невероятное разнообразие параллельных систем настоящего времени
было в принципе невозможно. Итак, согласно классификации Шора все компьютеры
разбиваются на шесть классов, которые он так и называет: машина типа I, II и
т.д.
Машина
I (рис. 1.5) -
это вычислительная система, которая содержит устройство управления,
арифметико-логическое устройство, память команд и память данных с пословной
выборкой. Считывание данных осуществляется выборкой всех разрядов некоторого
слова для их параллельной обработки в арифметико-логическом устройстве. Состав
АЛУ специально не оговаривается, что допускает наличие нескольких
функциональных устройств, быть может конвейерного типа. По этим соображениям в
данный класс попадают как классические последовательные машины (IBM 701,
PDP-11, VAX 11/780), так и конвейерные скалярные (CDC 7600) и
векторно-конвейерные (CRAY-1).
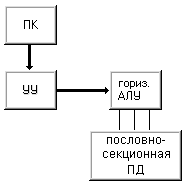
Рисунок 1.5 – Машина I
Если в машине
I осуществлять выборку не по словам, а выборкой содержимого одного разряда из
всех слов, то получим машину II (рис.
1.6) . Слова в памяти данных по прежнему располагаются
горизонтально, но доступ к ним осуществляется иначе. Если в машине I происходит
последовательная обработка слов при параллельной обработке разрядов, то в
машине II - последовательная обработка битовых слоев при параллельной обработке
множества слов.
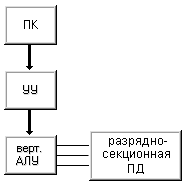
Рисунок 1.6 – Машина II
Структура машины II лежит
в основе ассоциативных компьютеров (например, центральный процессор машины
STARAN), причем фактически такие компьютеры имеют не одно арифметико-логическое
устройство, а множество сравнительно простых устройств поразрядной обработки.
Другим примером служит матричная система ICL DAP, которая может одновременно
обрабатывать по одному разряду из 4096 слов.
Если объединить принципы
построения машин I и II, то получим машину
III (рис. 1.7). Эта машина имеет два арифметико-логических
устройства - горизонтальное и вертикальное, и модифицированную память данных,
которая обеспечивает доступ как к словам, так и к битовым слоям. Впервые идею
построения таких систем в 1960 году выдвинул У.Шуман , называвший их
ортогональными (если память представлять как матрицу слов, то доступ к данным
осуществляется в направлении, "ортогональном" традиционному - не по
словам (строкам), а по битовым слоям (столбцам)). В принципе, как машину
STARAN, так и ICL DAP можно запрограммировать на выполнение функций машины III,
но поскольку они не имеют отдельных АЛУ для обработки слов и битовых слоев,
отнести их к данному классу нельзя. Полноправными представителями машин класса
III являются вычислительные системы семейства OMEN-60 фирмы Sanders Associates,
построенные в прямом соответствии с концепцией ортогональной машины.
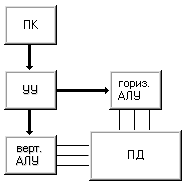
Рисунок 1.7 – Машина III
Если в машине I увеличить
число пар арифметико-логическое устройство <=> память данных (иногда эту
пару называют процессорным элементом) то получим машину IV (рис. 1.8). Единственное
устройство управления выдает команду за командой сразу всем процессорным
элементам. С одной стороны, отсутствие соединений между процессорными
элементами делает дальнейшее наращивание их числа относительно простым, но с
другой, сильно ограничивает применимость машин этого класса. Такую структуру
имеет вычислительная система PEPE, объединяющая 288 процессорных элементов.
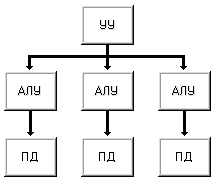
Рисунок 1.8 – Машина IV
Если ввести
непосредственные линейные связи между соседними процессорными элементами машины
IV, например в виде матричной конфигурации, то получим схему машины V (рис. 1.9). Любой
процессорный элемент теперь может обращаться к данным как в своей памяти, так и
в памяти непосредственных соседей. Подобная структура характерна, например, для
классического матричного компьютера ILLIAC IV.
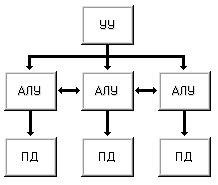
Рисунок 1.9 – Машина V
Заметим, что все машины с
I-ой по V-ю придерживаются концепции разделения памяти данных и арифметико-логических
устройств, предполагая наличие шины данных или какого-либо коммутирующего
элемента между ними. Машина VI
(рис. 1.10), названная матрицей с
функциональной памятью (или памятью с встроенной логикой),
представляет собой другой подход, предусматривающий распределение логики
процессора по всему запоминающему устройству. Примерами могут служить как
простые ассоциативные запоминающие устройства, так и сложные ассоциативные
процессоры.
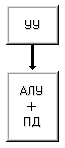
Рисунок 1.10 – Машина VI
1.5 Классификация Хендлера
В основу
классификации В.Хендлер закладывает явное описание возможностей параллельной и
конвейерной обработки информации вычислительной системой. При этом он намеренно
не рассматривает различные способы связи между процессорами и блоками памяти и
считает, что коммуникационная сеть может быть нужным образом сконфигурирована и
будет способна выдержать предполагаемую нагрузку.
Предложенная
классификация базируется на различии между тремя уровнями обработки данных в
процессе выполнения программ:
-
уровень
выполнения программы - опираясь на счетчик команд и некоторые другие регистры,
устройство управления (УУ) производит выборку и дешифрацию команд программы;
-
уровень
выполнения команд - арифметико-логическое устройство компьютера (АЛУ) исполняет
команду, выданную ему устройством управления;
-
уровень битовой
обработки - все элементарные логические схемы процессора (ЭЛС) разбиваются на
группы, необходимые для выполнения операций над одним двоичным разрядом.
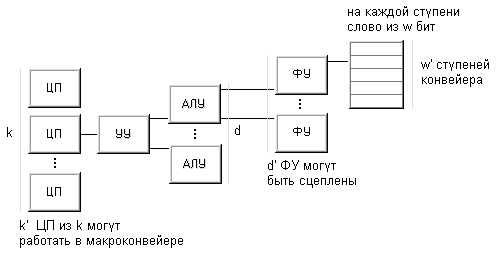
Рисунок 1.11
Принцип классификации Хендлера
Таким
образом, подобная схема выделения уровней предполагает, что вычислительная
система включает какое-то число процессоров каждый со своим устройством
управления. Каждое устройство управления связано с несколькими
арифметико-логическими устройствами, исполняющими одну и ту же операцию в
каждый конкретный момент времени. Наконец, каждое АЛУ объединяет несколько
элементарных логических схем, ассоциированных с обработкой одного двоичного
разряда (число ЭЛС есть ничто иное, как длина машинного слова). Если на
какое-то время не рассматривать возможность конвейеризации, то число устройств
управления k , число арифметико-логических устройств d в каждом устройстве
управления и число элементарных логических схем w в каждом АЛУ составят тройку
для описания данной вычислительной системы C:
t(C) = (k, d,
w)
Теперь можно
расширить возможности описания, допустив возможность конвейерной обработки на
каждом из уровней. В самом деле, конвейерность на самом нижнем уровне (т.е. на
уровне ЭЛС) это конвейерность функциональных устройств. Если функциональное
устройство обрабатывает w-разрядные слова на каждой из w' ступеней конвейера,
то для характеристики параллелизма данного уровня естественно рассмотреть
произведение w×w'. Знак умножения × будем использовать на каждом
уровне чтобы отделить число, представляющее степень параллелизма, от числа
ступеней в конвейере. Компьютер TI ASC имеет четыре конвейерных устройства по
восемь ступеней в каждом для обработки 64-х разрядных слов, следовательно, он
может быть описан так:
t( TI ASC ) =
(1,4,64×8)
Следующий
уровень конвейерной обработки - это конвейеризация на уровне команд.
Предполагается, что в вычислительной системе есть несколько функциональных
устройств, которые могут работать одновременно в рамках одного потока команд (в
настоящее время используется специальный термин для обозначения данной
возможности - сцепление функциональных устройств). Классическим примером этому
могут служить компьютеры фирмы Cray Research. А исторически
первой, по всей вероятности, является машина CDC 6600, содержащая десять
независимых последовательных функциональных устройств, способных подавать
результат своей работы на вход другим функциональным устройствам, образуя
единый поток команд:
t(CDC 6600) =
(1,1×10,~64)
Наконец,
осталось рассмотреть конвейеризацию на самом верхнем уровне, известную как
макро-конвейер. Поток данных, проходя через один процессор, поступает на вход
другому, возможно через некоторую буферную память. Если независимо работают n
процессоров, то в идеальной ситуации при отсутствии конфликтов и полной
сбалансированности получаем ускорение в n раз по сравнению с использованием
только одного процессора. Так компьютер PEPE, имея фактически три независимых
системы из 288-ми устройств, описывается следующим образом:
t( PEPE ) =
(1×3,288,32)
После
расширения трехуровневой модели параллелизма средствами описания потенциальных
возможностей конвейеризации каждая тройка t( PEPE ) = (k×k',d×d',w×w')
интерпретируется так:
-
k - число процессоров
(каждый со своим УУ), работающих параллельно
-
k' - глубина
макроконвейера из отдельных процессоров
-
d - число АЛУ в
каждом процессоре, работающих параллельно
-
d' - число
функциональных устройств АЛУ в цепочке
-
w - число
разрядов в слове, обрабатываемых в АЛУ параллельно
-
w' - число
ступеней в конвейере функциональных устройств АЛУ
1.6 Классификация Хокни
Р. Хокни - известный
английский специалист в области параллельных вычислительных систем, разработал
свой подход к классификации, введенной им для систематизации компьютеров,
попадающих в класс MIMD по систематике Флинна.
Как
отмечалось выше (см. классификацию Флинна), класс MIMD чрезвычайно широк,
причем наряду с большим числом компьютеров он объединяет и целое множество
различных типов архитектур. Хокни, пытаясь систематизировать архитектуры внутри
этого класса, получил иерархическую структуру, представленную на рис. 1.12:
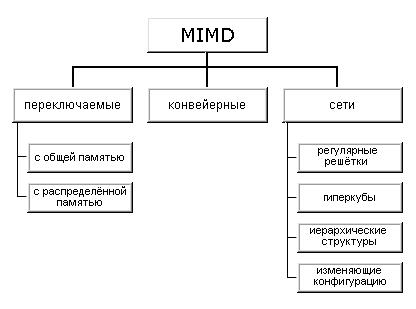
Рисунок 1. 12
Иерархическая структура класса MIMD
Основная идея
классификации состоит в следующем. Множественный поток команд может быть
обработан двумя способами: либо одним конвейерным устройством обработки,
работающем в режиме разделения времени для отдельных потоков, либо каждый поток
обрабатывается своим собственным устройством. Первая возможность используется в
MIMD компьютерах, которые автор называет конвейерными (например, процессорные
модули в Denelcor HEP). Архитектуры, использующие вторую возможность, в свою
очередь опять делятся на два класса:
-
MIMD компьютеры,
в которых возможна прямая связь каждого процессора с каждым, реализуемая с
помощью переключателя;
-
MIMD компьютеры,
в которых прямая связь каждого процессора возможна только с ближайшими соседями
по сети, а взаимодействие удаленных процессоров поддерживается специальной
системой маршрутизации через процессоры-посредники.
Далее, среди
MIMD машин с переключателем Хокни выделяет те, в которых вся память
распределена среди процессоров как их локальная память (например, PASM,
PRINGLE). В этом случае общение самих процессоров реализуется с помощью очень
сложного переключателя, составляющего значительную часть компьютера. Такие
машины носят название MIMD машин с распределенной памятью. Если память это
разделяемый ресурс, доступный всем процессорам через переключатель, то такие
MIMD являются системами с общей памятью (CRAY X-MP, BBN Butterfly). В
соответствии с типом переключателей можно проводить классификацию и далее:
простой переключатель, многокаскадный переключатель, общая шина.
Многие
современные вычислительные системы имеют как общую разделяемую память, так и
распределенную локальную. Такие системы автор рассматривает как гибридные MIMD c
переключателем.
При
рассмотрении MIMD машин с сетевой структурой считается, что все они имеют
распределенную память, а дальнейшая классификация проводится в соответствии с
топологией сети: звездообразная сеть (lCAP), регулярные решетки разной
размерности (Intel Paragon, CRAY T3D), гиперкубы (NCube, Intel iPCS), сети с
иерархической структурой, такой, как деревья, пирамиды, кластеры (Cm*
, CEDAR) и, наконец, сети, изменяющие свою конфигурацию.
Заметим, что
если архитектура компьютера спроектирована с использованием нескольких сетей с
различной топологией, то, по всей видимости, по аналогии с гибридными MIMD с
переключателями, их стоит назвать гибридными сетевыми MIMD, а использующие идеи
разных классов - просто гибридными MIMD. Типичным представителем последней
группы, в частности, является компьютер Connection Machine 2, имеющим на
внешнем уровне топологию гиперкуба, каждый узел которого является кластером
процессоров с полной связью.
1.7 Классификация Шнайдера
В 1988 году
Л. Шнайдер предложил новый подход к описанию архитектур параллельных
вычислительных систем, попадающих в класс SIMD систематики Флинна. Основная
идея заключается в выделении этапов выборки и непосредственно исполнения в
потоках команд и данных. Именно разделение потоков на адреса и их содержимое
позволяет описать такие ранее "неудобные" для классификации
архитектуры, как компьютеры с длинным командным словом, систолические массивы и
целый ряд других.
Введем
необходимые для дальнейшего изложения понятия и обозначения. Назовем потоком ссылок
( reference stream ) S некоторой вычислительной системы конечное множество
бесконечных последовательностей пар:
S = { (a1t1) (a2t2)..., (b1u1) (b2u2)..., (c1v1)(c2v2)...},
где первый
компонент каждой пары - это неотрицательное целое число, называемое адресом,
второй компонент - это набор из n неотрицательных целых чисел, называемых значениями,
причем n одинаково для всех наборов всех последовательностей. Например, пара (b2u2)
определяет адрес b2 и значение u2.
Если значения рассматривать как команды, то из потока ссылок получим поток
команд I; если же значения интерпретировать как данные, то соответствующий
поток - это поток данных D.
Интерпретация
введенных понятий очень проста. Элементы каждой последовательности это адрес и
его содержимое, выбираемое из (или записываемое в) память. Последовательность
пар адрес-значение можно рассматривать как историю выполнения команд либо
перемещения данных между процессором и памятью компьютера во время выполнения программы.
Число инструкций, которое данный компьютер может выполнять одновременно,
определяет число последовательностей в потоке команд. Аналогично, число
различных данных, которое компьютер может обработать одновременно, определяет
число последовательностей в потоке данных.
Пусть S
произвольный поток ссылок. Последовательность адресов потока S, обозначаемая Sa,
- это последовательность, чей i-й элемент - набор, сформированный из адресов
i-х элементов каждой последовательности из S:
Sa = a1
b1 ...c1 ,a2
b2 ...c2 ,...
потока S,
обозначаемая Sv, - это последовательность, чей i-й элемент - набор,
образованный слиянием наборов значений i-х элементов каждой последовательности
из S:
Sv
= t1 u1 ...v1,t2
u2 ...v2 ,...
Если Sx
- последовательность элементов, где каждый элемент - набор из n чисел, то для
обозначения "ширины" последовательности будем пользоваться
обозначением: w(Sx) = n.
Из
определений Sa, Sv и w сразу следует утверждение: если S
- это поток ссылок со значениями из n чисел, то
w(Sa)
= S и w(Sv) = nS,
где S
обозначает мощность множества S.
Каждую пару (I,
D) с потоком команд I и потоком данных D будем называть вычислительным шаблоном,
а все компьютеры будем разбивать на классы в зависимости от того, какой шаблон
они могут исполнить. В самом деле, компьютер может исполнить шаблон (I, D),
если он в состоянии:
-
выдать w(Ia)
адресов команд для одновременной выборки из памяти;
-
декодировать и
проинтерпретировать одновременно w(Iv) команд;
-
выдать
одновременно w(Da) адресов операндов и
-
выполнить
одновременно w(Dv) операций над различными данными.
Если все эти
условия выполнены, то компьютер может быть описан следующим образом:
Iw(Ia)w(Iv)Dw(Da)w(Dv)
На основе
указанных предикатов можно выделить следующие классы компьютеров:
-
IssDss
- фон-неймановские машины;
-
IssDsc
- фон-неймановские машины, в которых заложена возможность выбирать данные,
расположенные с разным смещением относительно одного и того же адреса, над
которыми будет выполнена одна и та же операция. Примером могут служить
компьютеры, имеющие команды, типа одновременного выполнения двух операций
сложения над данными в формате полуслова, расположенными по указанному адресу.
-
IssDsm
- SIMD компьютеры без возможности получения уникального адреса для данных в каждом
процессорном элементе, включающие MPP, Connection Machine 1 так же, как и
систолические массивы.
-
IssDcc
- многомерные SIMD машины - фон-неймановские машины, способные расщеплять поток
данных на независимые потоки операндов;
-
IssDmm
- это SIMD компьютеры, имеющие возможность независимой модификации адресов
операндов в каждом процессорном элементе, например, ILLIAC IV и Connection
Machine 2.
-
IscDcc
- вычислительные системы, выбирающие и исполняющие одновременно несколько
команд, для доступа к которым используется один адрес. Типичным примером
являются компьютеры с длинным командным словом (VLIW).
-
IccDcc
- многомерные MIMD машины. Фон-неймановские машины, которые могут расщеплять
свой цикл выборки/выполнения с целью обработки параллельно нескольких
независимых команд.
-
ImmDmm
- к этому классу относятся все компьютеры типа MIMD.
Достаточно
ясно, что не нужно рассматривать все возможные комбинации описателей 's', 'c' и
'm', так как архитектура реальных компьютеров накладывает ряд вполне разумных ограничений.
Очевидно, что число адресов w(Sa) не должно превышать числа
возвращенных значений w(Sv), которое компьютер может обработать.
Отсюда следуют неравенства: w(Ia)<=w(Iv) и w(Da)<=w(Dv).
Другим естественным предположением является тот факт, что число выполняемых
команд не должно превышать числа обрабатываемых данных: w(Iv) <=
w(Dv).
Подводя итог,
можно отметить два положительных момента в классификации Шнайдера: более
избирательная систематизация SIMD компьютеров и возможность описания
нетрадиционных архитектур типа систолических массивов или компьютеров с длинным
командным словом. Однако почти все вычислительные системы типа MIMD опять
попали в один и тот же класс ImmDmm. Это и не
удивительно, так как критерий классификации, основанный лишь на потоках команд
и данных без учета распределенности памяти и топологии межпроцессорной связи,
слишком слаб для подобных систем.
1.8 Классификация Джонсона
Е.Джонсон
предложил проводить классификацию MIMD архитектур на основе структуры памяти и
реализации механизма взаимодействия и синхронизации между процессорами.
По структуре
оперативной памяти существующие вычислительные системы делятся на две большие
группы: либо это системы с общей памятью, прямо адресуемой всеми процессорами,
либо это системы с распределенной памятью, каждая часть которой доступна только
одному процессору. Одновременно с этим, и для межпроцессорного взаимодействия
существуют две альтернативы: через разделяемые переменные или с помощью
механизма передачи сообщений. Исходя из таких предположений, можно получить
четыре класса MIMD архитектур, уточняющих систематику Флинна:
-
общая память -
разделяемые переменные (GMSV);
-
распределенная
память - разделяемые переменные (DMSV);
-
распределенная
память - передача сообщений (DMMP);
-
общая память -
передача сообщений (GMMP).
Опираясь на
такое деление, Джонсон вводит названия для некоторых классов. Так
вычислительные системы, использующие общую разделяемую память для
межпроцессорного взаимодействия и синхронизации, он называет системами с разделяемой
памятью, например, CRAY Y-MP (по его классификации это класс 1). Системы, в
которых память распределена по процессорам, а для взаимодействия и
синхронизации используется механизм передачи сообщений он называет
архитектурами с передачей сообщений, например NCube, (класс 3). Системы с
распределенной памятью и синхронизацией через разделяемые переменные, как в BBN
Butterfly, называются гибридными архитектурами (класс 2).
В качестве
уточнения классификации автор отмечает возможность учитывать вид связи между
процессорами: общая шина, переключатели, разнообразные сети и т.п.
1.9 Классификация Базу
По мнению
А.Базу, любую параллельную вычислительную систему можно однозначно описать
последовательностью решений, принятых на этапе ее проектирования, а сам процесс
проектирования представить в виде дерева. В самом деле, корень дерева - это
вычислительная система (рис. 1.13), а последующие ярусы дерева, фиксируя
уровень параллелизма, метод реализации алгоритма, параллелизм инструкций и
способ управления, последовательно дополняют друг друга, формируя описание
системы.
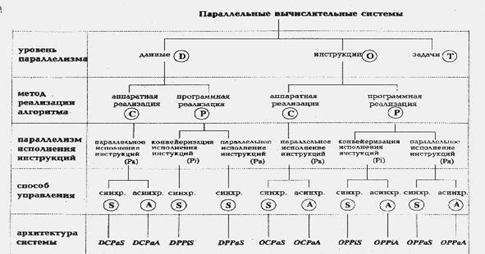
Рисунок 1.13
Классификация Базу
На первом
этапе мы определяем, какой уровень параллелизма используется в вычислительной
системе. Одна и та же операция может одновременно выполняться над целым набором
данных, определяя параллелизм на уровне данных (обозначается буквой D на
рисунке). Способность выполнять более одной операции одновременно говорит о
параллелизме на уровне команд (буква O на рисунке). Если же компьютер
спроектирован так, что целые последовательности команд могут быть выполнены
одновременно, то будем говорить о параллелизме на уровне задач (буква T).
Второй
уровень в классификационном дереве фиксирует метод реализации алгоритма. С
появлением сверхбольших интегральных схем (СБИС) стало возможным реализовывать
аппаратно не только простые арифметические операции, но и алгоритмы целиком.
Например, быстрое преобразование Фурье, произведение матриц и LU-разложение
относятся к классу тех алгоритмов, которые могут быть эффективно реализованы в
СБИС'ах. Данный уровень классификации разделяет системы с аппаратной
реализацией алгоритмов (буква C на схеме) и системы, использующие традиционный
способ программной реализации (буква P).
Третий
уровень конкретизирует тип параллелизма, используемого для обработки инструкций
машины: конвейеризация инструкций (Pi) или их независимое (параллельное)
выполнение (Pa). В большей степени этот выбор относится к
компьютерам с программной реализацией алгоритмов, так как аппаратная реализация
всегда предполагает параллельное исполнение команд. Отметим, что в случае
конвейерного исполнения имеется в виду лишь конвейеризация самих команд,
разбивающая весь цикл обработки на выборку команды, дешифрацию, вычисление
адресов и т.д., - возможная конвейеризация вычислений на данном уровне не
принимается во внимание.
Последний
уровень данной классификации определяет способ управления, принятый в
вычислительной системе: синхронный (S) или асинхронный (A). Если выполнение
команд происходит в строгом порядке, определяемом только сигналами таймера и
счетчиком команд, то будем говорить о синхронном способе управления. Если же
для инициации команды определяющими являются такие факторы, как, например,
готовность данных, то попадаем в класс машин с асинхронным управлением.
Наиболее характерными представителями систем с асинхронным управлением являются
data-driven и demand-driven компьютеры
Описав
основные принципы классификации, посмотрим, куда попадают различные типы
параллельных вычислительных систем.
Изучение
систолических массивов, имеющих, как правило, одномерную или двумерную
структуру, показывает, что обозначения DCPaS и DCPaA
могут быть использованы для их описания в зависимости от того, как происходит
обмен данными: синхронно или асинхронно. Систолические деревья, введенные
Кунгом для вычисления арифметических выражений могут быть описаны как OCPaS
либо OCPaA по аналогичным соображениям. Конвейерные компьютеры,
такие, как IBM 360/91, Amdahl 470/6 и многие современные RISC процессоры,
разбивающие исполнение всех инструкций на несколько этапов, в данной
классификации имеют обозначение OPPiS. Более естественное применение
конвейеризации происходит в векторных машинах, в которых одна команда
применяется к вектору независимых данных, и за счет непрерывного использования
арифметического конвейера достигается значительное ускорение. К таким
компьютерам подходит обозначение DPPiS. Матричные процессоры, в
которых целое множество арифметических устройств работает одновременно в строго
синхронном режиме, принадлежат к группе DPPaS. Если вычислительная
система подобно CDC 6600 имеет процессор с отдельными функциональными устройствами,
управляемыми централизованно, то ее описание выглядит так: OPPaS.
Data-flow компьютеры, в зависимости от особенностей реализации, могут быть
описаны либо как OPPiA, либо OPPaA.
Системы с
несколькими процессорами, использующими параллелизм на уровне задач, не всегда
можно корректно описать в рамках предложенного формализма. Если процессоры
дополнительно не используют параллелизм на уровне операций или данных, то для
описания можно использовать лишь букву T. В противном случае, Базу предлагает
использовать знак '*' между символами, обозначающими уровни параллелизма,
одновременно присутствующие в системе. Например, комбинация T*D означает, что
некоторая система может одновременно исполнять несколько задач, причем каждая
из них может использовать векторные команды.
Очень часто в
реальных системах присутствуют особенности, характерные для компьютеров из
разных групп данной классификации. В этом случае для корректного описания автор
использует знак '+'. Например, практически все векторные компьютеры имеют скалярную
и векторную части, что можно описать как OPPiS+DPPiS
(пример - это TI ASC и CDC STAR-100). Если в системе есть возможность
одновременного выполнения более одной векторной команды (как в CRAY-1) то для
описания векторной части можно использовать запись O*DPPiS, а полное
описание данного компьютера выглядит так: O*DPPiS+OPPiS.
Действуя по такому же принципу, можно найти описание и для систем CRAY X-MP и
CRAY Y-MP. В самом деле, данные системы объединяют несколько процессоров,
имеющих схожую с CRAY-1 структуру, и потому их описание имеет вид: T*(O*DPPiS+OPPiS).
1.10 Классификация Кришнамарфи
Е.Кришнамарфи
для классификации параллельных вычислительных систем предлагает использовать
четыре характеристики, очень похожие на характеристики классификации А.Базу:
-
степень
гранулярности;
-
способ реализации
параллелизма;
-
топология и
природа связи процессоров;
-
способ управления
процессорами.
Принцип
построения классификации очень прост. Для каждой степени гранулярности будем
рассматривать все возможные способы реализации параллелизма. Для каждого
полученного таким образом варианта рассмотрим все комбинации топологии связи и
способов управления процессорами. В результате получим дерево (pис. 1.14), в
котором каждый ярус соответствует своей характеристике, каждый лист
представляет отдельную группу компьютеров в данной классификации, а путь от
вершины дерева однозначно определяет значения указанных выше характеристик.
Разберем характеристики подробнее.
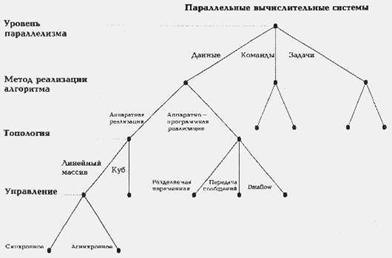
Рисунок 1.14
Дерево классификации Кришнамарфи
Первые два
уровня практически один к одному повторяют А.Базу. Третий уровень
классификации, топология и природа связи процессоров, тесно связан со вторым.
Если был выбран аппаратный способ реализации параллелизма, то надо рассмотреть
топологию связи процессоров (матрица, линейный массив, тор, дерево, звезда и
т.п.) и степень связности процессоров между собой (сильная, слабая или
средняя), которая определяется относительной долей накладных расходов при
организации взаимодействия процессоров. В случае комбинированной реализации
параллелизма, помимо топологии и степени связности, надо дополнительно учесть
механизм взаимодействия процессоров: передача сообщений, разделяемые переменные
или принцип dataflow (по готовности операндов).
Наконец,
последний, четвертый уровень - способ управления процессорами, определяет общий
принцип функционирования всей совокупности процессоров вычислительной системы:
синхронный, dataflow или асинхронный.
На основе
выделенных четырех характеристик нетрудно определить место наиболее известных
классов архитектур в данной систематике.
Векторно-конвейерные
компьютеры:
-
гранулярность -
на уровне данных;
-
реализация
параллелизма - аппаратная;
-
связь процессоров
- простая топология со средней связностью;
-
способ управления
- синхронный.
Классические
мультипроцессоры:
-
гранулярность -
на уровне задач
-
реализация
параллелизма - комбинированная;
-
связь процессоров
- простая топология со слабой связностью и использованием разделяемых
переменных;
-
способ управления
- асинхронный.
Матрицы
процессоров:
-
гранулярность -
на уровне данных;
-
реализация
параллелизма - аппаратная;
-
связь процессоров
- двумерные массивы с сильной связностью;
-
способ управления
- синхронный.
Систолические
массивы:
-
гранулярность -
на уровне данных;
-
реализация
параллелизма - аппаратная;
-
связь процессоров
- сложная топология с сильной связностью;
-
способ управления
- синхронный.
Архитектура
типа wavefront:
-
гранулярность -
на уровне данных;
-
реализация
параллелизма - аппаратная;
-
связь процессоров
- двумерная топология с сильной связностью;
-
способ управления
- dataflow.
Архитектура
типа dataflow:
-
гранулярность -
на уровне команд;
-
реализация
параллелизма - комбинированная;
-
связь процессоров
- простая топология с сильной либо средней связностью и использованием принципа
dataflow;
-
способ управления
- асинхронно-dataflow.
Несмотря на
то, что классификация Е. Кришнамарфи построена лишь на четырех признаках, она
позволяет выделить и описать такие "нетрадиционные" параллельные
системы, как систолические массивы, машины типа dataflow и wavefront. Однако
эта же простота является и основной причиной ее недостатков: некоторые
архитектуры нельзя однозначно отнести к тому или иному классу, например,
компьютеры с архитектурой гиперкуба и ассоциативные процессоры. Для более
точного описания таких машин потребуется ввести еще целый ряд характеристик,
таких, как размещение задач по процессорам, способ маршрутизации сообщений,
возможность реконфигурации, аппаратная поддержка языков программирования и
другие. Вместе с тем ясно, что эти признаки формализовать гораздо труднее, поэтому
есть опасность вместо ясности внести в описание лишь дополнительные трудности.
1.11 Классификация Скилликорна
В 1989 году
была сделана очередная попытка расширить классификацию Флинна и, тем самым,
преодолеть ее недостатки. Д.Скилликорн разработал подход, пригодный для
описания свойств многопроцессорных систем и некоторых нетрадиционных
архитектур, в частности dataflow и reduction machine.
Предлагается
рассматривать архитектуру любого компьютера, как абстрактную структуру,
состоящую из четырех компонент:
-
процессор команд (IP - Instruction Processor) -
функциональное устройство, работающее, как интерпретатор команд; в системе,
вообще говоря, может отсутствовать;
-
процессор данных (DP - Data Processor) -
функциональное устройство, работающее как преобразователь данных, в
соответствии с арифметическими операциями;
-
иерархия памяти (IM - Instruction Memory, DM - Data
Memory) - запоминающее устройство, в котором хранятся данные и команды,
пересылаемые между процессорами;
-
переключатель - абстрактное устройство,
обеспечивающее связь между процессорами и памятью.
Функции
процессора команд во многом схожи с функциями устройств управления
последовательных машин и, согласно Д.Скилликорну, сводятся к следующим:
-
на основе своего
состояния и полученной от DP информации IP определяет адрес команды, которая
будет выполняться следующей;
-
осуществляет
доступ к IM для выборки команды;
-
получает и
декодирует выбранную команду;
-
сообщает DP
команду, которую надо выполнить;
-
определяет адреса
операндов и посылает их в DP;
-
получает от DP
информацию о результате выполнения команды.
Функции
процессора данных делают его , во многом, похожим на арифметическое устройство
традиционных процессоров:
-
DP получает от IP
команду, которую надо выполнить;
-
получает от IP
адреса операндов;
-
выбирает операнды
из DM;
-
выполняет
команду;
-
запоминает
результат в DM;
-
возвращает в IP
информацию о состоянии после выполнения команды.
В терминах
таким образом определенных основных частей компьютера структуру традиционной
фон-неймановской архитектуры можно представить в следующем виде:
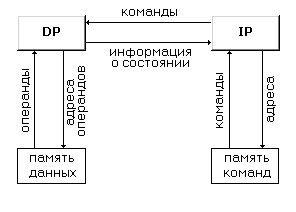
Рисунок 1.15
Структура фон-неймановской архитектуры
Это один из
самых простых видов архитектуры, не содержащих переключателей. Для описания
параллельных вычислительных систем автор зафиксировал четыре типа
переключателей, без какой-либо явной связи с типом устройств, которые они
соединяют:
-
1-1 -
переключатель такого типа связывает пару функциональных устройств;
-
n-n -
переключатель связывает i-е устройство из одного множества устройств с i-м
устройством из другого множества, т.е. фиксирует попарную связь;
-
1-n -
переключатель соединяет одно выделенное устройство со всеми функциональными
устройствами из некоторого набора;
-
nxn - каждое
функциональное устройство одного множества может быть связано с любым
устройством другого множества, и наоборот.
Примеров
подобных переключателей можно привести очень много. Так, все матричные
процессоры имеют переключатель типа 1-n для связи единственного процессора
команд со всеми процессорами данных. В компьютерах семейства Connection Machine
каждый процессор данных имеет свою локальную память, следовательно, связь будет
описываться как n-n. В тоже время, каждый процессор команд может связаться с
любым другим процессором, поэтому данная связь будет описана как nxn.
Классификация
Д.Скилликорна состоит из двух уровней. На первом уровне она проводится на
основе восьми характеристик:
-
количество
процессоров команд (IP);
-
число
запоминающих устройств (модулей памяти) команд (IM);
-
тип переключателя
между IP и IM;
-
количество
процессоров данных (DP);
-
число
запоминающих устройств (модулей памяти) данных (DM);
-
тип переключателя
между DP и DM;
-
тип переключателя
между IP и DP;
-
тип переключателя
между DP и DP.
Рассмотрим
упомянутый выше компьютер Connection Machine 2. В терминах данных характеристик
его можно описать: (1, 1, 1-1, n, n, n-n, 1-n, nxn),
Для сильно
связанных мультипроцессоров (BBN Butterfly, C.mmp) ситуация иная. Такие системы
состоят из множества процессоров, соединенных с модулями памяти с помощью
динамического переключателя. Задержка при доступе любого процессора к любому
модулю памяти примерно одинакова. Связь и синхронизация между процессорами
осуществляется через общие (разделяемые) переменные. Описание таких машин в
рамках данной классификации выглядит так: (n, n, n-n, n, n, nxn, n-n, нет),
Используя
введенные характеристики и предполагая, что рассмотрение количественных
характеристик можно ограничить только тремя возможными вариантами значений: 0,
1 и n (т.е. больше одного), можно получить 28 классов архитектур.
В классах 1-5
находятся компьютеры типа dataflow и reduction, не имеющие процессоров команд в
обычном понимании этого слова. Класс 6 это классическая фон-неймановская
последовательная машина. Все разновидности матричных процессоров содержатся в
классах 7-10. Классы 11 и 12 отвечают компьютерам типа MISD классификации
Флинна и на настоящий момент, по мнению автора, пусты. Классы с 13-го по 28-й
занимают всесозможные варианты мультипроцессоров, причем в 13-20 классах
находятся машины с достаточно привычной архитектурой, в то время, как архитектура
классов 21-28 пока выглядит экзотично.
На втором
уровне классификации Д.Скилликорн просто уточняет описание, сделанное на первом
уровне, добавляя возможность конвейерной обработки в процессорах команд и
данных.
В конце
данного описания имеет смысл привести сформулированные автором три цели,
которым должна служить хорошо построенная классификация:
-
облегчать
понимание того, что достигнуто на сегодняшний день в области архитектур
вычислительных систем, и какие архитектуры имеют лучшие перспективы в будущем;
-
подсказывать
новые пути организации архитектур - речь идет о тех классах, которые в
настоящее время по разным причинам пусты;
-
показывать, за
счет каких структурных особенностей достигается увеличение производительности
различных вычислительных систем; с этой точки зрения, классификация может
служить моделью для анализа производительности.
1.12 Классификация Дазгупты
Одним из последних
исследований по классификации архитектур, по-видимому, является работа С.
Дазгупты, вышедшая в 1990 году. Автор использовал позитивные идеи работы
Скилликорна, которая была рассмотрена ранее в данном обзоре. Пытаясь расширить
описательные возможности классификации, он разработал иерархическую систему для
классификации архитектур. Изложим ее основные идеи.
Предлагаемая
система построена на основе семи элементарных понятий - базовых элементов
архитектуры.
Базовые
элементы архитектуры:
-
iM - память с
расслоением - память, из которой можно выбрать несколько единиц информации за
один цикл памяти;
-
sM - простая память
- память, из которой можно выбрать единицу информации за цикл памяти;
-
C -
программируемая или непрограммируемая кэш-память. Буферные регистры, подобные
регистрам CRAY-1, также описываются, как кэш-память;
-
sI - простой
(неконвейерный) процессор для подготовки команды к исполнению;
-
pI - конвейерный
процессор для подготовки команды к исполнению;
-
sX - простой
процессор для исполнения команды;
-
pX - конвейерный
процессор для исполнения команды.
Заметим, что функции
процессора для подготовки команды к исполнению (I) эквивалентны тем, которые
выполняет процессор команд (IP) по классификации Скилликорна, с дополнительной
возможностью обращения к кэш-памяти. Аналогично, функции процессора для
исполнения команд (X) совпадают с функциями процессора данных (DP) у
Скилликорна, включая дополнительно работу с кэш-памятью.
Если
архитектура содержит N элементов типа A, которые могут работать в системе
параллельно и независимо (обозначим эту возможность AN), то AN
будем называть сложным элементом типа A. Считается, что составляющие сложного
элемента не имеют между собой физической связи. Например:
sM3
- три блока простой памяти, к которым можно обращаться параллельно и
независимо;
sI4
- четыре неконвейерных процессора, которые могут параллельно и независимо
подготовить к исполнению команды из четырех потоков команд.
Назовем кэш-процессором
CP объединение C-элемента с I, X или другими CP.
Например,
C.sI, C.(C2.pI)2
Обозначение
Ä1.A2" подразумевает последовательное соединение элемента A1 с
элементом A2.
Например,
процессор команд с кэш-памятью: C.sI C - sI
Назовем кэш-процессором
с памятью MCP объединение M-элемента с I, X, CP или другими MCP.
Например,
iM.(C.sI2)k, sM.iM.C.pIn
Процессором
для подготовки команд I" назовем MCP, который представляет собой законченную подсистему
подготовки команды к исполнению.
Процессором
для исполнения команд X" назовем MCP, который представляет собой законченную подсистему для
выполнения команды.
Процессоры,
как и базовые элементы, могут быть сложными элементами архитектуры в смысле
определения данного выше.
Полным
описанием архитектуры может служить одиночная или повторяющаяся
последовательность, составленная из I" и X" процессоров.
Символьную
строку, описывающую некоторый базовый элемент, сложный элемент, процессор или
всю архитектуру, будем называть формулой архитектуры.
Каждая
формула служит описанием некоторой структуры. Введем два оператора,
устанавливающих соответствие между формулой и структурой:
1)
Пусть R -
формула. Тогда оператор Rep(R) описывает следующую структуру:
Другими
словами, если R = AN, то структура описывается оператором Rep(R);
2)
Пусть R = R1.R2.
... .Rn - формула, где Ri может быть базовым или сложным элементом, простым или
сложным процессором. Обозначим head(R) = R1 - самую левую составляющую в
формуле; tail(R) = Rn - самую правую составляющую в формуле.
Введем второй
оператор Link. Пусть R1 и R2 - формулы. Тогда Link(R1, R2):
а) если
tail(R1) и head(R2) - простые составляющие, то
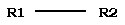
б) если
tail(R1) простая, а head(R2) - сложная составляющая вида Zn, то
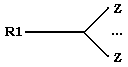
в) если
tail(R1) - сложная составляющая вида Wn, а head(R2) - простая, то
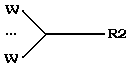
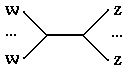
г) если
tail(R1) - сложная составляющая вида Wn, а head(R2) - сложная
составляющая вида Zm, то
Легко понять,
что оператор Link явно описывает связи между элементами архитектуры. В
классификации Скилликорна этим целям служили переключатели четырех типов (см.
классификацию Д.Скилликорна ).
Используя
систему понятий и обозначений, введенных выше, автор строит следующую систему
классификации.
Назовем классом
классификационной схемы именованную группу объектов, которые по некоторым
специально выделенным свойствам отличаются от объектов других классов.
Множество классов образует категорию.
Множество
свойств, которые являются определяющими при отнесении объекта к какому-либо
классу, назовем классификационными характеристиками (TC - taxonomic characters).
В нашем случае введенные выше базовые элементы архитектуры определяют эти
классификационные характеристики.
В сложных
системах классификации может быть несколько категорий, образующих иерархию.
Каждый объект может появляться только в одном классе в некоторой категории.
С. Дазгупта
предлагает для систематизации архитектур классификацию с тремя уровнями
(категориями) иерархии. Он считает, что иерархические системы обладают рядом
привлекательных свойств. В частности, подобные системы позволяют не только
легче сравнивать объекты, но также дают возможность определять, по каким
параметрам и в какой степени объекты одного уровня иерархии сходны или
различны.
Иерархия
категорий строится таким образом, что объекты более низкого уровня обладают
всеми свойствами объектов выше расположенного уровня и некоторыми
дополнительными свойствами. Таким образом, степень детализации описания
архитектуры будет уменьшаться при переходе к категориям более высокого уровня
иерархии.
Итак, автор
предлагает следующую иерархию категорий:
1)
Самый низкий
уровень - категория КЭШ-процессора с памятью MCP (memory-cache processor).
Классами этой
категории являются всевозможные различные архитектуры. Соответствующую
архитектуре формулу можно рассматривать как имя класса.
2)
Более высокий
уровень - категория КЭШ-процессора (СP). Множество классов этой категории
получается путем удаления из классов категории CP составляющих, описывающих
память.
3)
Самый высокий
уровень - категория процессора (P). Классы получают удалением кэш-составляющих
из классов категории CP.
На каждом
уровне описание архитектуры задается формулой, отображающей те свойства
архитектуры, которые являются существенными для данной категории.
Наиболее
низкий уровень иерархии содержит в виде формулы самое подробное описание
архитектуры в терминах различных типов памяти и процессоров, с возможностью
количественного отображения различных элементов архитектуры и указания природы
связей между ними.
Две
архитектуры принадлежат к одному классу в CP категории, если совпадают их
описания процессоров и кэш-памяти. Если две архитектуры сходны только по
описанию процессоров команд, то они попадают в один класс процессорной
категории.
В заключении
отметим, что те уровни иерархии, которые выделены Дазгуптой, не являются
единственно возможными. Могут появиться другие варианты в зависимости от целей
систематизации архитектур ( например, не всегда нас интересует конкретное число
процессоров в системе или тип используемой памяти).
1.13 Классификация Дункана
В работе
Р.Дункан излагает свой взгляд на проблему классификации архитектур параллельных
вычислительных систем, причем сразу определяет тот набор требований, на
который, с его точки зрения, может опираться искомая классификация:
1)
Из класса параллельных
машин должны быть исключены те, в которых параллелизм заложен лишь на самом
низком уровне, включая:
-
конвейеризацию на
этапе подготовки и выполнения команды (instruction pipelining), т.е. частичное
перекрытие таких этапов, как дешифрация команды, вычисление адресов операндов,
выборка операндов, выполнение команды и сохранение результата;
-
наличие в
архитектуре нескольких функциональных устройств, работающих независимо, в
частности, возможность параллельного выполнения логических и арифметических
операций;
-
наличие отдельных
процессоров ввода/вывода, работающих независимо и параллельно с основными
процессорами.
Причины
исключения перечисленных выше особенностей автор объясняет следующим образом.
Если рассматривать компьютеры, использующие только параллелизм низкого уровня,
наравне со всеми остальными, то, во-первых, практически все существующие
системы будут классифицированны как "параллельные" (что заведомо не
будет позитивным фактором для классификации), и, во-вторых, такие машины будут
плохо вписываться в любую модель или концепцию, отражающую параллелизм высокого
уровня.
2)
Классификация должна
быть согласованной с классификацией Флинна, показавшей правильность выбора идеи
потоков команд и данных.
3)
Классификация должна
описывать архитектуры, которые однозначно не укладываются в систематику Флинна,
но, тем не менее, относятся к параллельным архитектурам (например,
векторно-конвейерные).
Учитывая
вышеизложенные требования, Дункан дает неформальное определение параллельной
архитектуры, причем именно неформальность дала ему возможность включить в
данный класс компьютеры, которые ранее не вписывались в систематику Флинна.
Итак, параллельная архитектура - это такой способ организации вычислительной
системы, при котором допускается, чтобы множество процессоров (простых или
сложных) могло бы работать одновременно, взаимодействуя по мере надобности друг
с другом. Следуя этому определению, все разнообразие параллельных архитектур
Дункан систематизирует так, как показано на рис. 1.16:
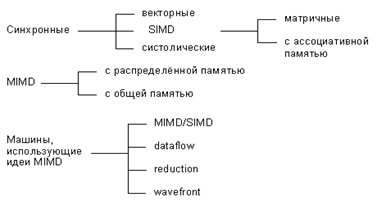
Риснунок 1.16
Классификация параллельных архитектур по Дункану
По существу
систематика очень простая: процессоры системы работают либо синхронно, либо
независимо друг от друга, либо в архитектуру системы заложена та или иная
модификация идеи MIMD. На следующем уровне происходит детализация в рамках
каждого из этих трех классов. Дадим небольшое пояснение лишь к тем из них,
которые на сегодняшний день не столь широко известны.
Систолические
архитектуры (их чаще
называют систолическими массивами) представляют собой множество процессоров,
объединенных регулярным образом (например, система WARP). Обращение к памяти
может осуществляться только через определенные процессоры на границе массива.
Выборка операндов из памяти и передача данных по массиву осуществляется в одном
и том же темпе. Направление передачи данных между процессорами фиксировано.
Каждый процессор за интервал времени выполняет небольшую инвариантную
последовательность действий.
Гибридные
MIMD/SIMD архитектуры, dataflow, reduction и wavefront вычислительные системы
осуществляют параллельную обработку информации на основе асинхронного
управления, как и MIMD системы. Но они выделены в отдельную группу, поскольку
все имеют ряд специфических особенностей, которыми не обладают системы,
традиционно относящиеся к MIMD.
MIMD/SIMD - типично гибридная архитектура. Она
предполагает, что в MIMD системе можно выделить группу процессоров, представляющую
собой подсистему, работающую в режиме SIMD (PASM, Non-Von). Такие системы
отличаются относительной гибкостью, поскольку допускают реконфигурацию в
соответствии с особенностями решаемой прикладной задачи.
Остальные три
вида архитектур используют нетрадиционные модели вычислений. Dataflow
используют модель, в которой команда может выполнятся сразу же, как только
вычислены необходимые операнды. Таким образом, последовательность выполнения
команд определяется зависимостью по данным, которая может быть выражена,
например, в форме графа.
Модель
вычислений, применяемая в reduction машинах иная и состоит в следующем: команда
становится доступной для выполнения тогда и только тогда, когда результат ее
работы требуется другой, доступной для выполнения, команде в качестве операнда.
Wavefront
array архитектура
объединяет в себе идею систолической обработки данных и модель вычислений,
используемой в dataflow. В данной архитектуре процессоры объединяются в модули
и фиксируются связи, по которым процессоры могут взаимодействовать друг с
другом. Однако, в противоположность ритмичной работе систолических массивов,
данная архитектура использует асинхронный механизм связи с подтверждением
(handshaking), из-за чего "фронт волны" вычислений может менять свою
форму по мере прохождения по всему множеству процессоров.
2 ОРГАНИЗАЦИЯ КОМПЬЮТЕРНЫХ СИСТЕМ
2.1 Общие сведения
Цифровой
компьютер состоит из связанных между собой процессоров, памяти и устройств
ввода-вывода.
На
рис. 2.1 показано устройство обычного компьютера. Центральный процессор — это
мозг компьютера. Его задача — выполнять программы, находящиеся в основной
памяти. Он вызывает команды из памяти, определяет их тип, а затем выполняет их
одну за другой. Компоненты соединены шиной, представляющей собой набор параллельно
связанных проводов, по которым передаются адреса, данные и сигналы управления.
Шины могут быть внешними (связывающими процессор с памятью и устройствами
ввода-вывода) и внутренними.
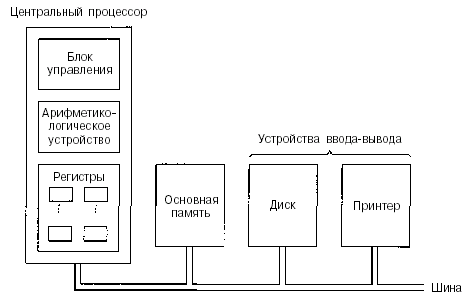
Рисунок
2.1 – . Схема устройства компьютера с одним центральным процессором и двумя
устройствами ввода-вывода
Процессор
состоит из нескольких частей. Блок управления отвечает за вызов команд из
памяти и определение их типа. Арифметико-логическое устройство выполняет
арифметические операции (например, сложение) и логические операции (например,
логическое И).
Внутри
центрального процессора находится память для хранения промежуточных результатов
и некоторых команд управления. Эта память состоит из нескольких регистров,
каждый из которых выполняет определенную функцию. Обычно все регистры
одинакового размера. Каждый регистр содержит одно число, которое ограничивается
размером регистра. Регистры считываются и записываются очень быстро, поскольку
они находятся внутри центрального процессора.
Самый
важный регистр — счетчик команд, который указывает, какую команду нужно
выполнять дальше. Название «счетчик команд» не соответствует действительности,
поскольку он ничего не считает, но этот термин употребляется повсеместно. Еще
есть регистр команд, в котором находится команда, выполняемая в данный момент.
У большинства компьютеров имеются и другие регистры, одни из них
многофункциональны, другие выполняют только какие-либо специфические функции.
2.2 Устройство центрального процессора
Внутреннее
устройство тракта данных типичного фон-неймановского процессорапоказано на рис.
2.2. Тракт данных состоит из регистров (обычно от 1 до 32), АЛУ (арифметико-логического
устройства) и нескольких соединяющих шин. Содержимое регистров поступает во
входные регистры АЛУ, которые на рис. 2.2 обозначены буквами А и В. В них
находятся входные данные АЛУ, пока АЛУ производит вычисления. Тракт данных
важная составная часть всех компьютеров.
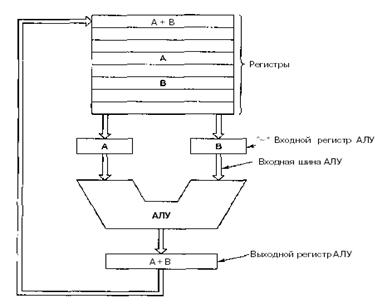
Рисунок
2.2 - Тракт данных в
обычной фон-неймановской машине
АЛУ
выполняет сложение, вычитание и другие простые операции над входными данными и
помещает результат в выходной регистр. Этот выходной регистр может помещаться
обратно в один из регистров. Он может быть сохранен в памяти, если это
необходимо. На рис. 2.2 показана операция сложения. Однако входные и выходные
регистры есть не у всех компьютеров.
Большинство
команд можно разделить на две группы: команды типа регистр-память и типа
регистр-регистр. Команды первого типа вызывают слова из памяти, помещают их в
регистры, где они используются в качестве входных данных АЛУ. («Слова» — это
такие элементы данных, которые перемещаются между памятью и регистрами.) Словом
может быть целое число. Другие команды этого типа помещают регистры обратно в
память.
Команды
второго типа вызывают два операнда из регистров, помещают их во входные
регистры АЛУ, выполняют над ними какую-нибудь арифметическую или логическую
операцию и переносят результат обратно в один из регистров. Этот процесс
называется циклом тракта данных. В какой-то степени он определяет, что может
делать машина. Чем быстрее происходит цикл тракта данных, тем быстрее компьютер
работает.
2.3 Выполнение команд
Центральный
процессор выполняет каждую команду за несколько шагов:
1)
вызывает следующую команду из памяти и переносит ее в регистр команд;
2)
меняет положение счетчика команд, который теперь должен указывать наследующую
команду;
3)
определяет тип вызванной команды;
4)
если команда использует слово из памяти, определяет, где находится это слово;
5)
переносит слово, если это необходимо, в регистр центрального процессора;
6)
выполняет команду;
7)
переходит к шагу 1, чтобы начать выполнение следующей команды.
Такая
последовательность шагов (выборка—декодирование—исполнение) является основой
работы всех компьютеров.
Первые
компьютеры содержали небольшое количество команд, и эти команды были простыми.
Но поиски более мощных компьютеров привели, кроме всего прочего, к появлению
более сложных команд. Вскоре разработчики поняли, что при наличии сложных
команд программы выполняются быстрее, хотя выполнение отдельных команд занимает
больше времени. В качестве примеров сложных команд можно назвать выполнение
операций с плавающей точкой, обеспечение прямого доступа к элементам массива и
т. п. Если обнаруживалось, что две определенные команды часто выполнялись
последовательно одна за другой, то вводилась новая команда, заменяющая работу
этих двух.
Сложные
команды были лучше, потому что некоторые операции иногда перекрывались.
Какие-то операции могли выполняться параллельно, для этого использовались
разные части аппаратного обеспечения. Для дорогих компьютеров с высокой
производительностью стоимость этого дополнительного аппаратного обеспечения была
вполне оправданна. Таким образом, у дорогих компьютеров было гораздо больше
команд, чем у дешевых. Однако развитие программного обеспечения и требования
совместимости команд привели к тому, что сложные команды стали использоваться и
в дешевых компьютерах, хотя там во главу угла ставилась стоимость, а не
скорость работы.
К
концу 50-х годов компания IBM, которая лидировала тогда на компьютерном рынке,
решила, что производство семейства компьютеров, каждый из которых выполняет
одни и те же команды, имеет много преимуществ и для самой компании, и для
покупателей. Чтобы описать этот уровень совместимости, компания IBM ввела
термин архитектура. Новое семейство компьютеров должно было иметь одну общую
архитектуру и много разных разработок, различающихся по цене и скорости,
которые могли выполнять одну и ту же программу. Но как построить дешевый
компьютер, который будет выполнять все сложные команды, предназначенные для
высокоэффективных дорогостоящих машин?
Решением
этой проблемы стала интерпретация. Эта технология, впервые предложенная Уилксом
в 1951 году, позволяла разрабатывать простые дешевые компьютеры, которые, тем
не менее, могли выполнять большое количество команд. В результате IBM создала
архитектуру System/360, семейство совместимых компьютеров, различных по цене и
производительности. Аппаратное обеспечение без интерпретации использовалось
только в самых дорогих моделях.
Простые
компьютеры с интерпретированными командами имели некоторые другие преимущества.
Наиболее важными среди них были:
1)
возможность фиксировать неправильно выполненные команды или даже восполнять
недостатки аппаратного обеспечения;
2)
возможность добавлять новые команды при минимальных затратах, даже после
покупки компьютера;
3)
структурированная организация, которая позволяла разрабатывать, проверять и
документировать сложные команды.
В
70-е годы компьютерный рынок быстро разрастался, новые компьютеры могли
выполнять все больше и больше функций. Спрос на дешевые компьютеры провоцировал
создание компьютеров с использованием интерпретаторов. Возможность разрабатывать
аппаратное обеспечение и интерпретатор для определенного набора команд вылилась
в создание дешевых процессоров. Полупроводниковые технологии быстро
развивались, преимущества низкой стоимости преобладали над возможностями более
высокой производительности, и использование интерпретаторов при разработке
компьютеров стало широко применимо. Интерпретация использовалась практически во
всех компьютерах, выпущенных в 70-е годы, от миникомпьютеров до самых больших
машин.
К
концу 70-х годов интерпретаторы стали применяться практически во всех моделях,
кроме самых дорогостоящих машин с очень высокой производительностью (например,
Сгау-1 и компьютеров серии Control Data Cyber). Использование интерпретаторов
исключало высокую стоимость сложных команд, и разработчики могли вводить все
более и более сложные команды, в особенности различные способы определения
используемых операндов.
Эта
тенденция достигла пика своего развития в разработке компьютера VAX (производитель
Digital Equipment Corporation), у которого было несколько сотен команд и более
200 способов определения операндов в каждой команде. К несчастью, архитектура
VAX с самого начала разрабатывалась с использованием интерпретатора, а
производительности уделялось мало внимания. Это привело к появлению большого
количества команд второстепенного значения, которые трудно было выполнять сразу
без интерпретации. Данное упущение стало фатальным как для VAX, так и для его
производителя (компании DEC). Compaq купил DEC в 1998 году.
Хотя
самые первые 8-битные микропроцессоры были очень простыми и содержали небольшой
набор команд, к концу 70-х годов даже они стали разрабатываться с
использованием интерпретаторов. В этот период основной проблемой для разработчиков
стала возрастающая сложность микропроцессоров. Главное преимущество
интерпретации заключалось в том, что можно было разработать простой процессор,
а вся сложность сводилась к созданию интерпретатора. Таким образом, разработка
сложного аппаратного обеспечения замещалась разработкой сложного программного
обеспечения.
Успех
Motorola 68000 с большим набором интерпретируемых команд и одновременный провал
Zilog Z8000, у которого был столь же обширный набор команд, но не было
интерпретатора, продемонстрировали все преимущества использования интерпретаторов
при разработке новых машин. Успех Motorola 68000 был несколько неожиданным,
учитывая, что Z80 (предшественник Zilog Z8000) пользовался большей
популярностью, чем Motorola 6800 (предшественник Motorola 68000). Конечно,
важную роль здесь играли и другие факторы, например то, что Motorola много лет
занималась производством микросхем, a Exxon (владелец Zilog) долгое время был
нефтяной компанией.
Еще
один фактор в пользу интерпретации — существование быстрых постоянных
запоминающих устройств (так называемых командных ПЗУ) для хранения интерпретаторов.
Предположим, что для выполнения обычной интерпретируемой команды Motorola 68000
интерпретатору нужно выполнить 10 команд, которые называются микрокомандами, по
100 не каждая, и произвести 2 обращения к оперативной памяти по 500 не каждое.
Общее время выполнения команды составит следовательно, 2000 не, всего лишь в
два раза больше, чем в лучшем случае могло бы занять непосредственное
выполнение этой команды без интерпретации. А если бы не было специального быстродействующего
постоянного запоминающего устройства, выполнение этой команды заняло бы целых
6000 не. Таким образом, важность наличия командных ПЗУ очевидна.
2.4 RISC и CISC
В
конце 70-х годов проводилось много экспериментов с очень сложными командами, появление
которых стало возможным благодаря интерпретации. Разработчики пытались
уменьшить пропасть между тем, что компьютеры способны делать и тем, что требуют
языки высокого уровня. Едва ли кто-нибудь тогда думал о разработке более
простых машин, так же как сейчас мало кто занимается разработкой менее мощных
операционных систем, сетей, редакторов и т. д. (к несчастью).
В
компании IBM группа разработчиков во главе с Джоном Коком противостояла этой
тенденции; они попытались воплотить идеи Сеймура Крея, создав экспериментальный
высокоэффективный мини-компьютер 801. Хотя IBM не занималась сбытом этой
машины, а результаты эксперимента были опубликованы только через несколько лет,
весть быстро разнеслась по свету, и другие производители тоже занялись
разработкой подобных архитектур.
В
1980 году группа разработчиков в университете Беркли во главе с Дэвидом Паттерсоном
и Карло Секвином начала разработку процессоров VLSI без использования
интерпретации. Для обозначения этого понятия они придумали термин RISC и назвали
новый процессор RISC I, вслед за которым вскоре был выпущен RISC II. Немного
позже, в 1981 году, Джон Хеннеси в Стенфорде разработал и выпустил другую
микросхему, которую он назвал MIPS. Эти две микросхемы развились в коммерчески
важные продукты SPARC и MIPS соответственно.
Новые
процессоры существенно отличались от коммерческих процессоров того времени.
Поскольку они не были совместимы с существующей продукцией, разработчики вправе
были включать туда новые наборы команд, которые могли бы увеличить общую
производительность системы. Так как основное внимание уделялось простым
командам, которые могли быстро выполняться, разработчики вскоре осознали, что
ключом к высокой производительности компьютера была разработка команд, к
выполнению которых можно быстро приступать. Сколько времени занимает выполнение
одной команды, было не так важно, как то, сколько команд может быть начато в
секунду.
В то
время как разрабатывались эти простые процессоры, всеобщее внимание привлекало
относительно небольшое количество команд (обычно их было около 50). Для
сравнения: число команд в DEC VAX и больших IBM в то время составляло от 200 до
300. RISC — это сокращение от Reduced Instruction Set Computer — компьютер с сокращенным набором
команд. RISC противопоставлялся CISC (Complex Instruction Set Computer
компьютер с полным набором команд). В качестве примера CISC можно привести VAX,
который доминировал в то время в научных компьютерных центрах. На сегодняшний
день мало кто считает, что главное различие RISC и CISC состоит в количестве
команд, но название сохраняется до сих пор.
С
этого момента началась грандиозная идеологическая война между сторонниками RISC
и разработчиками VAX, Intel и больших IBM. По их мнению, наилучший способ
разработки компьютеров — включение туда небольшого количества простых команд,
каждая из которых выполняется за один цикл тракта данных, то есть берет два
регистра, производит над ними какую-либо арифметическую или логическую операцию
(например, сложения или логическое И) и помещает результат обратно в регистр. В
качестве аргумента они утверждали, что даже если RISC должна выполнять 4 или 5
команд вместо одной, которую выполняет CISC, притом что команды RISC
выполняются в 10 раз быстрее (поскольку они не интерпретируются), он выигрывает
в скорости. Следует также отметить, что к этому времени скорость работы
основной памяти приблизилась к скорости специальных управляющих постоянных
запоминающих устройств, потому недостатки интерпретации были налицо, что
повышало популярность компьютеров RISC.
Учитывая
преимущества производительности RISC, можно было бы предположить, что такие
компьютеры, как Alpha компании DEC, стали доминировать над компьютерами CISC
(Pentium и т. д.) на рынке. Однако ничего подобного не произошло. Возникает
вопрос: почему?
Во-первых,
компьютеры RISC были несовместимы с другими моделями, а многие компании вложили
миллиарды долларов в программное обеспечение для продукции Intel. Во-вторых,
как ни странно, компания Intel сумела воплотить те же идеи в архитектуре CISC.
Процессоры Intel, начиная с 486-го, содержат ядро RISC, которое выполняет самые
простые (и обычно самые распространенные) команды за один цикл тракта данных, а
по обычной технологии CISC интерпретируются более сложные команды. В результате
обычные команды выполняются быстро, а более сложные и редкие — медленно. Хотя
при таком «гибридном» подходе работа происходит не так быстро, как у RISC,
данная архитектура имеет ряд преимуществ, поскольку позволяет использовать
старое программное обеспечение без изменений.
2.5 Принципы разработки современных компьютеров
Прошло
уже более двадцати лет с тех пор, как были сконструированы первые компьютеры
RISC, однако некоторые принципы разработки можно перенять, учитывая современное
состояние технологий аппаратного обеспечения. Если происходит очень резкое
изменение в технологиях (например, новый процесс производства делает время
цикла памяти в 10 раз меньше, чем время цикла центрального процессора),
меняются все условия. Поэтому разработчики всегда должны учитывать возможные
технологические изменения, которые могут повлиять на баланс между компонентами
компьютера.
Существует
ряд принципов разработки, иногда называемых принципами RISC, которым по
возможности стараются следовать производители универсальных процессоров. Из-за
некоторых внешних ограничений, например требования совместимости с другими
машинами, приходится время от времени идти на компромисс, но эти принципы
цель, к которой стремится большинство разработчиков.
Все
команды непосредственно выполняются аппаратным обеспечением. Все обычные команды непосредственно
выполняются аппаратным обеспечением. Они не интерпретируются микрокомандами.
Устранение уровня интерпретации обеспечивает высокую скорость выполнения
большинства команд. В компьютерах типа CISC более сложные команды могут
разбиваться на несколько частей, которые затем выполняются как
последовательность микрокоманд. Эта дополнительная операция снижает скорость
работы машины, но она может быть применима для редко встречающихся команд.
Компьютер
должен начинать выполнение большого числа команд. В современных компьютерах
используется много различных способов для увеличения производительности,
главное из которых — возможность обращаться к как можно большему количеству
команд в секунду. Процессор 500-MIPS способен приступать к выполнению 500 млн
команд в секунду, и при этом не имеет значения, сколько времени занимает само
выполнение этих команд (MIPS — это сокращение от Millions of Instructions Per Second — «миллионы команд в секунду».) Этот принцип предполагает, что
параллелизм может играть главную роль в улучшении производительности, поскольку
приступать к большому количеству команд за короткий промежуток времени можно
только в том случае, если одновременно может выполняться несколько команд.
Хотя
команды некоторой программы всегда расположены в определенном порядке,
компьютер может приступать к их выполнению и в другом порядке (так как необходимые
ресурсы памяти могут быть заняты) и, кроме того, может заканчивать их
выполнение не в том порядке, в котором они расположены в программе. Конечно,
если команда 1 устанавливает регистр, а команда 2 использует этот регистр,
нужно действовать с особой осторожностью, чтобы команда 2 не считывала регистр
до тех пор, пока он не будет содержать нужное значение. Чтобы не допустить
подобных ошибок, необходимо вводить большое количество соответствующих записей
в память, но производительность все равно становится выше благодаря возможности
выполнять несколько команд одновременно.
Команды
должны легко декодироваться. Предел количества вызываемых команд в секунду
зависит от процесса декодирования отдельных команд. Декодирование команд
осуществляется для того, чтобы определить, какие ресурсы им необходимы и какие
действия нужно выполнить. Полезны любые средства, которые способствуют
упрощению этого процесса. Например, используются регулярные команды с
фиксированной длиной и с небольшим количеством полей. Чем меньше разных
форматов команд, тем лучше.
К
памяти должны обращаться только команды загрузки и сохранения. Один из самых
простых способов разбивания операций на отдельные шаги — потребовать, чтобы
операнды для большинства команд брались из регистров и возвращались туда же.
Операция перемещения операндов из памяти в регистры может осуществляться в
разных командах. Поскольку доступ к памяти занимает много времени, а подобная
задержка нежелательна, работу этих команд могут выполнять другие команды, если
они не делают ничего, кроме передвижения операндов между регистрами и памятью.
Из этого наблюдения следует, что к памяти должны обращаться только команды
загрузки и сохранения (LOAD и STORE).
Должно
быть большое количество регистров. Поскольку доступ к памяти происходит довольно медленно, в
компьютере должно быть много регистров (по крайней мере 32). Если слово однажды
вызвано из памяти, при наличии большого числа регистров оно может содержаться в
регистре до тех пор, пока будет не нужно. Возвращение слова из регистра в
память и новая загрузка этого же слова в регистр нежелательны. Лучший способ
избежать излишних перемещений — наличие достаточного количества регистров.
2.6 Параллелизм на уровне команд
Разработчики
компьютеров стремятся к тому, чтобы улучшить производительность машин, над
которыми они работают. Один из способов заставить процессоры работать быстрее
увеличение их скорости, однако при этом существуют некоторые технологические
ограничения, связанные с конкретным историческим периодом. Поэтому большинство
разработчиков для достижения лучшей производительности при данной скорости
работы процессора используют параллелизм (возможность выполнять две или более операций
одновременно).
Существует
две основные формы параллелизма: параллелизм на уровне команд и параллелизм на
уровне процессоров. В первом случае параллелизм осуществляется в пределах
отдельных команд и обеспечивает выполнение большого количества команд в
секунду. Во втором случае над одной задачей работают одновременно несколько
процессоров. Каждый подход имеет свои преимущества.
2.6.1 Конвейеры
Уже
много лет известно, что главным препятствием высокой скорости выполнения команд
является их вызов из памяти. Для разрешения этой проблемы разработчики
придумали средство для вызова команд из памяти заранее, чтобы ониимелись в
наличии в тот момент, когда будут необходимы. Эти команды помещались в набор
регистров, который назывался буфером выборки с упреждением. Таким образом,
когда была нужна определенная команда, она вызывалась прямо из буфера, и не
нужно было ждать, пока она считается из памяти. Эта идея использовалась еще при
разработке IBM Stretch, который был сконструирован в 1959 году.
В
действительности процесс выборки с упреждением подразделяет выполнение команды
на два этапа: вызов и собственно выполнение. Идея конвейера еще больше
продвинула эту стратегию вперед. Теперь команда подразделялась уже не на два, а
на несколько этапов, каждый из которых выполнялся определенной частью
аппаратного обеспечения, причем все эти части могли работать параллельно.
На
рис. 2.3а изображен конвейер из 5 блоков, которые называются стадиями. Стадия
С1 вызывает команду из памяти и помещает ее в буфер, где она хранится до тех
пор, пока не будет нужна. Стадия С2 декодирует эту команду, определяя ее тип и
тип операндов, над которыми она будет производить определенные действия. Стадия
СЗ определяет местонахождение операндов и вызывает их или из регистров, или из
памяти. Стадия С4 выполняет команду, обычно путем провода операндов через тракт
данных. И наконец, стадия С5 записывает результат обратно в нужный регистр.
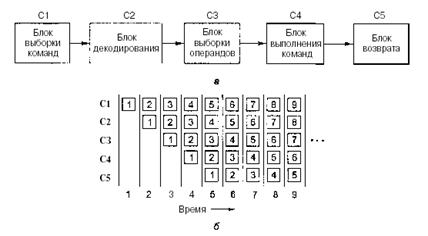
Рисунок
2.3 - Конвейер из 5 стадий (а); состояние каждой стадии в зависимости от
количества пройденных циклов (б). Показано 9 циклов
На
рис. 2.3, б мы видим, как действует конвейер во времени. Во время цикла 1 стадия
С1 работает над командой 1, вызывая ее из памяти. Во время цикла 2 стадия С2 декодирует
команду 1, в то время как стадия С1 вызывает из памяти команду 2. Во время
цикла 3 стадия СЗ вызывает операнды для команды 1, стадия С2 декодирует команду
2, а стадия С1 вызывает третью команду. Во время цикла 4 стадия С4 выполняет
команду 1, СЗ вызывает операнды для команды 2, С2 декодирует команду 3, а С1
вызывает команду 4. Наконец, во время пятого цикла С5 записывает результат
выполнения команды 1 обратно в регистр, тогда как другие стадии работают над
следующими командами.
Конвейеры
позволяют найти компромисс между временем ожидания (сколько времени занимает
выполнение одной команды) и пропускной способностью процессора (сколько
миллионов команд в секунду выполняет процессор). Если время цикла составляет Т
не, а конвейер содержит n
стадий, то время ожидания составит nТ не, а пропускная способность — 1000/Т млн команд в секунду.
2.6.2 Суперскалярные архитектуры
Один
конвейер — хорошо, а два — еще лучше. Одна из возможных схем процессора с
двойным конвейером показана на рис. 2.4. В основе разработки лежит конвейер,
изображенный на рис. 2.3. Здесь общий отдел вызова команд берет из памяти сразу
по две команды и помешает каждую из них в один из конвейеров. Каждый конвейер
содержит АЛУ для параллельных операций. Чтобы выполняться параллельно, две команды
не должны конфликтовать при использовании ресурсов (например, регистров), и ни
одна из них не должна зависеть от результата выполнения другой. Как и в случае
с одним конвейером, либо компилятор должен следить, чтобы не возникало
неприятных ситуаций (например, когда аппаратное обеспечение выдает некорректные
результаты, если команды несовместимы), либо же конфликты выявляются и
устраняются прямо во время выполнения команд благодаря использованию
дополнительного аппаратного обеспечения.
Сначала
конвейеры (как двойные, так и одинарные) использовались только в компьютерах
RISC. У 386-го и его предшественников их не было. Конвейеры в процессорах
компании Intel появились только начиная с 486-й модели1.486-й процессор
содержал один конвейер, a Pentium — два конвейера из пяти стадий. Похожая схема
изображена на рис. 2.4, но разделение функций между второй и третьей стадиями
(они назывались декодирование 1 и декодирование 2) было немного другим. Главный
конвейер (u-конвейер) мог выполнять произвольные команды. Второй конвейер (v-конвейер)
мог выполнять только простые команды с целымичислами, а также одну простую
команду с плавающей точкой (FXCH).
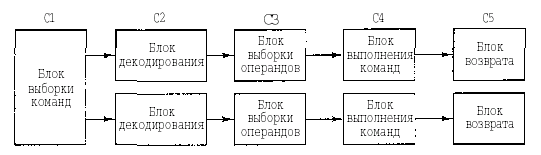
Рисунок
2.4 - Двойной конвейер из пяти стадий с общим отделом вызова команд
Имеются
сложные правила определения, является ли пара команд совместимой для того,
чтобы выполняться параллельно. Если команды, входящие в пару, были сложными или
несовместимыми, выполнялась только одна из них (в и-конвейере). Оставшаяся
вторая команда составляла затем пару со следующей командой. Команды всегда
выполнялись по порядку. Таким образом, Pentium содержал особые компиляторы,
которые объединяли совместимые команды в пары и могли порождать программы,
выполняющиеся быстрее, чем в предыдущих версиях. Измерения показали, что
программы, производящие операции с целыми числами, на компьютере Pentium
выполняются почти в два раза быстрее, чем на 486-м, хотя у него такая же
тактовая частота. Вне всяких сомнений, преимущество в скорости появилось
благодаря второму конвейеру.
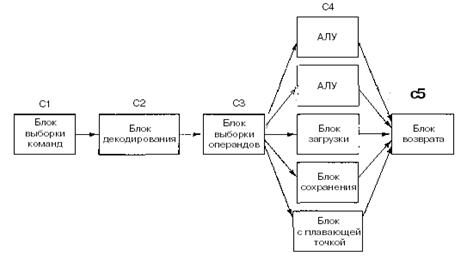
Рисунок
2.5 - Суперскалярный процессор с пятью функциональными блоками
Переход
к четырем конвейерам возможен, но это потребовало бы создания громоздкого
аппаратного обеспечения. Вместо этого используется другой подход. Основная идея
один конвейер с большим количеством функциональных блоков, как показано па
рис. 2.5. Pentium II, к примеру, имеет сходную структуру. В 1987 году для
обозначения этого подхода был введен термин суперскалярная архитектура. Однако
подобная идея нашла воплощение еще более 30 лет назад в компьютере CDC 6600.
CDC 6600 вызывал команду из памяти каждые 100 не и помещал ее в один из 10
функциональных блоков для параллельного выполнения. Пока команды выполнялись,
центральный процессор вызывал следующую команду.
Стадия
3 выпускает команды значительно быстрее, чем стадия 4 способна их выполнять.
Если бы стадия 3 выпускала команду каждые 10 не, а все функциональные блоки
выполняли бы свою работу также за 10 не, то на четвертой стадии всегда
функционировал бы только один блок, что сделало бы саму идею конвейера
бессмысленной. В действительности большинству функциональных блоков четвертой
стадии для выполнения команды требуется значительно больше времени, чем
занимает один цикл (это блоки доступа к памяти и блок выполнения операций с
плавающей точкой). Как видно из рис. 2 5, на четвертой стадии может быть
несколько АЛУ.
2.7 Параллелизм на уровне процессоров
Спрос
на компьютеры, работающие все с более и более высокой скоростью, не
прекращается. Астрономы хотят выяснить, что произошло в первую микросекунду после
большого взрыва, экономисты хотят смоделировать всю мировую экономику,
подростки хотят играть в 3D интерактивные игры со своими виртуальными друзьями
через Интернет. Скорость работы процессоров повышается, но у них постоянно
возникают проблемы с быстротой передачи информации, поскольку скорость
распространения электромагнитных волн в медных проводах и света в
оптико-волоконных кабелях по-прежнему остается 20 см/нс, независимо от того, насколько
умны инженеры компании Intel. Кроме того, чем быстрее работает процессор, тем
сильнее он нагревается, и нужно предохранять его от перегрева.
Параллелизм
на уровне команд помогает в какой-то степени, но конвейеры и суперскалярная
архитектура обычно увеличивают скорость работы всего лишь в 5-10 раз. Чтобы
улучшить производительность в 50, 100 и более раз, нужно разрабатывать
компьютеры с несколькими процессорами.
2.7.1 Векторные компьютеры
Многие
задачи в физических и технических науках содержат векторы, в противном случае
они имели бы очень сложную структуру. Часто одни и те же вычисления выполняются
над разными наборами данных в одно и то же время. Структура этих программ
позволяет повышать скорость работы благодаря параллельному выполнению команд.
Существует два метода, которые используются для быстрого выполнения больших
научных программ. Хотя обе схемы во многих отношениях схожи, одна из них
считается расширением одного процессора, а другая — параллельным компьютером.
Массивно-параллельный
процессор (array processor) состоит из большого числа сходных процессоров, которые выполняют одну и
ту же последовательность команд применительно к разным наборам данных. Первым в
мире таким процессором был ILLIAC IV (Университет Иллинойса). Он изображен на
рис. 2.6. Первоначально предполагалось сконструировать машину, состоящую из
четырех секторов, каждый из которых содержит решетку 8x8 элементов
процессор/память. Для каждого сектора имелся один блок контроля. Он рассылал
команды, которые выполнялись всеми процессорами одновременно, при этом каждый
процессор использовал свои собственные данные из своей собственной памяти
(загрузка данных происходила во время инициализации). Из-за очень высокой
стоимости был построен только один такой сектор, но он мог выполнять 50 млн
операций с плавающей точкой в секунду. Если бы при создании машины
использовалось четыре сектора и она могла бы выполнять 1 млрд операций с
плавающей точкой в секунду, то мощность такой машины в два раза превышала бы
мощность компьютеров всего мира.
Рисунок
2.6 -
Массивно-параллельный процессор ILLIAC IV
Для
программистов векторный процессор (vector processor) очень похож на массивно-параллельный
процессор (array processor). Как и массивно-параллельный процессор, он очень
эффективен при выполнении последовательности операций над парами элементов
данных. Но, в отличие от первого (array processor), все операции сложения
выполняются в одном блоке суммирования, который имеет конвейерную структуру.
Компания Cray Research, основателем которой был Сеймур Крей, выпустила много
векторных процессоров, начиная с модели Cray-1 (1974) и по сей день. Cray
Research в настоящее время входит в состав SGI.
Оба
типа процессоров работают с массивами данных. Оба они выполняют одни и те же
команды, которые, например, попарно складывают элементы для двух векторов. Но
если у массивно-параллельного процессора (array processor) есть столько же
суммирующих устройств, сколько элементов в массиве, векторный процессор (vector
processor) содержит векторный регистр, который состоит из набора стандартных
регистров. Эти регистры последовательно загружаются из памяти при помощи одной
команды. Команда сложения попарно складывает элементы двух таких векторов,
загружая их из двух векторных регистров в суммирующее устройство с конвейерной
структурой. В результате из суммирующего устройства выходит другой вектор,
который или помещается в векторный регистр, или сразу используется в качестве
операнда при выполнении другой операции с векторами.
Массивно-параллельные
процессоры (array processor) выпускаются до сих пор, но занимают незначительную
сферу компьютерного рынка, поскольку они эффективны при решении только таких задач,
которые требуют одновременного выполнения одних и тех же вычислений над разными
наборами данных. Массивно-параллельные процессоры (array processor) могут
выполнять некоторые операции гораздо быстрее, чем векторные компьютеры (vector
computer), но они требуют большего количества аппаратного обеспечения, и для
них сложно писать программы. Векторный процессор (vector processor), с другой
стороны, можно добавлять к обычному процессору. В результате те части
программы, которые могут быть преобразованы в векторную форму, выполняются
векторным блоком, а остальная часть программы — обычным процессором.
2.7.2 Мультипроцессоры
Элементы
массивно-параллельного процессора связаны между собой, поскольку их работу
контролирует один блок управления. Система нескольких параллельных процессоров,
разделяющих общую память, называется мультипроцессором. Поскольку каждый
процессор может записывать или считывать информацию из любой части памяти, их
работа должна согласовываться программным обеспечением, чтобы не допустить каких-либо
пересечений.
Возможны
разные способы воплощения этой идеи. Самый простой из них — наличие одной шины,
соединяющей несколько процессоров и одну общую память. Схема такого
мультипроцессора показана на рис. 2.7а. Такие системы производят многие компании.
Нетрудно
понять, что при наличии большого числа быстро работающих процессоров, которые
постоянно пытаются получить доступ к памяти через одну и ту же шину, будут
возникать конфликты. Чтобы разрешить эту проблему и повысить производительность
компьютера, были разработаны различные модели. Одна из них изображена на рис.
2.7б. В таком компьютере каждый процессор имеет свою собственную локальную
память, которая недоступна для других процессоров. Эта память используется для
программ и данных, которые не нужно разделять между несколькими процессорами.
При доступе к локальной памяти главная шина не используется, и, таким образом,
поток информации в этой шине снижается. Возможны и другие варианты решения
проблемы (например, кэш-память).
Рис.
2.7. Мультипроцессор с одной шиной и одной общей памятью (а); мультипроцессор,в
котором для каждого процессора имеется собственная локальная память (б)
Мультипроцессоры
имеют преимущество перед другими видами параллельных компьютеров, поскольку с
единой разделенной памятью очень легко работать. Например, представим, что
программа ищет раковые клетки на сделанном через микроскоп снимке ткани.
Фотография в цифровом виде может храниться в общей памяти, при этом каждый
процессор обследует какую-нибудь определенную область фотографии. Поскольку
каждый процессор имеет доступ к общей памяти, обследование клетки, которая
начинается в одной области и продолжается в другой, не представляет трудностей.
2.7.3 Мультикомпьютеры
Мультипроцессоры
с небольшим числом процессоров (< 64) сконструировать довольно легко, а вот
создание больших мультипроцессоров представляет некоторые трудности. Сложность
заключается в том, чтобы связать все процессоры с памятью. Чтобы избежать таких
проблем, многие разработчики просто отказались от идеи разделенной памяти и
стали создавать системы, состоящие из большого числа взаимосвязанных
компьютеров, у каждого из которых имеется своя собственная память, а общей
памяти нет. Такие системы называются мультикомпьютерами.
Процессоры
мультикомпьютера отправляют друг другу послания (это несколько похоже на
электронную почту, но гораздо быстрее). Каждый компьютер не обязательно
связывать со всеми другими, поэтому обычно в качестве топологий используются 2D,
3D, деревья и кольца. Чтобы послания могли дойти до места назначения, они должны
проходить через один или несколько промежуточных компьютеров. Тем не менее
время передачи занимает всего несколько микросекунд. Сейчас создаются и
запускаются в работу мультикомпьютеры, содержащие около 10 000 процессоров.
Поскольку
мультипроцессоры легче программировать, а мультикомпьютеры — конструировать,
появилась идея создания гибридных систем, которые сочетают в себе преимущества
обоих видов машин. Такие компьютеры представляют иллюзию разделенной памяти,
при этом в действительности она не конструируется и не требует особых денежных
затрат.
3 ЭВОЛЮЦИЯ МИКРОПРОЦЕССОРНЫХ СИСТЕМ
3.1
Основные направления развития
Несмотря
на то, что сегодня известно множество способов повышения производительности
микропроцессоров с суперскалярной архитектурой, имеется также ряд препятствий и
ограничений, исключающих возможность дальнейшего наращивания быстродействия. В
данной главе показаны способы повышения производительности суперскалярных
микропроцессоров на примере архитектур Alpha 21364 и Power4. Разбираются
вопросы перехода к принципиально новой, так называемой мультитредовой
архитектуре, позволяющей существенно изменить возможности нынешних
микропроцессоров.
История
развития микропроцессоров в полной мере подчиняется диалектике эволюционного
усовершенствования архитектуры. Начиная от машины ENIAC, содержавшей 19 тыс.
ламп, производительность компьютеров росла на порядок каждые пять лет. Большое
число транзисторов на современном кристалле делает возможным применить в одном
микропроцессоре все известные способы повышения производительности, сообразуясь
только с их совместимостью. Однако для полного использования возможностей
аппаратуры уже недостаточно ограничиться только аппаратно реализованными
алгоритмами управления, достаточно единообразно функционирующими во всех
ситуациях. Поэтому при реализации усложненной логики управления используется
программное обеспечение, для поддержки которого вводятся дополнительные команды
и регистры управления микропроцессора. В свою очередь, формирование программ
для потактного управления микропроцессором под силу только компилятору. Таким
образом, в современных микропроцессорах возник симбиоз программных и аппаратных
средств. Этот симбиоз представляет собой нечто большее, нежели эволюционный ход
развития, а смену самого направления развития микропроцессоров, выражающуюся в
переходе к мультитредовым и многопроцессорным архитектурам.
С позиции
реализации такого симбиоза открываются следующие способы повышения
производительности:
1)
увеличение
емкости памяти внутри кристалла;
2)
увеличение
количества арифметико-логических устройств;
3)
введение блоков
обработки мультимедийных данных, ранее использовавшихся, например, в сигнальных
микропроцессорах;
4)
интеграция на
кристалле функций управления памятью и периферийными устройствами, для
исполнения которых в традиционных микропроцессорах используются наборы
микросхем («чипсеты»);
5)
интеграция на
кристалле интерфейсов сетевых и телекоммуникационных систем, что позволяет
соединять эти микропроцессоры друг с другом и телекоммуникационными и
вычислительными сетями без дополнительных адаптеров.
3.2 Увеличение объема
внутрикристальной памяти
3.2.1 Организация
внутрикристальной памяти
Современное
состояние микроэлектроники характеризуется растущим разрывом между скоростью
обработки данных в микропроцессорах и быстродействием внекристальной
оперативной памяти. Можно уже говорить о том, что время выполнения однотактной
команды микропроцессора на порядок и более меньше времени доступа к памяти вне
кристалла. В таких условиях прибегают к построению многоуровневой иерархической
памяти с использованием внутрикристальной кэш-памяти и применению
мультитредовой архитектуры МТА, в которой задержка доступа в память в одном процессе
«скрывается» за временем выполнения других процессов.
Кроме того,
для уменьшения разрыва в быстродействии между процессором и памятью существует
технология встроенной памяти DRAM, позволяющая в едином производственном цикле
формировать на одном кристалле логические схемы и схемы динамической памяти.
Следует отметить, что идея создания однокристального компьютера всегда была
популярной, и сегодня проблема размещения на одном кристалле встраиваемого
блока памяти EDRAM (embedded DRAM) достаточно большой емкости и
микропроцессорного ядра близка к своему решению
3.2.2 Кэш-память
с несколькими уровнями
Постоянный
рост емкости кэш-памяти микропроцессора сопровождался усложнением процесса
управления, что вылилось в переход от кэш-памяти со сквозной записью к
кэш-памяти с буферизированной и обратной записями. При этом в микропроцессорах
использовалось программное управление режимом записи кэш-строк путем установки
бита, переключающего режимы сквозной и обратной записи кэш-строки. Однако в
случае промаха в кэш-памяти возрастающий разрыв между временем выполнения
команды и временем доступа в память привел к недопустимо большим потерям
производительности. Поэтому в микропроцессоры были введены команды управления
кэшированием. Например, в Pentium III появились команды нового типа,
обеспечивающие: запись данных из регистров в память, минуя кэш; чтение данных
из памяти в регистры, минуя кэш; запись данных из памяти выборочно в кэш
первого и второго уровня; запись данных из кэш-памяти и буферов записи в
память.
Команды
упреждающего кэширования позволяют заранее загружать в кэш нужные данные,
обеспечивая возможность записи данных в кэш-память различных уровней, что
уменьшает задержки, связанные с доступом к основной памяти. Команды записи
данных из кэш-памяти и буферов записи позволяют поддерживать когерентность
кэш-памяти и основной памяти при выполнении, например, команд упреждающего
кэширования. Однако вряд ли прагматично требовать управления кэш-памятью при
программировании на языках высокого уровня – распределение памяти всегда было
одной из функций компилятора. Тем более логично потребовать чтобы компилятор
выполнял управление кэш-памятью, сокращая простои процессора в ожидании данных.
3.2.3 Наборы
регистров в мультитредовой архитектуре
Другой, по
сравнению с организацией кэш-памяти, метод построения внутрикристальной памяти
применяется в мультитредовой архитектуре, основная особенность которой
использование совокупности регистровых файлов. Эта архитектура решает проблему
разрыва между скоростью обработки в процессоре и временем доступа в основную
память за счет переключения в каждом такте процессора на работу с очередным
регистровым файлом. Каждый регистровый файл обслуживает один вычислительный
процесс – тред (поток). Всего в каждом процессоре имеется n регистровых файлов,
поэтому запрос, выданный в основную память каждым из потоков, может
обслуживаться в течение n-1 такта, вплоть до момента, когда процессор снова
переключится на тот же регистровый файл. Выбор значения n определяется
отношением времени доступа в память ко времени выполнения команды процессором.
Конечно, задача формирования потоков из последовательной программы должна, по
возможности, решаться компилятором. В противном случае будущее этой архитектуры
окажется ограниченным узкой проблемной ориентацией.
Компания Tera
объявила о разработке проекта мультитредового микропроцессора, реализующего
процессор МТА. Level One, приобретенная Intel, выпустила мультитредовый сетевой
микропроцессор IXP1200, содержащий в своем составе 6 четырехтредовых
процессоров. IBM анонсировала проект компьютера Blue Gene, кристалл
микропроцессора которого включает 32 восьмитредовых процессора. В кристалл
встроена память EDRAM, организованная в 32 блока. Каждый блок соответствует
одному из 32 процессоров и имеет шину доступа 256 разрядов. Поскольку EDRAM
обладает высокой пропускной способностью и малой задержкой, то при
восьмитредовой структуре процессора становится возможным отказаться от
кэш-памяти, вместо которой между процессором и памятью используется небольшая
буферная память.
3.3 Увеличение числа и состава
функциональных устройств
3.3.1 Увеличение
числа функциональных устройств
Память
ресурс, непосредственно не производящий вычислений. Увеличение емкости памяти
на кристалле дает прирост производительности, но после достижения некоторой
величины этот прирост оказывается существенно меньше, чем обеспечиваемый
использованием того же ресурса транзисторов кристалла для построения
дополнительной совокупности функциональных устройств. Основное препятствие на
пути повышения производительности за счет увеличения числа функциональных
устройств – это организация загрузки этих устройств полезной работой, которую
можно проводить динамически путем исследования программного кода на стадии
исполнения и статически на уровне компиляции программ. Первый подход
используется в суперскалярных микропроцессорах, второй – в микропроцессорах с
длинным командным словом.
Весьма
привлекательно выглядит намерение возложить на компилятор выявление команд,
допускающих параллельное исполнение на разных функциональных устройствах.
Однако существуют проблемы, которые нельзя решить на уровне компиляции. Поэтому
наряду со статическим распараллеливанием компилятором на уровне команд должны
развиваться аппаратные реализации методов динамического внеочередного исполнения
команд микропроцессоров.
Во время
компиляции трудно, а иногда и невозможно установить длительность исполнения
отдельных команд, в связи с тем, что возникают промахи при обращении к
кэш-памяти, арифметические переполнения, формирование недопустимых адресов и
другие исключительные ситуации. Кроме того, определение зависимости между
командами записи в память и чтения из памяти может быть выполнено только после
вычисления адресных выражений, что возможно лишь в ходе исполнения программы.
Команды, выбранные на исполнение, могут следовать друг за другом в неизменном
порядке, определяемом при их выборке из памяти, либо их порядок может
изменяться, позволяя исполнять команды, для которых готовы операнды.
Внеочередное исполнение команд предполагает следующие механизмы:
-
переименование
регистров с целью устранения ресурсных зависимостей «запись после чтения» и
«запись после записи»;
-
предсказание
переходов;
-
динамическое
назначение команд на исполнительные устройства, включая изменение порядка
исполнения по сравнению с порядком, в котором эти команды были извлечены.
Динамическое
назначение команд на исполнительные устройства реализуется резервирующей
станцией, состоящей из совокупности элементов ассоциативной памяти. Каждый из
элементов содержит позиции для размещения кода операции, наименования первого
операнда, его значения, признака доступности первого операнда, наименования
второго операнда, его значения, признака доступности второго операнда и
наименования регистра результата. Когда команда завершает исполнение и
вырабатывает результат, то наименование результата сравнивается с
наименованиями операндов в резервирующей станции. Если в резервирующей станции
обнаруживается команда, ждущая этого результата, то данные записываются в
соответствующую позицию и устанавливается признак их доступности. Когда у
команды доступны все операнды, инициируется ее исполнение. Резервирующая
станция следит за доступностью операндов и при получении команды все готовые
операнды из регистрового файла переписываются в поля этой команды. Когда все
операнды готовы, команда исполняется.
Процесс
функционирования процессора с внеочередным исполнением команд иллюстрирует рис.
3.1:
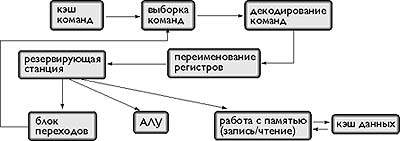
Рисунок 3.1 -
Процесс функционирования процессора с внеочередным исполнением команд
3.3.2 Мультимедийные
расширения
Многие
производители расширяют сегодня функциональные возможности выпускаемых микропроцессоров
за счет введения специализированных блоков для мультимедийных приложений.
Подобный блок имелся уже в микропроцессоре второго поколения Intel 80860, и на
некоторых приложениях его использование давало существенный прирост
производительности. Аналогичные блоки включены и в другие микропроцессоры Intel
(ММХ-расширение системы команд Pentium и 70 новых SIMD-команд Pentium III), AMD
(3D Now!), Sun (VIS SPARC), Compaq (Alpha MVI), HP (PA-RISC MAX2), SGI/Mips
(MDMX), Motorola (PowerPC AltiVec).
Возможны различные
варианты встраивания команд мультимедийной обработки в систему команд
микропроцессора: на уровне функционального блока, использующего общий с другими
блоками файл регистров (Pentium MMX) или на уровне отдельного процессора со
своим регистровым файлом, используя разнесенную (decoupled) архитектуру.
Последний вариант применен в Pentium III и PowerPC AltiVec.
Команды
мультимедийной обработки задают в режиме SIMD-процессора параллельную обработку
нескольких единиц данных, представленных, как правило, малоразрядными (8, 16,
32) числами в формате с фиксированной точкой. Однако это не исчерпывает всех
текущих потребностей и, например, в Pentium III введена параллельная обработка
в режиме SIMD-процессора четырех 32-разрядных операндов в формате с плавающей точкой.
3.4 Интеграция функций
3.4.1 Системы
на одном кристалле
С ростом
количества транзисторов на кристалле стало возможно построение микросхем, в
которых микропроцессор вместе с памятью на кристалле выступает в роли одного из
составных элементов (ядер) систем на одном кристалле (SOC — system on chip). В
кристалле интегрируются функции, для исполнения которых обычно используются
наборы микросхем, сетевые платы и другие специализированные микросхемы. Это, с
одной стороны, позволяет существенно увеличить пропускную способность между
компонентами кристалла по сравнению с пропускной способностью между разными
кристаллами, реализующими по отдельности каждую функцию. И, как следствие,
поднять производительность систем. С другой стороны, при уменьшении количества
кристаллов резко упрощается изготовление и монтаж плат, что ведет к повышению
надежности и снижению стоимости систем.
В кристалл
интегрируются интерфейсы сетевых и телекоммуникационных систем, что позволяет
без дополнительных адаптеров соединять микропроцессоры друг с другом, с
телекоммуникационными и вычислительными сетями. Интеграция коммуникационных
интерфейсов в кристалл микропроцессора была впервые проделана в транспьютерах.
Однако это были упрощенные интерфейсы, позволяющие связываться лишь с другими
транспьютерами. В процессорах Motorola MPC8260 поддерживается уже множество
телекоммуникационных протоколов, включающих, например, 10/100 Mбит/с Ethernet,
155 Mбит/с ATM, 256 каналов 64 Кбит/с HDLC. Компания Motorola предлагает два
семейства кристаллов, в которых в качестве ядра используется PowerPC 603e – это
семейство на основе технологий AltiVec и PowerQUICC.
3.4.2 Системы
с распределенной разделяемой памятью
Ориентация
разработчиков на создание систем с распределенной разделяемой памятью привела к
интеграции в кристалл блока управления когерентностью многоуровневой памяти на
кристалле и распределенной внешней памяти, доступ к блокам которой выполняется
через интегрированную в тот же кристалл коммуникационную среду. В качестве
примеров этого подхода можно назвать микропроцессоры Alpha 21364, Power4, а
также Blue Gene. В качестве ядра у микропроцессора Alpha 21364 используется
Alpha 21264, но на кристалле интегрированы: шестивходовый частично
ассоциативный кэш второго уровня емкостью 1,5 Мбайт; контроллер памяти,
поддерживающий работу с динамической памятью Direct Rambus; сетевой интерфейс.
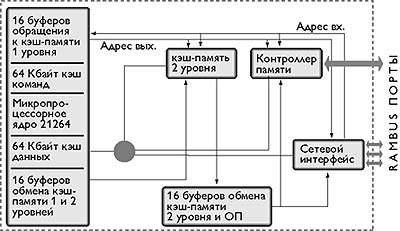
Рисунок 3.2 -
Архитектура микропроцессора Alpha 21364
Для
динамического исполнения в микропроцессоре Alpha 21364 (рис.3.2)
рассматриваются сразу 80 команд – больше, чем у любого другого процессора.
После декодирования команда помещается в очередь к устройствам с фиксированной
или плавающей точкой. Команды, получившие все операнды, конкурируют за доступ к
функциональным устройствам: двум блокам операций с плавающей точкой,
выполняющим сложение, умножение, деление, извлечение квадратного корня и
четырем целочисленным устройствам (двум общего назначения и двум адресной
арифметики). Последние наряду с простыми арифметическими и логическими
операциями выполняют все команды загрузки и сохранения как целочисленных
данных, так и данных в формате с плавающей точкой. Целочисленные АЛУ общего
назначения выполняют арифметические и логические операции, сдвиги и переходы.
Одно из целочисленных АЛУ выполняет также умножение, а другое – новый набор
команд обработки видеоданных. Для динамического переименования доступны 41 из 80
целочисленных регистров и 41 из 72 регистров с плавающей точкой.
Обмен данными
между кэшами первого и второго уровня, кэшем первого уровня и оперативной
памятью буферизирован (по 16 буферов для каждого уровня памяти).
Интеграция
компонентов в одном кристалле позволяет существенно упростить и удешевить
системы, реализуемые на основе данного микропроцессора. Благодаря встроенному
сетевому интерфейсу упрощается объединение микропроцессоров в
высокопроизводительные многопроцессорные системы. Сетевой интерфейс поддерживает
4 межпроцессорных соединения типа «точка-точка» со скоростью передачи данных 10
Гбайт/с каждый при задержке 15 нс. Сетевой интерфейс обеспечивает когерентность
кэшей в многопроцессорной системе и реализует асинхронный обмен данными с
адаптивной маршрутизацией. Пример структуры многопроцессорной системы на основе
микропроцессоров Alpha 21364 показан на рис. 3.3:
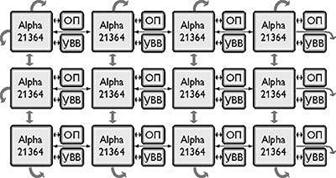
Рисунок 3.3 -
Пример структуры многопроцессорной системы
Микропроцессор
имеет пятый порт – ввода-вывода, работающий на скорости обмена 3 Гбайт/с.
Процессоры
Alpha 21364 и Power4 объединяет общность архитектурных решений: суперскалярная
микроархитектура, внеочередное исполнение команд, большая кэш-память на
кристалле, специализированный порт для основной памяти, а также
высокоскоростные линки для объединения микропроцессоров в системы с
архитектурой NUMA с распределенной разделяемой памятью (distributed shared
memory — DSM).
Каждый
процессор Power4 (рис. 3.4) подобен Power3 и имеет два конвейерных блока для
работы с 64-разрядными операндами с плавающей точкой на частоте 1 ГГц,
выбирающих на исполнение по 5 команд каждый и 2 блока для работы с памятью. В
процессорах реализуется внеочередное исполнение команд. Микропроцессор
реализован на кристалле, содержащем 170 млн. транзисторов. Для достижения
тактовой частоты 1,1 ГГц стадии конвейеров имеют задержку 8-10 вентилей.
Процессоры
содержат раздельные кэш-памяти команд и данных первого уровня емкостью по 64
Кбайт каждая. Кроме того, имеется разделяемая (общая) кэш-память на кристалле
второго уровня и внешняя кэш-память третьего уровня. Для образования
мультипроцессорных конфигураций имеются 3 линка с суммарной пропускной
способностью 45 Гбайт/с.
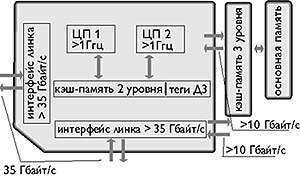
Рисунок 3.4 -
Архитектура Power4
Наряду с
параллелизмом уровня команд (ILP), процессор использует параллелизм уровня
тредов (TLP). Динамическое выявление параллелизма позволяет предотвращать
простои процессора при трудно выявляемых статически исключительных ситуациях,
например, промахе в кэш-памяти. Power4 изготавливается по 0,18-микронной
технологии SOI («кремний на изоляторе») с медными проводниками и 5 слоями
металла на кристалле площадью 400 мм2.
Отличительная
особенность Power4 – наличие кэш-памяти второго уровня, разделяемой двумя процессорами
кристалла, а также внешними процессорами других кристаллов через линки шириной
16 байт, работающие на тактовой частоте более 500 МГц, что обеспечивает
пропускную способность свыше 8 Гбайт/с. Суммарная пропускная способность 4
линков составляет более 35 Гбайт/с. При объединении 4 кристаллов и их размещении,
как показано на рис. 3.5, проводники линков могут быть достаточно короткими и,
что важно, прямыми.
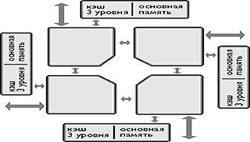
Рисунок 3.5 -
Пример объединения Power4 в фрагмент многопроцессорной системы
Физически
кэш-память второго уровня емкостью около 1,5 Мбайт состоит из трех одинаковых
блоков, доступ к которым выполняется через коммутатор с пропускной способностью
на уровне 100 Гбайт/с. Протокол когерентности обеспечивает размещение данных,
поступивших по линкам, в том блоке кэш-памяти, который использовался для
размещения данных последним.
Порт
кристалла Power4, предназначенный для подключения кэш-памяти третьего уровня
емкостью до 32 Мбайт имеет ширину 16 байт для каждого из двух направлений
пересылки данных. Порт функционирует на 1/3 от тактовой частоты процессоров
кристалла, что обеспечивает пропускную способность к памяти на уровне 10
Гбайт/с. Теги кэш-памяти третьего уровня расположены внутри кристалла, что
ускоряет реализацию протокола когерентности. Для работы с основной памятью
может быть использована восьмипоточная программная предвыборка данных непосредственно
в кэш-память первого уровня на кристалле. Пересылать можно одновременно до 20
строк кэша.
Каждый из
двух процессоров Power4 имеет систему команд IBM ISA, реализованную в RS/6000 и
AS/400 и полностью совместимую с системой команд Power PC. Сохранение системы
команд, вызванное поддержкой двоичного кода пользователей, потребовало
применения как однотактных команд, так и микропрограмм и даже прерываний для
программной реализации наиболее сложных команд ISA.
3.5 Однокристальные мультитредовые
и мультискалярные системы
Современные
микропроцессоры, например, Alpha 21264 и Pentium III, относятся к однотредовым,
использующим параллелизм уровня команд, выявляемый либо статически
(компилятором), либо динамически (аппаратурой микропроцессора), либо комбинацией
этих двух методов. Параллелизм уровня тредов при использовании этих
микропроцессоров может быть выявлен только статически. Динамическое выявление
параллелизма уровня тредов в рамках архитектур однотредовых процессоров
практически невозможно, так как требует просмотра большого количества команд на
предмет их одновременного исполнения – расширения окна исполнения. Это влечет
за собой усложнение логических схем управления внеочередным исполнением команд,
что может привести к снижению тактовой частоты микропроцессора. Для разрешения
данного противоречия предлагаются мультитредовые и мультискалярные
микропроцессоры.
3.5.1 Основы
мультитредовой архитектуры
При всем
различии подходов к созданию мультитредовых микропроцессоров, общим для них
является введение множества устройств выборки команд, каждое из которых
организует окно исполнения для одного треда. В рамках одного треда выполняется
предсказание переходов, переименование регистров, динамическая подготовка
команд к исполнению. Тем самым, общее число команд, находящихся в обработке,
значительно превышает размер окна исполнения однотредового процессора, с одной
стороны, и тактовая частота не лимитируется размером окна исполнения, с другой
стороны.
Выявление
тредов может выполняться компилятором при анализе исходного кода на языке
высокого уровня или исполняемого кода программы. Однако компиляторы не всегда
могут разрешить проблемы зависимостей при использовании регистров и ячеек
памяти между тредами, что требуется уже в ходе исполнения тредов. Для этого в микропроцессор
вводится специальная аппаратура условного исполнения тредов, предусматривающая
возврат с отбрасыванием наработанных результатов при обнаружении нарушения
зависимостей между тредами. Нарушением зависимости, например, может служить
запись по вычисляемому адресу в одном треде в ту же ячейку памяти, из которой
выполняется чтение, которое должно следовать за этой записью, в другом треде. В
случае, если адреса записи и чтения не совпадают, нарушение отсутствует. При
совпадении адресов фиксируется нарушение, которое должно вернуть исполнение
треда к команде чтения правильного значения.
Интерфейс
между аппаратурой мультитредового процессора, поддерживающей протекание каждого
отдельного треда и аппаратурой, общей для исполнения всех тредов, может быть установлен
как сразу после устройств выборки команд тредов, так и на уровне доступа к
разделяемой памяти. В первом случае все треды используют один регистровый файл
и один набор функциональных устройств. Тесная связь по ресурсам позволяет
эффективно исполнять последовательные программы с сильной зависимостью между
тредами. В этом случае имеет место именно реализация мультискалярного
мультитредового процессора.
Во втором
случае для исполнения каждого треда, фактически, выделяется функционально
законченный процессор. В целом эта структура ориентирована на исполнение
независимых и слабо связанных тредов, порождаемых либо одной программой, либо
их совокупностью. В этом случае скорее надо говорить не о процессоре, а о
системе на одном кристалле. Возможно также промежуточное расположение
интерфейса, соответствующее аппаратным средствам, ориентированным на реализацию
определенного типа совокупности тредов.
По оценкам,
при обработке транзакций мультитредовый микропроцессор Alpha 21464 будет в
десять раз производительнее, чем Alpha 21264.
3.5.2 Развитие систем на одном кристалле
Среди
тенденций, ведущих к появлению многопроцессорных систем на одном кристалле,
можно отметить следующие:
1) Перенос на стадию компиляции решения
проблем извлечения из последовательных программ команд, допускающих
параллельное исполнение, и, в целом, ветвей параллельных программ. Если
суперскалярный микропроцессор сам выделяет параллельно выполняемые команды, то
уже в мультискалярном микропроцессоре на компилятор возлагаются дополнительные
функции по выделению параллельных ветвей, а микропроцессоры с длинным командным
словом возлагают на компилятор все проблемы загрузки параллельно
функционирующих устройств. В этих условиях задача создания распараллеливающего
компилятора для многопроцессорной системы не выглядит неразрешимой;
2) Объем оборудования, обеспечивающего
загрузку функциональных устройств, микропроцессоров с суперскалярной и
мультискалярной архитектурами достаточно велик и имеет квадратичный рост в
зависимости от числа находящихся в обработке команд. При увеличении числа
функциональных устройств должно увеличиваться и число выбираемых на исполнение
команд, что приведет к возрастанию объема оборудования, не производящего
непосредственно обработки данных. Суммарный объем схем управления в многопроцессорной
системе, состоящей из простых процессоров, может быть существенно меньше, чем в
микропроцессоре с суперскалярной или мультискалярной архитектурой при одном и
том же суммарном числе функциональных устройств или, иными словами, при одинаковой
производительности в случае полной загрузки устройств. Следует также отметить,
что простые процессоры мультипроцессорной системы могут иметь более высокую
тактовую частоту;
3) Многопроцессорная система, в силу
присущей ей избыточности, способна функционировать при отказе части
оборудования. Такие отказы могут быть как изначально присутствующими,
вследствие дефектов кремниевой пластины или технологического процесса
изготовления, так и появившимися в ходе функционирования. Многопроцессорные
системы могут создаваться либо как однокристальные, либо как многокристальные
микросборки. Реальность такова, что однокорпусная микросборка многопроцессорной
системы из совокупности простых микропроцессоров может значительно превышать по
показателю «производительность/стоимость» однокристальную систему, размер
кристалла которой равен сумме площадей кристаллов микросборки. Микросборки не
отличаются от СБИС. Выбор однокристальной реализации или микросборки
определяется достигаемыми технико-экономическими показателями, например,
использование микросборок памяти. Возможности подобной технологии демонстрирует
микропроцессор Pentium Pro. Однако среди наиболее интересных проектов,
концентрирующих архитектурные и технологические достижения, включая
однокристальные системы и микросборки, можно назвать микропроцессор Power4;
4) В традиционных компьютерах,
состоящих из микропроцессора и микросхем памяти, использующих в совокупности
порядка 108 транзисторов в микропроцессоре и 109 транзисторов в памяти, в
каждом такте задействовано по разным оценкам 104 – 105 транзисторов. Иначе
говоря, имеет место простой значительной части оборудования, потенциально
способного производить полезную работу. Конечно, при использовании
КМОП-технологии простои имеют и определенный плюс: оборудование выделяет мало
тепловой энергии. При существующих на сегодня конструкциях корпусов микросхем
проблема теплоотвода может стать решающей при выборе архитектуры кристалла.
Однако на кристалле может быть достаточно эффективно реализована
многопроцессорная система из большого числа процессоров, каждый из которых
имеет собственную небольшую встроенную память. Подобные вычислительные
структуры обычно называют ассоциативными процессорами, памятью с обработкой,
многофункциональной памятью или интеллектуальной памятью. К этому классу
относятся однокристальные системы как с SIMD-архитектурой, например, Fuzion
150, так и с MIMD-архитектурой, например, Blue Gene.
3.6 Направление эволюции архитектур
микропроцессоров
Мультитредовые
микропроцессоры и системы на одном кристалле вбирают в себя накопленные в ходе
эволюции приемы повышения производительности микропроцессоров и используют
симбиоз компиляторов и аппаратуры, соответственно для статического и
динамического выявления параллелизма из исходных последовательных программ. Ориентация
на исполнение совокупности тредов с определенной степенью межтредовых
зависимостей обусловливает конкретные решения по совместному использованию
тредами регистрового файла, аппаратуры внеочередного исполнения команд и
функциональных устройств. Предстоят еще значительные исследования по
оптимизации мультитредовых архитектур. Однако последовательность шагов в этом
направлении эволюции микропроцессоров уже известна – это Alpha 21364 и Alpha
21464.
ВЫВОДЫ
В данной научной работе
был произведён анализ существующих подходов к классификации архитектур
вычислительных систем, рассмотрены такие эффективные методы повышения
производительности вычислительных систем, как параллельные вычисления и
мультитрединг.
Работа
рассчитана на продолжение исследований в этом направлении, целью которых
является создание программного обеспечения формирования фазы определения для
заданной системы команд.
Сама
разработка вышеупомянутого программного обеспечения будет осуществляться в
последующем при написании дипломного проекта, где и будут использованы
результаты научно-исследовательской работы.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
1. Таненбаум Э. Архитектура
компьютера, 4-е изд. – Спб.: Питер, 2003. – 700 с.;
2. М. Кузьминский, «Открытые системы», 1999, № 5-6, стр. 8;
3. М. Кузьминский, «Отрытые системы», 1999, № 9-10, стр. 8;
4. Головкин Б.А. Параллельные вычислительные системы. М.:
Наука. 1980. 520 с.;
5. Методические
указания по оформлению студенческих работ для студентов специальностей 7.080403
"Программное обеспечение автоматизированных систем" и 7.080404
"Интеллектуальные системы принятия решений" / Утв. Л.А. Белозерский и
др. – Донецк: ДонГИИИ, 2001. – 52 с.
|



